 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCCAM: Towards Cost-Efficient and Accuracy-Aware Image Classification Inference
Jun 06, 2024



Image classification is a fundamental building block for a majority of computer vision applications. With the growing popularity and capacity of machine learning models, people can easily access trained image classifiers as a service online or offline. However, model use comes with a cost and classifiers of higher capacity usually incur higher inference costs. To harness the respective strengths of different classifiers, we propose a principled approach, OCCAM, to compute the best classifier assignment strategy over image classification queries (termed as the optimal model portfolio) so that the aggregated accuracy is maximized, under user-specified cost budgets. Our approach uses an unbiased and low-variance accuracy estimator and effectively computes the optimal solution by solving an integer linear programming problem. On a variety of real-world datasets, OCCAM achieves 40% cost reduction with little to no accuracy drop.
Joint Generative Modeling of Scene Graphs and Images via Diffusion Models
Jan 02, 2024


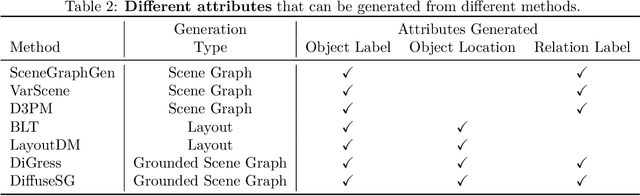
In this paper, we present a novel generative task: joint scene graph - image generation. While previous works have explored image generation conditioned on scene graphs or layouts, our task is distinctive and important as it involves generating scene graphs themselves unconditionally from noise, enabling efficient and interpretable control for image generation. Our task is challenging, requiring the generation of plausible scene graphs with heterogeneous attributes for nodes (objects) and edges (relations among objects), including continuous object bounding boxes and discrete object and relation categories. We introduce a novel diffusion model, DiffuseSG, that jointly models the adjacency matrix along with heterogeneous node and edge attributes. We explore various types of encodings for the categorical data, relaxing it into a continuous space. With a graph transformer being the denoiser, DiffuseSG successively denoises the scene graph representation in a continuous space and discretizes the final representation to generate the clean scene graph. Additionally, we introduce an IoU regularization to enhance the empirical performance. Our model significantly outperforms existing methods in scene graph generation on the Visual Genome and COCO-Stuff datasets, both on standard and newly introduced metrics that better capture the problem complexity. Moreover, we demonstrate the additional benefits of our model in two downstream applications: 1) excelling in a series of scene graph completion tasks, and 2) improving scene graph detection models by using extra training samples generated from DiffuseSG.
Self-Supervised Relation Alignment for Scene Graph Generation
Feb 02, 2023



The goal of scene graph generation is to predict a graph from an input image, where nodes correspond to identified and localized objects and edges to their corresponding interaction predicates. Existing methods are trained in a fully supervised manner and focus on message passing mechanisms, loss functions, and/or bias mitigation. In this work we introduce a simple-yet-effective self-supervised relational alignment regularization designed to improve the scene graph generation performance. The proposed alignment is general and can be combined with any existing scene graph generation framework, where it is trained alongside the original model's objective. The alignment is achieved through distillation, where an auxiliary relation prediction branch, that mirrors and shares parameters with the supervised counterpart, is designed. In the auxiliary branch, relational input features are partially masked prior to message passing and predicate prediction. The predictions for masked relations are then aligned with the supervised counterparts after the message passing. We illustrate the effectiveness of this self-supervised relational alignment in conjunction with two scene graph generation architectures, SGTR and Neural Motifs, and show that in both cases we achieve significantly improved performance.
Consistent Multiple Sequence Decoding
Apr 15, 2020
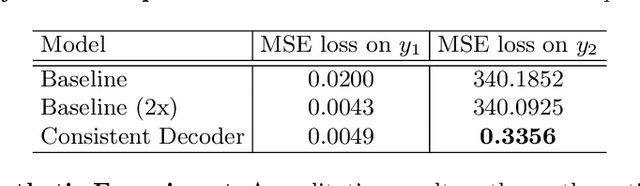
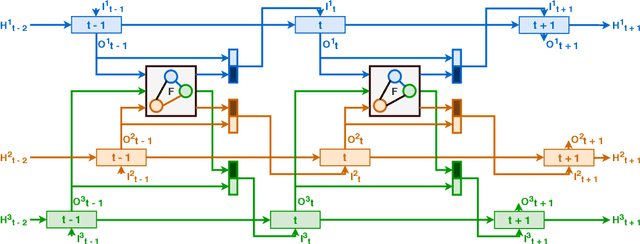

Sequence decoding is one of the core components of most visual-lingual models. However, typical neural decoders when faced with decoding multiple, possibly correlated, sequences of tokens resort to simple independent decoding schemes. In this paper, we introduce a consistent multiple sequence decoding architecture, which is while relatively simple, is general and allows for consistent and simultaneous decoding of an arbitrary number of sequences. Our formulation utilizes a consistency fusion mechanism, implemented using message passing in a Graph Neural Network (GNN), to aggregate context from related decoders. This context is then utilized as a secondary input, in addition to previously generated output, to make a prediction at a given step of decoding. Self-attention, in the GNN, is used to modulate the fusion mechanism locally at each node and each step in the decoding process. We show the efficacy of our consistent multiple sequence decoder on the task of dense relational image captioning and illustrate state-of-the-art performance (+ 5.2% in mAP) on the task. More importantly, we illustrate that the decoded sentences, for the same regions, are more consistent (improvement of 9.5%), while across images and regions maintain diversity.
Watch, Listen and Tell: Multi-modal Weakly Supervised Dense Event Captioning
Oct 25, 2019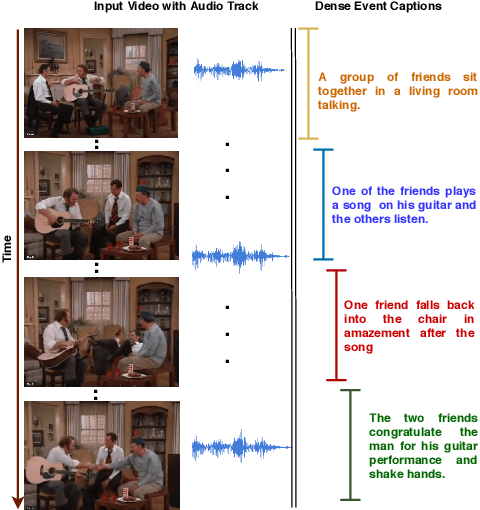
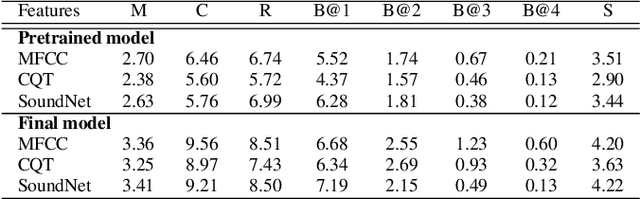
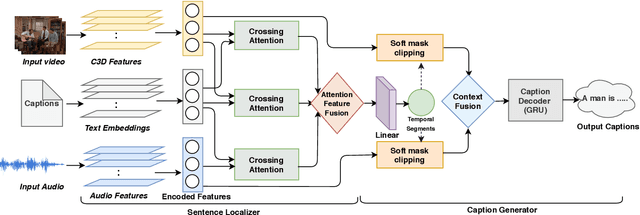
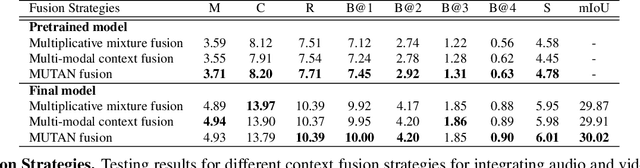
Multi-modal learning, particularly among imaging and linguistic modalities, has made amazing strides in many high-level fundamental visual understanding problems, ranging from language grounding to dense event captioning. However, much of the research has been limited to approaches that either do not take audio corresponding to video into account at all, or those that model the audio-visual correlations in service of sound or sound source localization. In this paper, we present the evidence, that audio signals can carry surprising amount of information when it comes to high-level visual-lingual tasks. Specifically, we focus on the problem of weakly-supervised dense event captioning in videos and show that audio on its own can nearly rival performance of a state-of-the-art visual model and, combined with video, can improve on the state-of-the-art performance. Extensive experiments on the ActivityNet Captions dataset show that our proposed multi-modal approach outperforms state-of-the-art unimodal methods, as well as validate specific feature representation and architecture design choices.
Time Perception Machine: Temporal Point Processes for the When, Where and What of Activity Prediction
Aug 14, 2018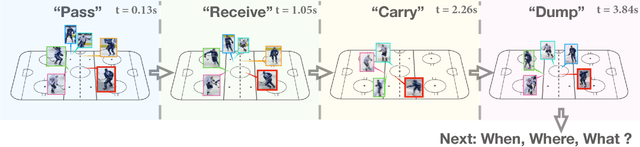
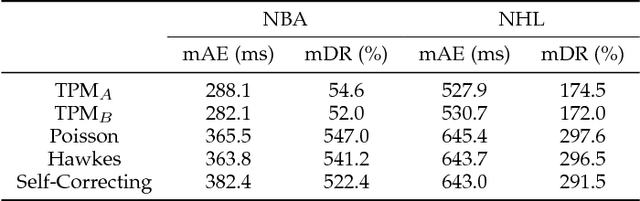
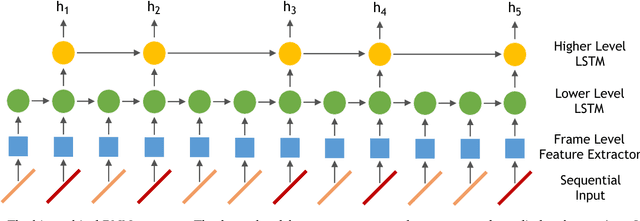
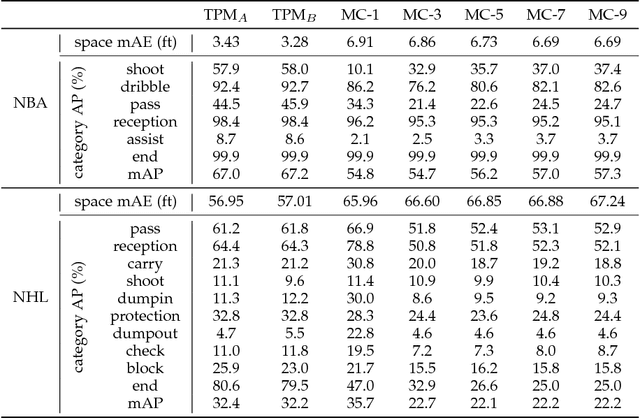
Numerous powerful point process models have been developed to understand temporal patterns in sequential data from fields such as health-care, electronic commerce, social networks, and natural disaster forecasting. In this paper, we develop novel models for learning the temporal distribution of human activities in streaming data (e.g., videos and person trajectories). We propose an integrated framework of neural networks and temporal point processes for predicting when the next activity will happen. Because point processes are limited to taking event frames as input, we propose a simple yet effective mechanism to extract features at frames of interest while also preserving the rich information in the remaining frames. We evaluate our model on two challenging datasets. The results show that our model outperforms traditional statistical point process approaches significantly, demonstrating its effectiveness in capturing the underlying temporal dynamics as well as the correlation within sequential activities. Furthermore, we also extend our model to a joint estimation framework for predicting the timing, spatial location, and category of the activity simultaneously, to answer the when, where, and what of activity prediction.