 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOFER: Occluded Face Expression Reconstruction
Oct 29, 2024Reconstructing 3D face models from a single image is an inherently ill-posed problem, which becomes even more challenging in the presence of occlusions. In addition to fewer available observations, occlusions introduce an extra source of ambiguity, where multiple reconstructions can be equally valid. Despite the ubiquity of the problem, very few methods address its multi-hypothesis nature. In this paper we introduce OFER, a novel approach for single image 3D face reconstruction that can generate plausible, diverse, and expressive 3D faces, even under strong occlusions. Specifically, we train two diffusion models to generate the shape and expression coefficients of a face parametric model, conditioned on the input image. This approach captures the multi-modal nature of the problem, generating a distribution of solutions as output. Although this addresses the ambiguity problem, the challenge remains to pick the best matching shape to ensure consistency across diverse expressions. To achieve this, we propose a novel ranking mechanism that sorts the outputs of the shape diffusion network based on the predicted shape accuracy scores to select the best match. We evaluate our method using standard benchmarks and introduce CO-545, a new protocol and dataset designed to assess the accuracy of expressive faces under occlusion. Our results show improved performance over occlusion-based methods, with added ability to generate multiple expressions for a given image.
Geometry Driven Progressive Warping for One-Shot Face Animation
Oct 05, 2022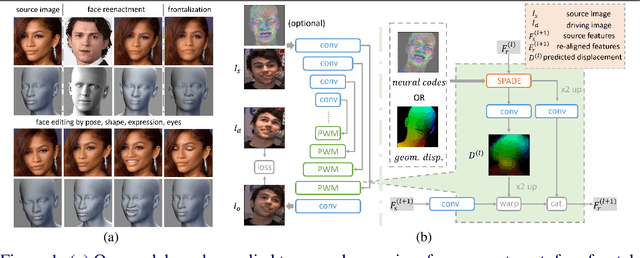
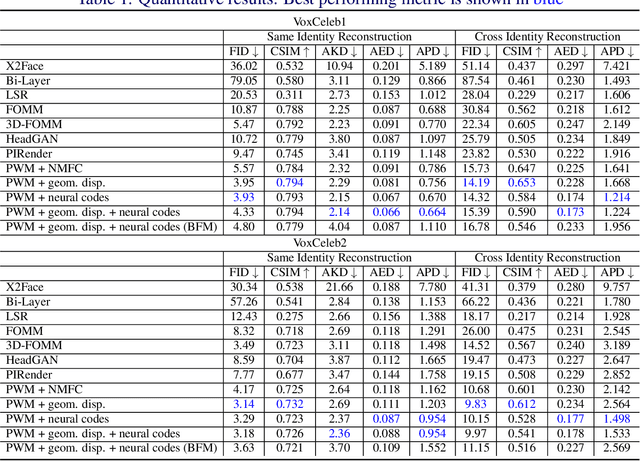
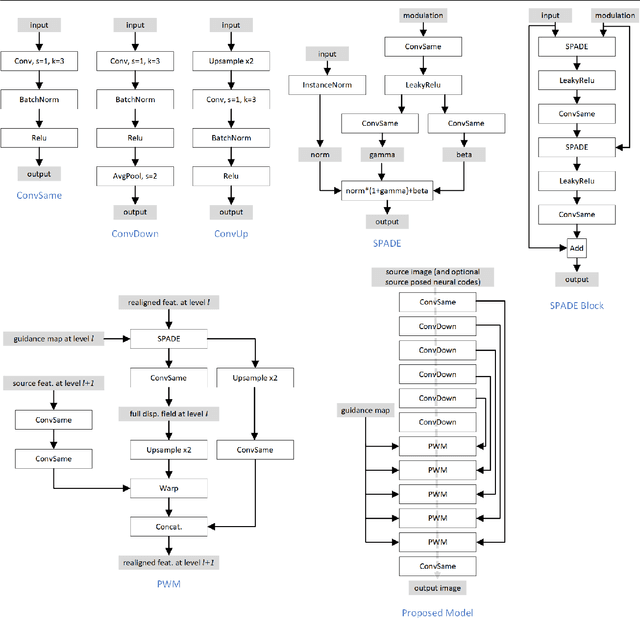
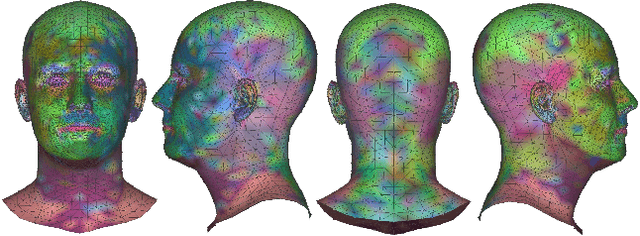
Face animation aims at creating photo-realistic portrait videos with animated poses and expressions. A common practice is to generate displacement fields that are used to warp pixels and features from source to target. However, prior attempts often produce sub-optimal displacements. In this work, we present a geometry driven model and propose two geometric patterns as guidance: 3D face rendered displacement maps and posed neural codes. The model can optionally use one of the patterns as guidance for displacement estimation. To model displacements at locations not covered by the face model (e.g., hair), we resort to source image features for contextual information and propose a progressive warping module that alternates between feature warping and displacement estimation at increasing resolutions. We show that the proposed model can synthesize portrait videos with high fidelity and achieve the new state-of-the-art results on the VoxCeleb1 and VoxCeleb2 datasets for both cross identity and same identity reconstruction.