 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Portrait Matting via Regional Attention and Refinement
Nov 07, 2023We present a lightweight model for high resolution portrait matting. The model does not use any auxiliary inputs such as trimaps or background captures and achieves real time performance for HD videos and near real time for 4K. Our model is built upon a two-stage framework with a low resolution network for coarse alpha estimation followed by a refinement network for local region improvement. However, a naive implementation of the two-stage model suffers from poor matting quality if not utilizing any auxiliary inputs. We address the performance gap by leveraging the vision transformer (ViT) as the backbone of the low resolution network, motivated by the observation that the tokenization step of ViT can reduce spatial resolution while retain as much pixel information as possible. To inform local regions of the context, we propose a novel cross region attention (CRA) module in the refinement network to propagate the contextual information across the neighboring regions. We demonstrate that our method achieves superior results and outperforms other baselines on three benchmark datasets while only uses $1/20$ of the FLOPS compared to the existing state-of-the-art model.
Geometry Driven Progressive Warping for One-Shot Face Animation
Oct 05, 2022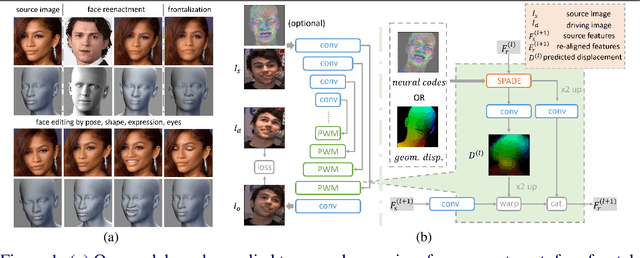
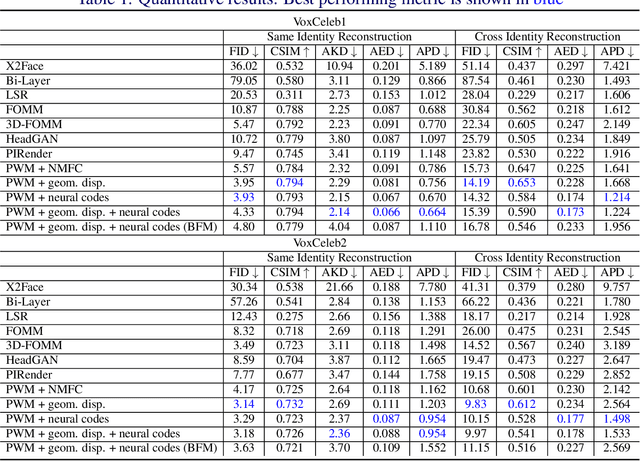
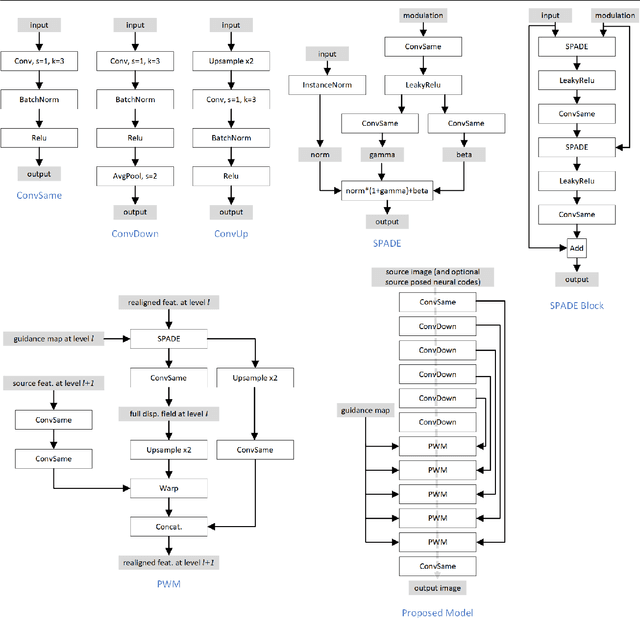
Face animation aims at creating photo-realistic portrait videos with animated poses and expressions. A common practice is to generate displacement fields that are used to warp pixels and features from source to target. However, prior attempts often produce sub-optimal displacements. In this work, we present a geometry driven model and propose two geometric patterns as guidance: 3D face rendered displacement maps and posed neural codes. The model can optionally use one of the patterns as guidance for displacement estimation. To model displacements at locations not covered by the face model (e.g., hair), we resort to source image features for contextual information and propose a progressive warping module that alternates between feature warping and displacement estimation at increasing resolutions. We show that the proposed model can synthesize portrait videos with high fidelity and achieve the new state-of-the-art results on the VoxCeleb1 and VoxCeleb2 datasets for both cross identity and same identity reconstruction.
Time Perception Machine: Temporal Point Processes for the When, Where and What of Activity Prediction
Aug 14, 2018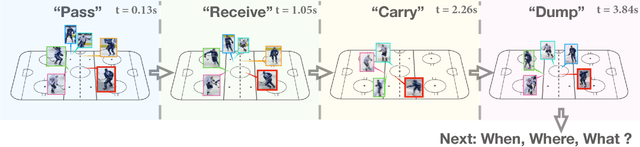
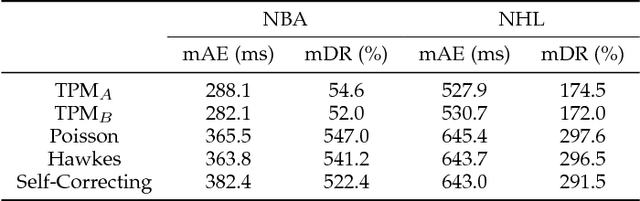
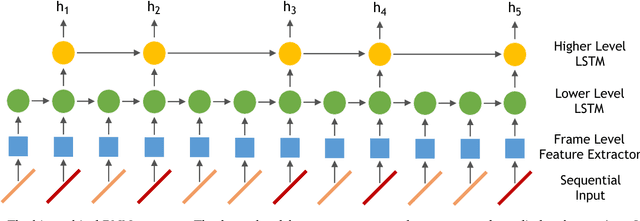
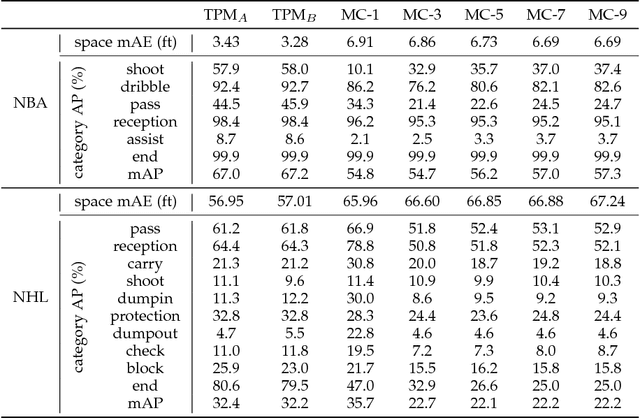
Numerous powerful point process models have been developed to understand temporal patterns in sequential data from fields such as health-care, electronic commerce, social networks, and natural disaster forecasting. In this paper, we develop novel models for learning the temporal distribution of human activities in streaming data (e.g., videos and person trajectories). We propose an integrated framework of neural networks and temporal point processes for predicting when the next activity will happen. Because point processes are limited to taking event frames as input, we propose a simple yet effective mechanism to extract features at frames of interest while also preserving the rich information in the remaining frames. We evaluate our model on two challenging datasets. The results show that our model outperforms traditional statistical point process approaches significantly, demonstrating its effectiveness in capturing the underlying temporal dynamics as well as the correlation within sequential activities. Furthermore, we also extend our model to a joint estimation framework for predicting the timing, spatial location, and category of the activity simultaneously, to answer the when, where, and what of activity prediction.
Learning Person Trajectory Representations for Team Activity Analysis
Jun 03, 2017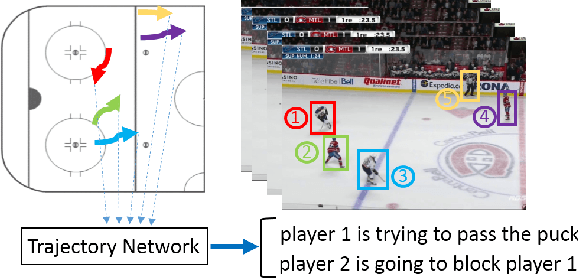
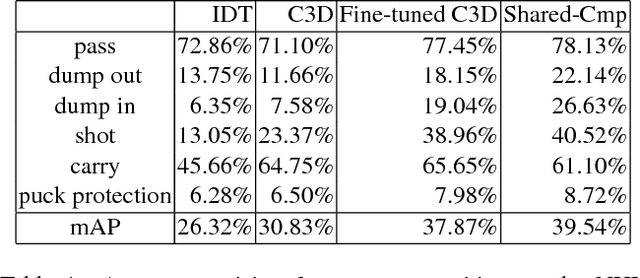

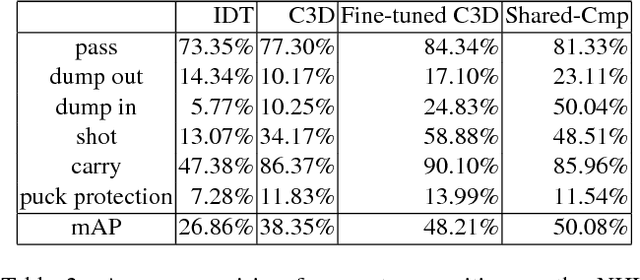
Activity analysis in which multiple people interact across a large space is challenging due to the interplay of individual actions and collective group dynamics. We propose an end-to-end approach for learning person trajectory representations for group activity analysis. The learned representations encode rich spatio-temporal dependencies and capture useful motion patterns for recognizing individual events, as well as characteristic group dynamics that can be used to identify groups from their trajectories alone. We develop our deep learning approach in the context of team sports, which provide well-defined sets of events (e.g. pass, shot) and groups of people (teams). Analysis of events and team formations using NHL hockey and NBA basketball datasets demonstrate the generality of our approach.