 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNGL-Prompter: Training-Free Sewing Pattern Estimation from a Single Image
Feb 24, 2026Estimating sewing patterns from images is a practical approach for creating high-quality 3D garments. Due to the lack of real-world pattern-image paired data, prior approaches fine-tune large vision language models (VLMs) on synthetic garment datasets generated by randomly sampling from a parametric garment model GarmentCode. However, these methods often struggle to generalize to in-the-wild images, fail to capture real-world correlations between garment parts, and are typically restricted to single-layer outfits. In contrast, we observe that VLMs are effective at describing garments in natural language, yet perform poorly when asked to directly regress GarmentCode parameters from images. To bridge this gap, we propose NGL (Natural Garment Language), a novel intermediate language that restructures GarmentCode into a representation more understandable to language models. Leveraging this language, we introduce NGL-Prompter, a training-free pipeline that queries large VLMs to extract structured garment parameters, which are then deterministically mapped to valid GarmentCode. We evaluate our method on the Dress4D, CloSe and a newly collected dataset of approximately 5,000 in-the-wild fashion images. Our approach achieves state-of-the-art performance on standard geometry metrics and is strongly preferred in both human and GPT-based perceptual evaluations compared to existing baselines. Furthermore, NGL-prompter can recover multi-layer outfits whereas competing methods focus mostly on single-layer garments, highlighting its strong generalization to real-world images even with occluded parts. These results demonstrate that accurate sewing pattern reconstruction is possible without costly model training. Our code and data will be released for research use.
OFER: Occluded Face Expression Reconstruction
Oct 29, 2024Reconstructing 3D face models from a single image is an inherently ill-posed problem, which becomes even more challenging in the presence of occlusions. In addition to fewer available observations, occlusions introduce an extra source of ambiguity, where multiple reconstructions can be equally valid. Despite the ubiquity of the problem, very few methods address its multi-hypothesis nature. In this paper we introduce OFER, a novel approach for single image 3D face reconstruction that can generate plausible, diverse, and expressive 3D faces, even under strong occlusions. Specifically, we train two diffusion models to generate the shape and expression coefficients of a face parametric model, conditioned on the input image. This approach captures the multi-modal nature of the problem, generating a distribution of solutions as output. Although this addresses the ambiguity problem, the challenge remains to pick the best matching shape to ensure consistency across diverse expressions. To achieve this, we propose a novel ranking mechanism that sorts the outputs of the shape diffusion network based on the predicted shape accuracy scores to select the best match. We evaluate our method using standard benchmarks and introduce CO-545, a new protocol and dataset designed to assess the accuracy of expressive faces under occlusion. Our results show improved performance over occlusion-based methods, with added ability to generate multiple expressions for a given image.
FORA: Fast-Forward Caching in Diffusion Transformer Acceleration
Jul 01, 2024Diffusion transformers (DiT) have become the de facto choice for generating high-quality images and videos, largely due to their scalability, which enables the construction of larger models for enhanced performance. However, the increased size of these models leads to higher inference costs, making them less attractive for real-time applications. We present Fast-FORward CAching (FORA), a simple yet effective approach designed to accelerate DiT by exploiting the repetitive nature of the diffusion process. FORA implements a caching mechanism that stores and reuses intermediate outputs from the attention and MLP layers across denoising steps, thereby reducing computational overhead. This approach does not require model retraining and seamlessly integrates with existing transformer-based diffusion models. Experiments show that FORA can speed up diffusion transformers several times over while only minimally affecting performance metrics such as the IS Score and FID. By enabling faster processing with minimal trade-offs in quality, FORA represents a significant advancement in deploying diffusion transformers for real-time applications. Code will be made publicly available at: https://github.com/prathebaselva/FORA.
Developability Approximation for Neural Implicits through Rank Minimization
Aug 14, 2023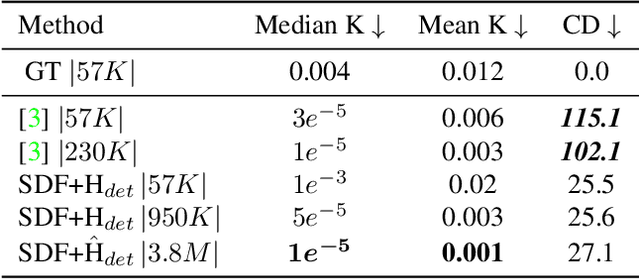

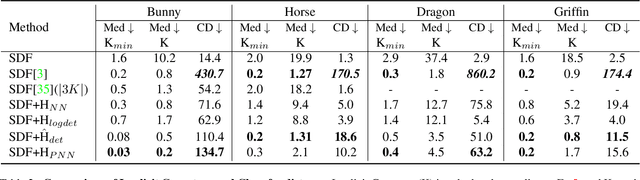
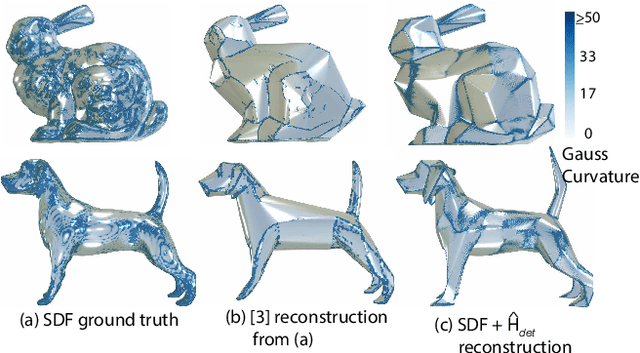
Developability refers to the process of creating a surface without any tearing or shearing from a two-dimensional plane. It finds practical applications in the fabrication industry. An essential characteristic of a developable 3D surface is its zero Gaussian curvature, which means that either one or both of the principal curvatures are zero. This paper introduces a method for reconstructing an approximate developable surface from a neural implicit surface. The central idea of our method involves incorporating a regularization term that operates on the second-order derivatives of the neural implicits, effectively promoting zero Gaussian curvature. Implicit surfaces offer the advantage of smoother deformation with infinite resolution, overcoming the high polygonal constraints of state-of-the-art methods using discrete representations. We draw inspiration from the properties of surface curvature and employ rank minimization techniques derived from compressed sensing. Experimental results on both developable and non-developable surfaces, including those affected by noise, validate the generalizability of our method.
BuildingNet: Learning to Label 3D Buildings
Oct 11, 2021

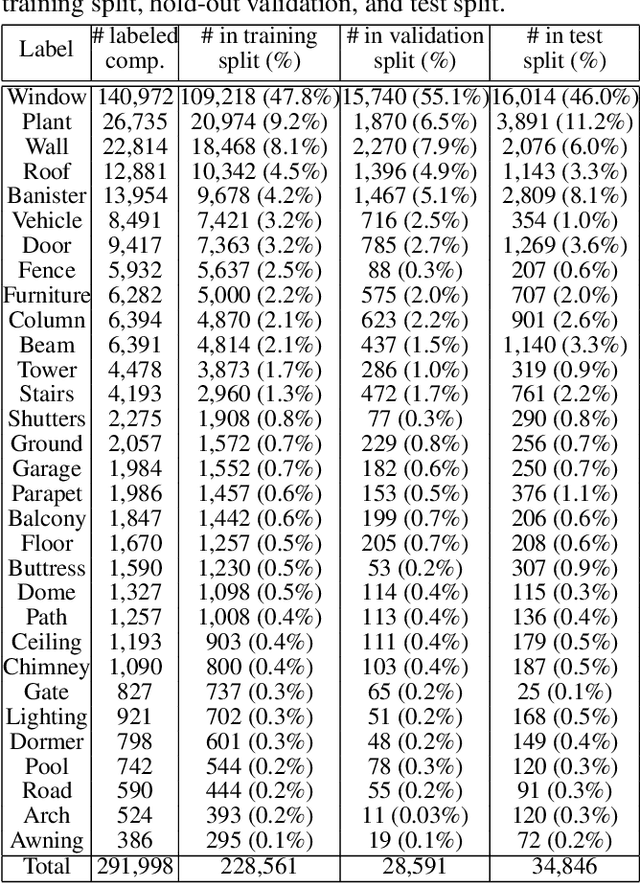
We introduce BuildingNet: (a) a large-scale dataset of 3D building models whose exteriors are consistently labeled, (b) a graph neural network that labels building meshes by analyzing spatial and structural relations of their geometric primitives. To create our dataset, we used crowdsourcing combined with expert guidance, resulting in 513K annotated mesh primitives, grouped into 292K semantic part components across 2K building models. The dataset covers several building categories, such as houses, churches, skyscrapers, town halls, libraries, and castles. We include a benchmark for evaluating mesh and point cloud labeling. Buildings have more challenging structural complexity compared to objects in existing benchmarks (e.g., ShapeNet, PartNet), thus, we hope that our dataset can nurture the development of algorithms that are able to cope with such large-scale geometric data for both vision and graphics tasks e.g., 3D semantic segmentation, part-based generative models, correspondences, texturing, and analysis of point cloud data acquired from real-world buildings. Finally, we show that our mesh-based graph neural network significantly improves performance over several baselines for labeling 3D meshes.