 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableQAT: Stable Quantization-Aware Training at Ultra-Low Bitwidths
Jan 27, 2026Quantization-aware training (QAT) is essential for deploying large models under strict memory and latency constraints, yet achieving stable and robust optimization at ultra-low bitwidths remains challenging. Common approaches based on the straight-through estimator (STE) or soft quantizers often suffer from gradient mismatch, instability, or high computational overhead. As such, we propose StableQAT, a unified and efficient QAT framework that stabilizes training in ultra low-bit settings via a novel, lightweight, and theoretically grounded surrogate for backpropagation derived from a discrete Fourier analysis of the rounding operator. StableQAT strictly generalizes STE as the latter arises as a special case of our more expressive surrogate family, yielding smooth, bounded, and inexpensive gradients that improve QAT training performance and stability across various hyperparameter choices. In experiments, StableQAT exhibits stable and efficient QAT at 2-4 bit regimes, demonstrating improved training stability, robustness, and superior performance with negligible training overhead against standard QAT techniques. Our code is available at https://github.com/microsoft/StableQAT.
ProCrop: Learning Aesthetic Image Cropping from Professional Compositions
May 28, 2025Image cropping is crucial for enhancing the visual appeal and narrative impact of photographs, yet existing rule-based and data-driven approaches often lack diversity or require annotated training data. We introduce ProCrop, a retrieval-based method that leverages professional photography to guide cropping decisions. By fusing features from professional photographs with those of the query image, ProCrop learns from professional compositions, significantly boosting performance. Additionally, we present a large-scale dataset of 242K weakly-annotated images, generated by out-painting professional images and iteratively refining diverse crop proposals. This composition-aware dataset generation offers diverse high-quality crop proposals guided by aesthetic principles and becomes the largest publicly available dataset for image cropping. Extensive experiments show that ProCrop significantly outperforms existing methods in both supervised and weakly-supervised settings. Notably, when trained on the new dataset, our ProCrop surpasses previous weakly-supervised methods and even matches fully supervised approaches. Both the code and dataset will be made publicly available to advance research in image aesthetics and composition analysis.
WINA: Weight Informed Neuron Activation for Accelerating Large Language Model Inference
May 26, 2025The growing computational demands of large language models (LLMs) make efficient inference and activation strategies increasingly critical. While recent approaches, such as Mixture-of-Experts (MoE), leverage selective activation but require specialized training, training-free sparse activation methods offer broader applicability and superior resource efficiency through their plug-and-play design. However, many existing methods rely solely on hidden state magnitudes to determine activation, resulting in high approximation errors and suboptimal inference accuracy. To address these limitations, we propose WINA (Weight Informed Neuron Activation), a novel, simple, and training-free sparse activation framework that jointly considers hidden state magnitudes and the column-wise $\ell_2$-norms of weight matrices. We show that this leads to a sparsification strategy that obtains optimal approximation error bounds with theoretical guarantees tighter than existing techniques. Empirically, WINA also outperforms state-of-the-art methods (e.g., TEAL) by up to $2.94\%$ in average performance at the same sparsity levels, across a diverse set of LLM architectures and datasets. These results position WINA as a new performance frontier for training-free sparse activation in LLM inference, advancing training-free sparse activation methods and setting a robust baseline for efficient inference. The source code is available at https://github.com/microsoft/wina.
DistiLLM-2: A Contrastive Approach Boosts the Distillation of LLMs
Mar 10, 2025



Despite the success of distillation in large language models (LLMs), most prior work applies identical loss functions to both teacher- and student-generated data. These strategies overlook the synergy between loss formulations and data types, leading to a suboptimal performance boost in student models. To address this, we propose DistiLLM-2, a contrastive approach that simultaneously increases the likelihood of teacher responses and decreases that of student responses by harnessing this synergy. Our extensive experiments show that DistiLLM-2 not only builds high-performing student models across a wide range of tasks, including instruction-following and code generation, but also supports diverse applications, such as preference alignment and vision-language extensions. These findings highlight the potential of a contrastive approach to enhance the efficacy of LLM distillation by effectively aligning teacher and student models across varied data types.
Motion Graph Unleashed: A Novel Approach to Video Prediction
Oct 29, 2024We introduce motion graph, a novel approach to the video prediction problem, which predicts future video frames from limited past data. The motion graph transforms patches of video frames into interconnected graph nodes, to comprehensively describe the spatial-temporal relationships among them. This representation overcomes the limitations of existing motion representations such as image differences, optical flow, and motion matrix that either fall short in capturing complex motion patterns or suffer from excessive memory consumption. We further present a video prediction pipeline empowered by motion graph, exhibiting substantial performance improvements and cost reductions. Experiments on various datasets, including UCF Sports, KITTI and Cityscapes, highlight the strong representative ability of motion graph. Especially on UCF Sports, our method matches and outperforms the SOTA methods with a significant reduction in model size by 78% and a substantial decrease in GPU memory utilization by 47%.
A foundation model enpowered by a multi-modal prompt engine for universal seismic geobody interpretation across surveys
Sep 08, 2024



Seismic geobody interpretation is crucial for structural geology studies and various engineering applications. Existing deep learning methods show promise but lack support for multi-modal inputs and struggle to generalize to different geobody types or surveys. We introduce a promptable foundation model for interpreting any geobodies across seismic surveys. This model integrates a pre-trained vision foundation model (VFM) with a sophisticated multi-modal prompt engine. The VFM, pre-trained on massive natural images and fine-tuned on seismic data, provides robust feature extraction for cross-survey generalization. The prompt engine incorporates multi-modal prior information to iteratively refine geobody delineation. Extensive experiments demonstrate the model's superior accuracy, scalability from 2D to 3D, and generalizability to various geobody types, including those unseen during training. To our knowledge, this is the first highly scalable and versatile multi-modal foundation model capable of interpreting any geobodies across surveys while supporting real-time interactions. Our approach establishes a new paradigm for geoscientific data interpretation, with broad potential for transfer to other tasks.
Cross-Domain Foundation Model Adaptation: Pioneering Computer Vision Models for Geophysical Data Analysis
Aug 22, 2024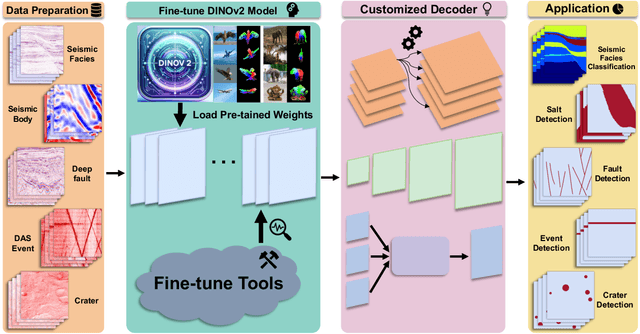

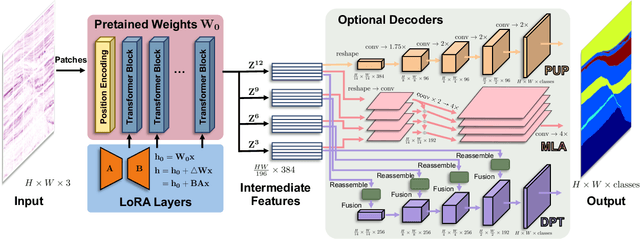
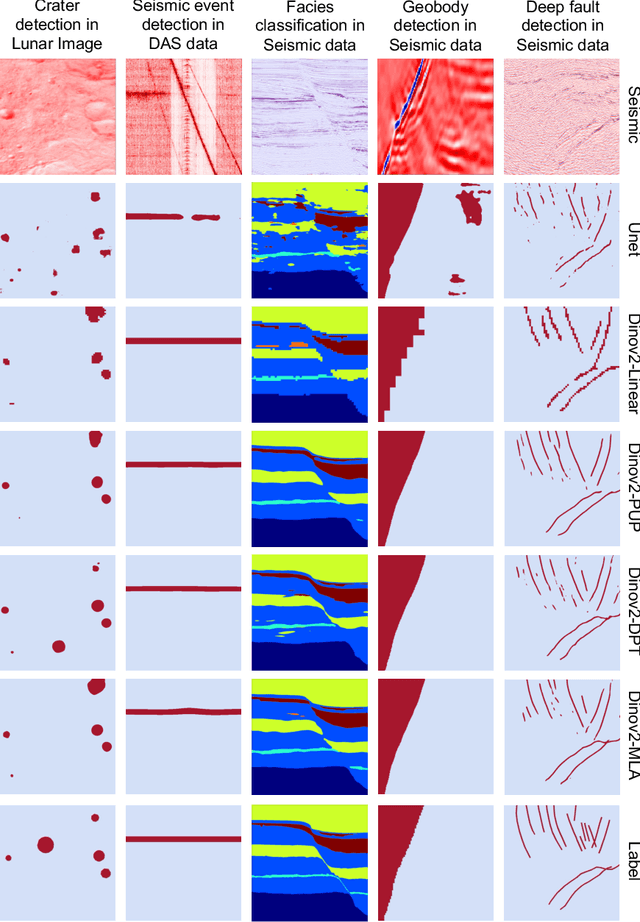
We explore adapting foundation models (FMs) from the computer vision domain to geoscience. FMs, large neural networks trained on massive datasets, excel in diverse tasks with remarkable adaptability and generality. However, geoscience faces challenges like lacking curated training datasets and high computational costs for developing specialized FMs. This study considers adapting FMs from computer vision to geoscience, analyzing their scale, adaptability, and generality for geoscientific data analysis. We introduce a workflow that leverages existing computer vision FMs, fine-tuning them for geoscientific tasks, reducing development costs while enhancing accuracy. Through experiments, we demonstrate this workflow's effectiveness in broad applications to process and interpret geoscientific data of lunar images, seismic data, DAS arrays and so on. Our findings introduce advanced ML techniques to geoscience, proving the feasibility and advantages of cross-domain FMs adaptation, driving further advancements in geoscientific data analysis and offering valuable insights for FMs applications in other scientific domains.
FORA: Fast-Forward Caching in Diffusion Transformer Acceleration
Jul 01, 2024Diffusion transformers (DiT) have become the de facto choice for generating high-quality images and videos, largely due to their scalability, which enables the construction of larger models for enhanced performance. However, the increased size of these models leads to higher inference costs, making them less attractive for real-time applications. We present Fast-FORward CAching (FORA), a simple yet effective approach designed to accelerate DiT by exploiting the repetitive nature of the diffusion process. FORA implements a caching mechanism that stores and reuses intermediate outputs from the attention and MLP layers across denoising steps, thereby reducing computational overhead. This approach does not require model retraining and seamlessly integrates with existing transformer-based diffusion models. Experiments show that FORA can speed up diffusion transformers several times over while only minimally affecting performance metrics such as the IS Score and FID. By enabling faster processing with minimal trade-offs in quality, FORA represents a significant advancement in deploying diffusion transformers for real-time applications. Code will be made publicly available at: https://github.com/prathebaselva/FORA.
AdaContour: Adaptive Contour Descriptor with Hierarchical Representation
Apr 12, 2024Existing angle-based contour descriptors suffer from lossy representation for non-starconvex shapes. By and large, this is the result of the shape being registered with a single global inner center and a set of radii corresponding to a polar coordinate parameterization. In this paper, we propose AdaContour, an adaptive contour descriptor that uses multiple local representations to desirably characterize complex shapes. After hierarchically encoding object shapes in a training set and constructing a contour matrix of all subdivided regions, we compute a robust low-rank robust subspace and approximate each local contour by linearly combining the shared basis vectors to represent an object. Experiments show that AdaContour is able to represent shapes more accurately and robustly than other descriptors while retaining effectiveness. We validate AdaContour by integrating it into off-the-shelf detectors to enable instance segmentation which demonstrates faithful performance. The code is available at https://github.com/tding1/AdaContour.
S3Editor: A Sparse Semantic-Disentangled Self-Training Framework for Face Video Editing
Apr 11, 2024Face attribute editing plays a pivotal role in various applications. However, existing methods encounter challenges in achieving high-quality results while preserving identity, editing faithfulness, and temporal consistency. These challenges are rooted in issues related to the training pipeline, including limited supervision, architecture design, and optimization strategy. In this work, we introduce S3Editor, a Sparse Semantic-disentangled Self-training framework for face video editing. S3Editor is a generic solution that comprehensively addresses these challenges with three key contributions. Firstly, S3Editor adopts a self-training paradigm to enhance the training process through semi-supervision. Secondly, we propose a semantic disentangled architecture with a dynamic routing mechanism that accommodates diverse editing requirements. Thirdly, we present a structured sparse optimization schema that identifies and deactivates malicious neurons to further disentangle impacts from untarget attributes. S3Editor is model-agnostic and compatible with various editing approaches. Our extensive qualitative and quantitative results affirm that our approach significantly enhances identity preservation, editing fidelity, as well as temporal consistency.