 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the workflow, opportunities and challenges of developing foundation model in geophysics
Apr 24, 2025Foundation models, as a mainstream technology in artificial intelligence, have demonstrated immense potential across various domains in recent years, particularly in handling complex tasks and multimodal data. In the field of geophysics, although the application of foundation models is gradually expanding, there is currently a lack of comprehensive reviews discussing the full workflow of integrating foundation models with geophysical data. To address this gap, this paper presents a complete framework that systematically explores the entire process of developing foundation models in conjunction with geophysical data. From data collection and preprocessing to model architecture selection, pre-training strategies, and model deployment, we provide a detailed analysis of the key techniques and methodologies at each stage. In particular, considering the diversity, complexity, and physical consistency constraints of geophysical data, we discuss targeted solutions to address these challenges. Furthermore, we discuss how to leverage the transfer learning capabilities of foundation models to reduce reliance on labeled data, enhance computational efficiency, and incorporate physical constraints into model training, thereby improving physical consistency and interpretability. Through a comprehensive summary and analysis of the current technological landscape, this paper not only fills the gap in the geophysics domain regarding a full-process review of foundation models but also offers valuable practical guidance for their application in geophysical data analysis, driving innovation and advancement in the field.
A foundation model enpowered by a multi-modal prompt engine for universal seismic geobody interpretation across surveys
Sep 08, 2024



Seismic geobody interpretation is crucial for structural geology studies and various engineering applications. Existing deep learning methods show promise but lack support for multi-modal inputs and struggle to generalize to different geobody types or surveys. We introduce a promptable foundation model for interpreting any geobodies across seismic surveys. This model integrates a pre-trained vision foundation model (VFM) with a sophisticated multi-modal prompt engine. The VFM, pre-trained on massive natural images and fine-tuned on seismic data, provides robust feature extraction for cross-survey generalization. The prompt engine incorporates multi-modal prior information to iteratively refine geobody delineation. Extensive experiments demonstrate the model's superior accuracy, scalability from 2D to 3D, and generalizability to various geobody types, including those unseen during training. To our knowledge, this is the first highly scalable and versatile multi-modal foundation model capable of interpreting any geobodies across surveys while supporting real-time interactions. Our approach establishes a new paradigm for geoscientific data interpretation, with broad potential for transfer to other tasks.
Cross-Domain Foundation Model Adaptation: Pioneering Computer Vision Models for Geophysical Data Analysis
Aug 22, 2024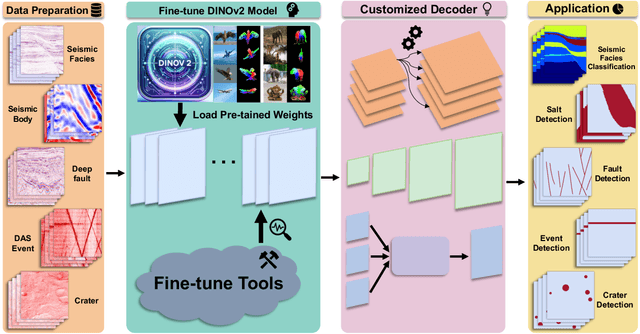

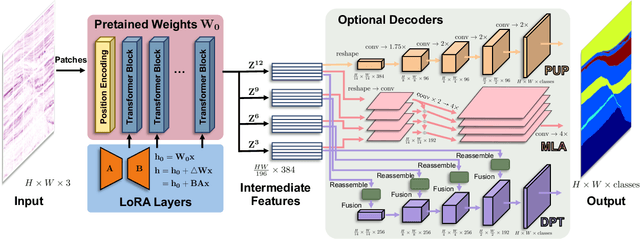
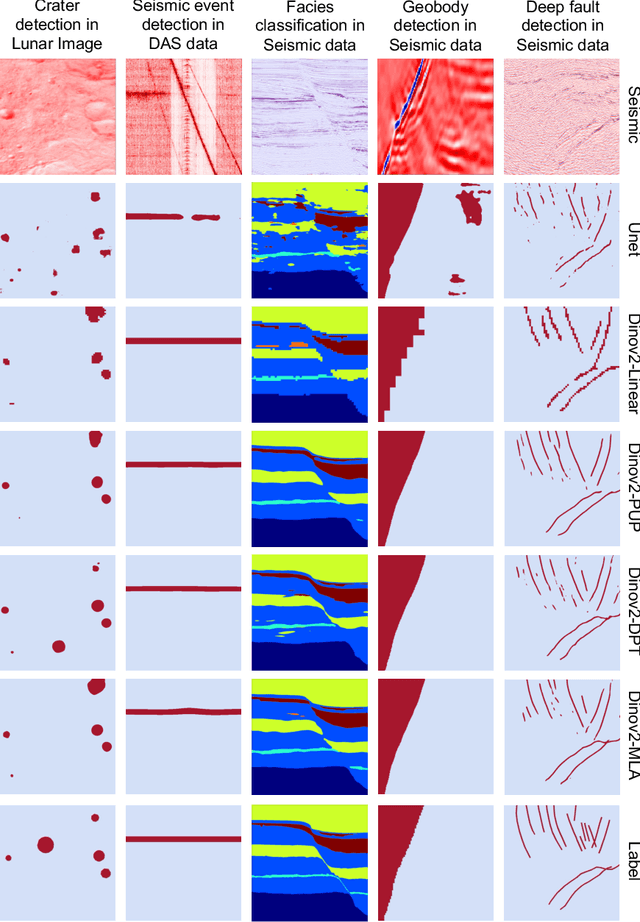
We explore adapting foundation models (FMs) from the computer vision domain to geoscience. FMs, large neural networks trained on massive datasets, excel in diverse tasks with remarkable adaptability and generality. However, geoscience faces challenges like lacking curated training datasets and high computational costs for developing specialized FMs. This study considers adapting FMs from computer vision to geoscience, analyzing their scale, adaptability, and generality for geoscientific data analysis. We introduce a workflow that leverages existing computer vision FMs, fine-tuning them for geoscientific tasks, reducing development costs while enhancing accuracy. Through experiments, we demonstrate this workflow's effectiveness in broad applications to process and interpret geoscientific data of lunar images, seismic data, DAS arrays and so on. Our findings introduce advanced ML techniques to geoscience, proving the feasibility and advantages of cross-domain FMs adaptation, driving further advancements in geoscientific data analysis and offering valuable insights for FMs applications in other scientific domains.
SeisCLIP: A seismology foundation model pre-trained by multi-modal data for multi-purpose seismic feature extraction
Sep 05, 2023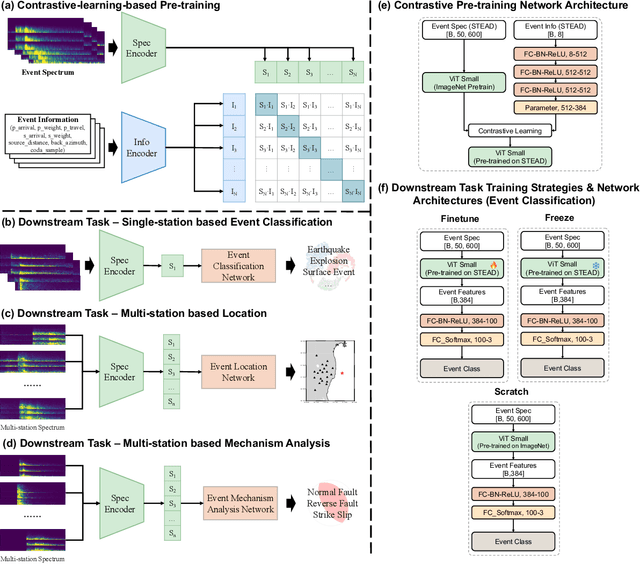

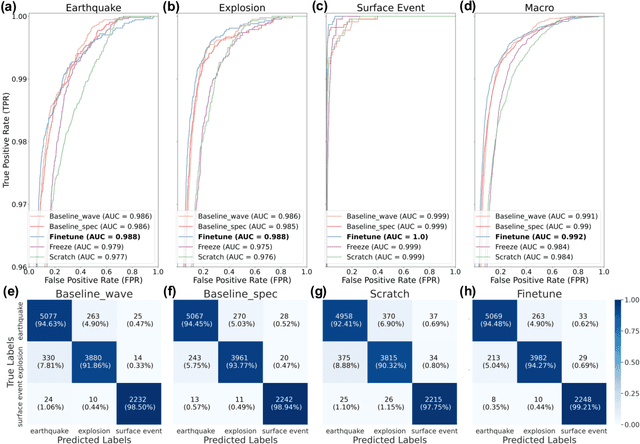
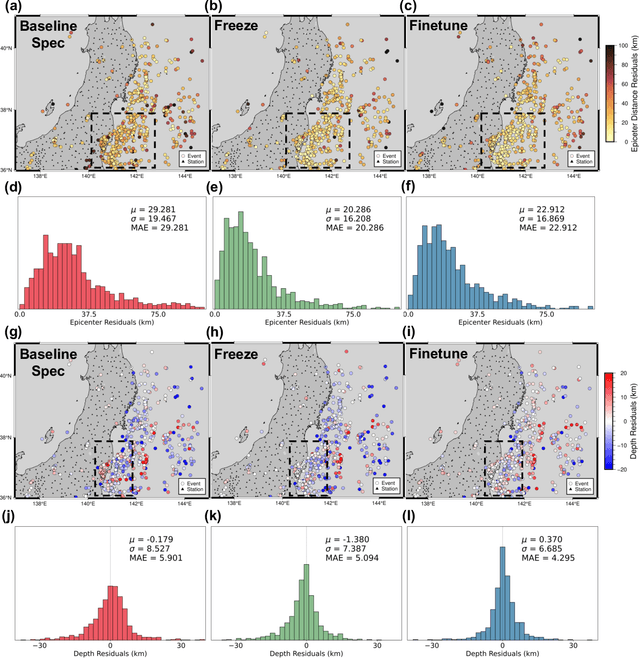
Training specific deep learning models for particular tasks is common across various domains within seismology. However, this approach encounters two limitations: inadequate labeled data for certain tasks and limited generalization across regions. To address these challenges, we develop SeisCLIP, a seismology foundation model trained through contrastive learning from multi-modal data. It consists of a transformer encoder for extracting crucial features from time-frequency seismic spectrum and an MLP encoder for integrating the phase and source information of the same event. These encoders are jointly pre-trained on a vast dataset and the spectrum encoder is subsequently fine-tuned on smaller datasets for various downstream tasks. Notably, SeisCLIP's performance surpasses that of baseline methods in event classification, localization, and focal mechanism analysis tasks, employing distinct datasets from different regions. In conclusion, SeisCLIP holds significant potential as a foundational model in the field of seismology, paving the way for innovative directions in foundation-model-based seismology research.