 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeisCLIP: A seismology foundation model pre-trained by multi-modal data for multi-purpose seismic feature extraction
Paper and Code
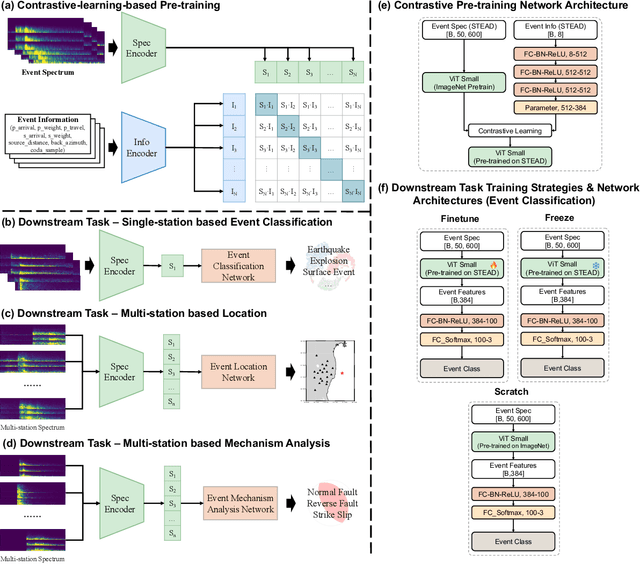

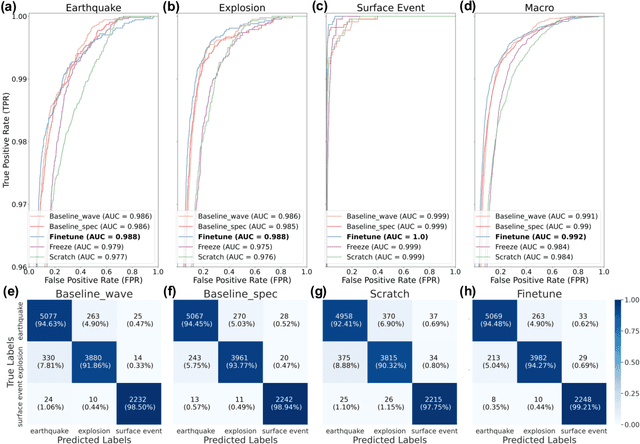
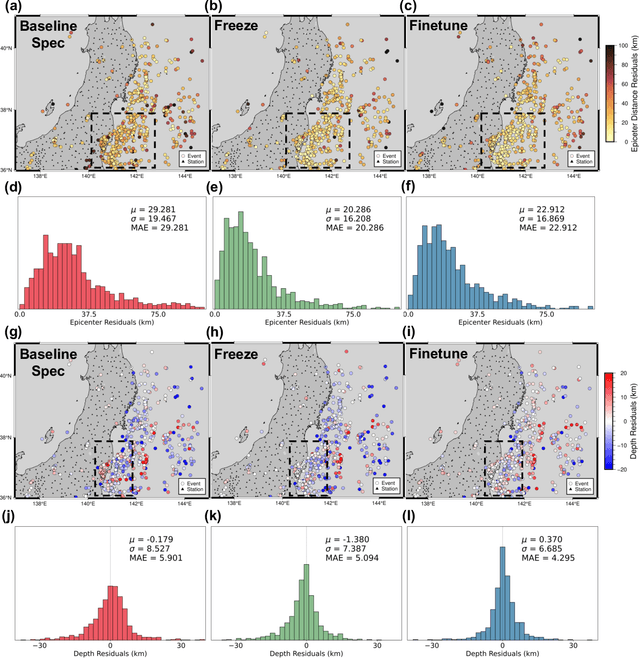
Training specific deep learning models for particular tasks is common across various domains within seismology. However, this approach encounters two limitations: inadequate labeled data for certain tasks and limited generalization across regions. To address these challenges, we develop SeisCLIP, a seismology foundation model trained through contrastive learning from multi-modal data. It consists of a transformer encoder for extracting crucial features from time-frequency seismic spectrum and an MLP encoder for integrating the phase and source information of the same event. These encoders are jointly pre-trained on a vast dataset and the spectrum encoder is subsequently fine-tuned on smaller datasets for various downstream tasks. Notably, SeisCLIP's performance surpasses that of baseline methods in event classification, localization, and focal mechanism analysis tasks, employing distinct datasets from different regions. In conclusion, SeisCLIP holds significant potential as a foundational model in the field of seismology, paving the way for innovative directions in foundation-model-based seismology research.