 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Minor Edits Matter: LLM-Driven Prompt Attack for Medical VLM Robustness in Ultrasound
Mar 22, 2026Ultrasound is widely used in clinical practice due to its portability, cost-effectiveness, safety, and real-time imaging capabilities. However, image acquisition and interpretation remain highly operator dependent, motivating the development of robust AI-assisted analysis methods. Vision-language models (VLMs) have recently demonstrated strong multimodal reasoning capabilities and competitive performance in medical image analysis, including ultrasound. However, emerging evidence highlights significant concerns about their trustworthiness. In particular, adversarial robustness is critical because Med-VLMs operate via natural-language instructions, rendering prompt formulation a realistic and practically exploitable point of vulnerability. Small variations (typos, shorthand, underspecified requests, or ambiguous wording) can meaningfully shift model outputs. We propose a scalable adversarial evaluation framework that leverages a large language model (LLM) to generate clinically plausible adversarial prompt variants via "humanized" rewrites and minimal edits that mimic routine clinical communication. Using ultrasound multiple-choice question answering benchmarks, we systematically assess the vulnerability of SOTA Med-VLMs to these attacks, examine how attacker LLM capacity influences attack success, analyze the relationship between attack success and model confidence, and identify consistent failure patterns across models. Our results highlight realistic robustness gaps that must be addressed for safe clinical translation. Code will be released publicly following the review process.
StreamSplat: Towards Online Dynamic 3D Reconstruction from Uncalibrated Video Streams
Jun 10, 2025Real-time reconstruction of dynamic 3D scenes from uncalibrated video streams is crucial for numerous real-world applications. However, existing methods struggle to jointly address three key challenges: 1) processing uncalibrated inputs in real time, 2) accurately modeling dynamic scene evolution, and 3) maintaining long-term stability and computational efficiency. To this end, we introduce StreamSplat, the first fully feed-forward framework that transforms uncalibrated video streams of arbitrary length into dynamic 3D Gaussian Splatting (3DGS) representations in an online manner, capable of recovering scene dynamics from temporally local observations. We propose two key technical innovations: a probabilistic sampling mechanism in the static encoder for 3DGS position prediction, and a bidirectional deformation field in the dynamic decoder that enables robust and efficient dynamic modeling. Extensive experiments on static and dynamic benchmarks demonstrate that StreamSplat consistently outperforms prior works in both reconstruction quality and dynamic scene modeling, while uniquely supporting online reconstruction of arbitrarily long video streams. Code and models are available at https://github.com/nickwzk/StreamSplat.
MoFlow: One-Step Flow Matching for Human Trajectory Forecasting via Implicit Maximum Likelihood Estimation based Distillation
Mar 13, 2025In this paper, we address the problem of human trajectory forecasting, which aims to predict the inherently multi-modal future movements of humans based on their past trajectories and other contextual cues. We propose a novel motion prediction conditional flow matching model, termed MoFlow, to predict K-shot future trajectories for all agents in a given scene. We design a novel flow matching loss function that not only ensures at least one of the $K$ sets of future trajectories is accurate but also encourages all $K$ sets of future trajectories to be diverse and plausible. Furthermore, by leveraging the implicit maximum likelihood estimation (IMLE), we propose a novel distillation method for flow models that only requires samples from the teacher model. Extensive experiments on the real-world datasets, including SportVU NBA games, ETH-UCY, and SDD, demonstrate that both our teacher flow model and the IMLE-distilled student model achieve state-of-the-art performance. These models can generate diverse trajectories that are physically and socially plausible. Moreover, our one-step student model is $\textbf{100}$ times faster than the teacher flow model during sampling. The code, model, and data are available at our project page: https://moflow-imle.github.io
SimMark: A Robust Sentence-Level Similarity-Based Watermarking Algorithm for Large Language Models
Feb 05, 2025



The rapid proliferation of large language models (LLMs) has created an urgent need for reliable methods to detect whether a text is generated by such models. In this paper, we propose SimMark, a posthoc watermarking algorithm that makes LLMs' outputs traceable without requiring access to the model's internal logits, enabling compatibility with a wide range of LLMs, including API-only models. By leveraging the similarity of semantic sentence embeddings and rejection sampling to impose detectable statistical patterns imperceptible to humans, and employing a soft counting mechanism, SimMark achieves robustness against paraphrasing attacks. Experimental results demonstrate that SimMark sets a new benchmark for robust watermarking of LLM-generated content, surpassing prior sentence-level watermarking techniques in robustness, sampling efficiency, and applicability across diverse domains, all while preserving the text quality.
Fréchet Video Motion Distance: A Metric for Evaluating Motion Consistency in Videos
Jul 23, 2024
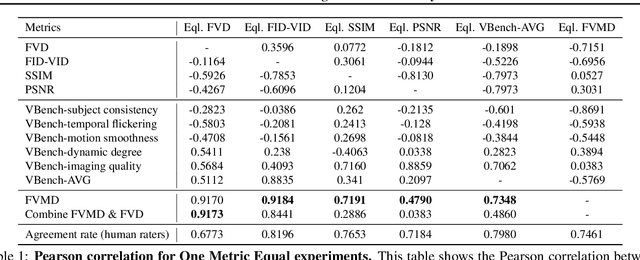
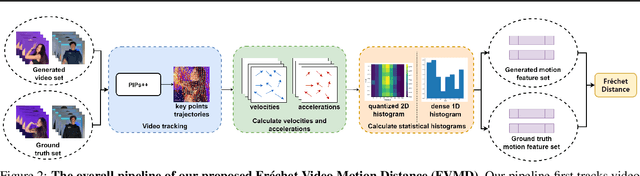
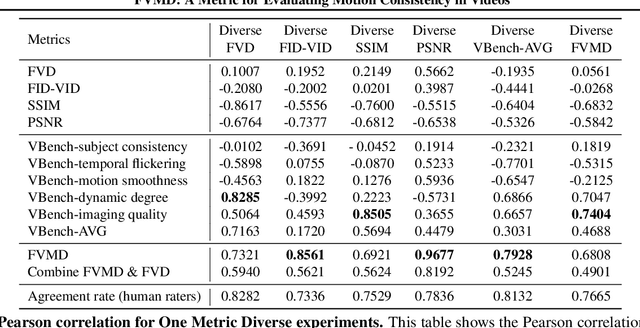
Significant advancements have been made in video generative models recently. Unlike image generation, video generation presents greater challenges, requiring not only generating high-quality frames but also ensuring temporal consistency across these frames. Despite the impressive progress, research on metrics for evaluating the quality of generated videos, especially concerning temporal and motion consistency, remains underexplored. To bridge this research gap, we propose Fr\'echet Video Motion Distance (FVMD) metric, which focuses on evaluating motion consistency in video generation. Specifically, we design explicit motion features based on key point tracking, and then measure the similarity between these features via the Fr\'echet distance. We conduct sensitivity analysis by injecting noise into real videos to verify the effectiveness of FVMD. Further, we carry out a large-scale human study, demonstrating that our metric effectively detects temporal noise and aligns better with human perceptions of generated video quality than existing metrics. Additionally, our motion features can consistently improve the performance of Video Quality Assessment (VQA) models, indicating that our approach is also applicable to unary video quality evaluation. Code is available at https://github.com/ljh0v0/FMD-frechet-motion-distance.
BCAmirs at SemEval-2024 Task 4: Beyond Words: A Multimodal and Multilingual Exploration of Persuasion in Memes
Apr 03, 2024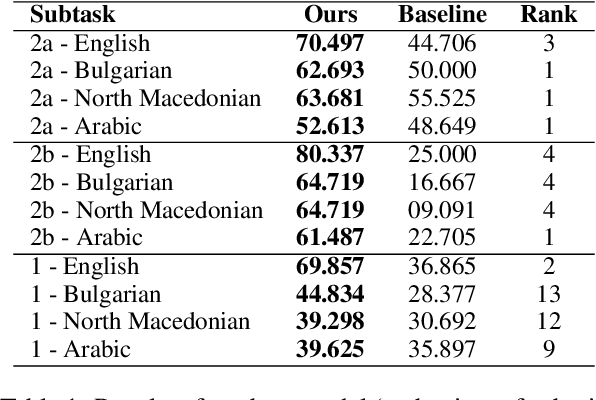

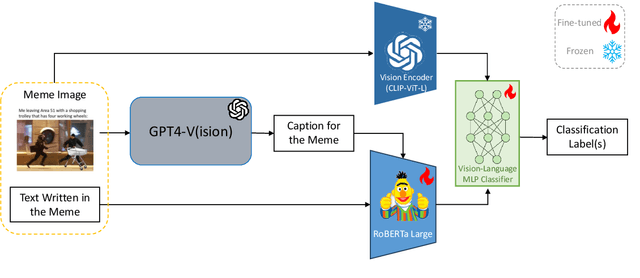
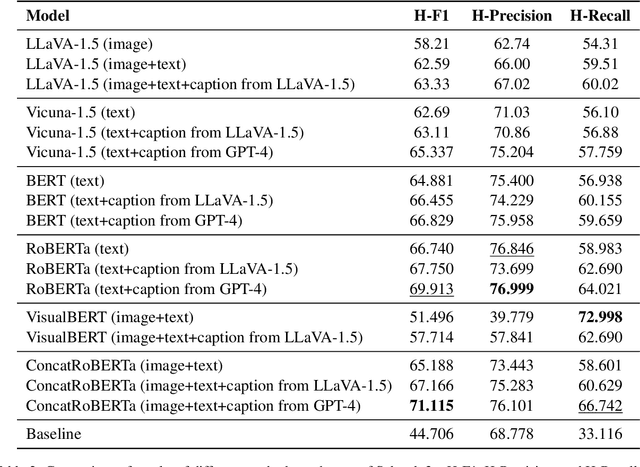
Memes, combining text and images, frequently use metaphors to convey persuasive messages, shaping public opinion. Motivated by this, our team engaged in SemEval-2024 Task 4, a hierarchical multi-label classification task designed to identify rhetorical and psychological persuasion techniques embedded within memes. To tackle this problem, we introduced a caption generation step to assess the modality gap and the impact of additional semantic information from images, which improved our result. Our best model utilizes GPT-4 generated captions alongside meme text to fine-tune RoBERTa as the text encoder and CLIP as the image encoder. It outperforms the baseline by a large margin in all 12 subtasks. In particular, it ranked in top-3 across all languages in Subtask 2a, and top-4 in Subtask 2b, demonstrating quantitatively strong performance. The improvement achieved by the introduced intermediate step is likely attributable to the metaphorical essence of images that challenges visual encoders. This highlights the potential for improving abstract visual semantics encoding.
An Information-Theoretic Framework for Out-of-Distribution Generalization
Mar 29, 2024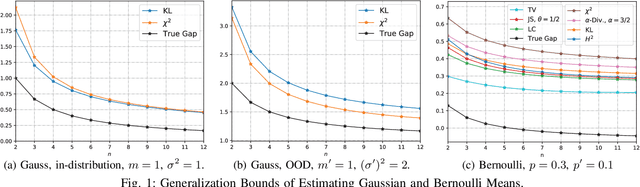
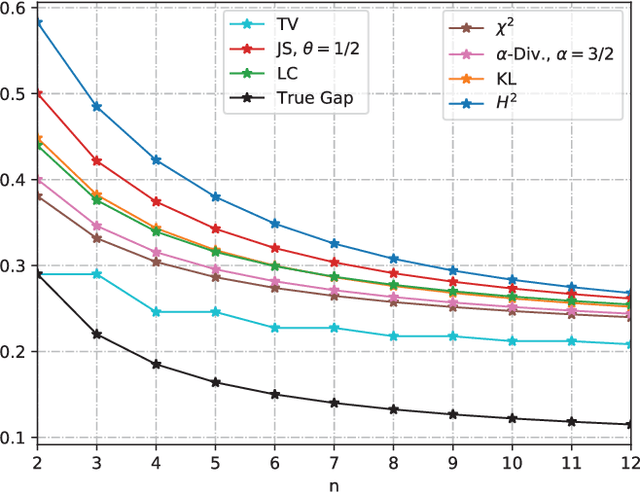
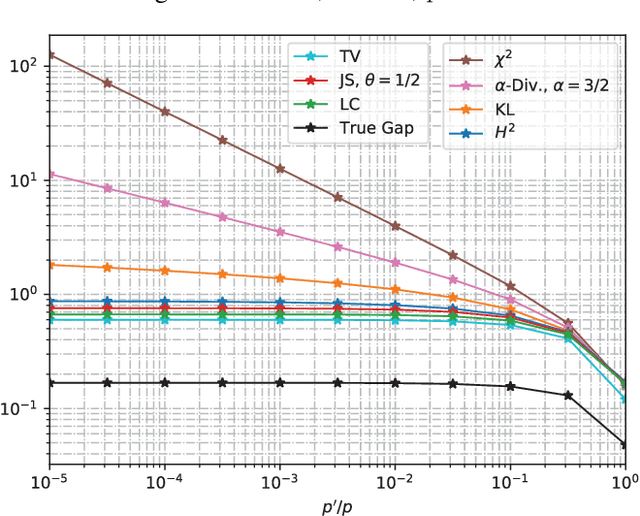

We study the Out-of-Distribution (OOD) generalization in machine learning and propose a general framework that provides information-theoretic generalization bounds. Our framework interpolates freely between Integral Probability Metric (IPM) and $f$-divergence, which naturally recovers some known results (including Wasserstein- and KL-bounds), as well as yields new generalization bounds. Moreover, we show that our framework admits an optimal transport interpretation. When evaluated in two concrete examples, the proposed bounds either strictly improve upon existing bounds in some cases or recover the best among existing OOD generalization bounds.
Joint Generative Modeling of Scene Graphs and Images via Diffusion Models
Jan 02, 2024


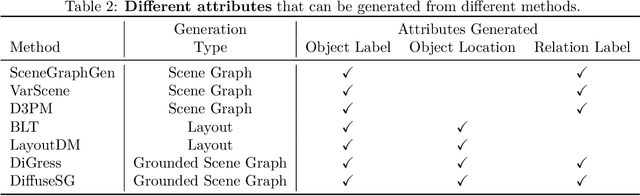
In this paper, we present a novel generative task: joint scene graph - image generation. While previous works have explored image generation conditioned on scene graphs or layouts, our task is distinctive and important as it involves generating scene graphs themselves unconditionally from noise, enabling efficient and interpretable control for image generation. Our task is challenging, requiring the generation of plausible scene graphs with heterogeneous attributes for nodes (objects) and edges (relations among objects), including continuous object bounding boxes and discrete object and relation categories. We introduce a novel diffusion model, DiffuseSG, that jointly models the adjacency matrix along with heterogeneous node and edge attributes. We explore various types of encodings for the categorical data, relaxing it into a continuous space. With a graph transformer being the denoiser, DiffuseSG successively denoises the scene graph representation in a continuous space and discretizes the final representation to generate the clean scene graph. Additionally, we introduce an IoU regularization to enhance the empirical performance. Our model significantly outperforms existing methods in scene graph generation on the Visual Genome and COCO-Stuff datasets, both on standard and newly introduced metrics that better capture the problem complexity. Moreover, we demonstrate the additional benefits of our model in two downstream applications: 1) excelling in a series of scene graph completion tasks, and 2) improving scene graph detection models by using extra training samples generated from DiffuseSG.
Noisy Computing of the $\mathsf{OR}$ and $\mathsf{MAX}$ Functions
Sep 07, 2023We consider the problem of computing a function of $n$ variables using noisy queries, where each query is incorrect with some fixed and known probability $p \in (0,1/2)$. Specifically, we consider the computation of the $\mathsf{OR}$ function of $n$ bits (where queries correspond to noisy readings of the bits) and the $\mathsf{MAX}$ function of $n$ real numbers (where queries correspond to noisy pairwise comparisons). We show that an expected number of queries of \[ (1 \pm o(1)) \frac{n\log \frac{1}{\delta}}{D_{\mathsf{KL}}(p \| 1-p)} \] is both sufficient and necessary to compute both functions with a vanishing error probability $\delta = o(1)$, where $D_{\mathsf{KL}}(p \| 1-p)$ denotes the Kullback-Leibler divergence between $\mathsf{Bern}(p)$ and $\mathsf{Bern}(1-p)$ distributions. Compared to previous work, our results tighten the dependence on $p$ in both the upper and lower bounds for the two functions.
SwinGNN: Rethinking Permutation Invariance in Diffusion Models for Graph Generation
Jul 19, 2023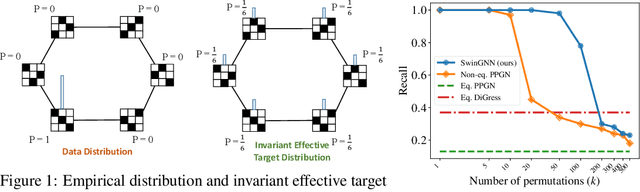
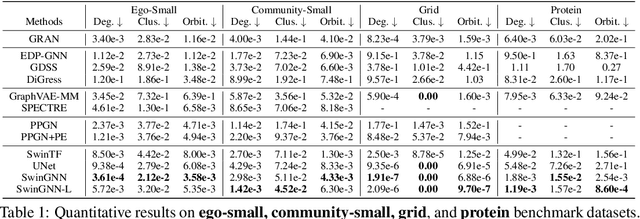
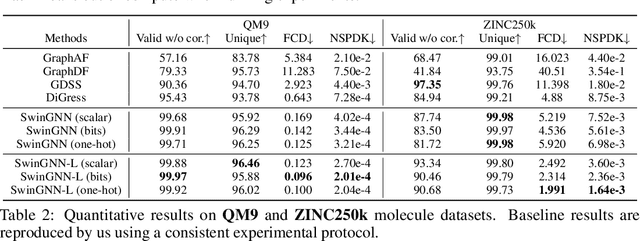
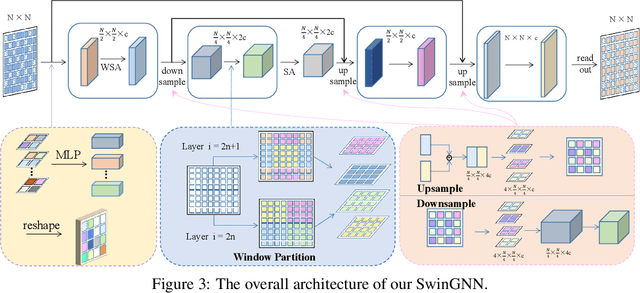
Diffusion models based on permutation-equivariant networks can learn permutation-invariant distributions for graph data. However, in comparison to their non-invariant counterparts, we have found that these invariant models encounter greater learning challenges since 1) their effective target distributions exhibit more modes; 2) their optimal one-step denoising scores are the score functions of Gaussian mixtures with more components. Motivated by this analysis, we propose a non-invariant diffusion model, called $\textit{SwinGNN}$, which employs an efficient edge-to-edge 2-WL message passing network and utilizes shifted window based self-attention inspired by SwinTransformers. Further, through systematic ablations, we identify several critical training and sampling techniques that significantly improve the sample quality of graph generation. At last, we introduce a simple post-processing trick, $\textit{i.e.}$, randomly permuting the generated graphs, which provably converts any graph generative model to a permutation-invariant one. Extensive experiments on synthetic and real-world protein and molecule datasets show that our SwinGNN achieves state-of-the-art performances. Our code is released at https://github.com/qiyan98/SwinGNN.