 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
On the workflow, opportunities and challenges of developing foundation model in geophysics
Apr 24, 2025Foundation models, as a mainstream technology in artificial intelligence, have demonstrated immense potential across various domains in recent years, particularly in handling complex tasks and multimodal data. In the field of geophysics, although the application of foundation models is gradually expanding, there is currently a lack of comprehensive reviews discussing the full workflow of integrating foundation models with geophysical data. To address this gap, this paper presents a complete framework that systematically explores the entire process of developing foundation models in conjunction with geophysical data. From data collection and preprocessing to model architecture selection, pre-training strategies, and model deployment, we provide a detailed analysis of the key techniques and methodologies at each stage. In particular, considering the diversity, complexity, and physical consistency constraints of geophysical data, we discuss targeted solutions to address these challenges. Furthermore, we discuss how to leverage the transfer learning capabilities of foundation models to reduce reliance on labeled data, enhance computational efficiency, and incorporate physical constraints into model training, thereby improving physical consistency and interpretability. Through a comprehensive summary and analysis of the current technological landscape, this paper not only fills the gap in the geophysics domain regarding a full-process review of foundation models but also offers valuable practical guidance for their application in geophysical data analysis, driving innovation and advancement in the field.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
A foundation model enpowered by a multi-modal prompt engine for universal seismic geobody interpretation across surveys
Sep 08, 2024



Seismic geobody interpretation is crucial for structural geology studies and various engineering applications. Existing deep learning methods show promise but lack support for multi-modal inputs and struggle to generalize to different geobody types or surveys. We introduce a promptable foundation model for interpreting any geobodies across seismic surveys. This model integrates a pre-trained vision foundation model (VFM) with a sophisticated multi-modal prompt engine. The VFM, pre-trained on massive natural images and fine-tuned on seismic data, provides robust feature extraction for cross-survey generalization. The prompt engine incorporates multi-modal prior information to iteratively refine geobody delineation. Extensive experiments demonstrate the model's superior accuracy, scalability from 2D to 3D, and generalizability to various geobody types, including those unseen during training. To our knowledge, this is the first highly scalable and versatile multi-modal foundation model capable of interpreting any geobodies across surveys while supporting real-time interactions. Our approach establishes a new paradigm for geoscientific data interpretation, with broad potential for transfer to other tasks.
Cross-Domain Foundation Model Adaptation: Pioneering Computer Vision Models for Geophysical Data Analysis
Aug 22, 2024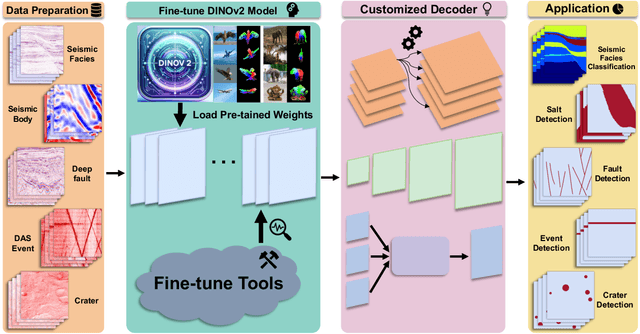

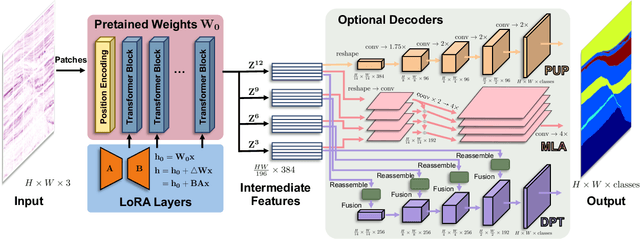
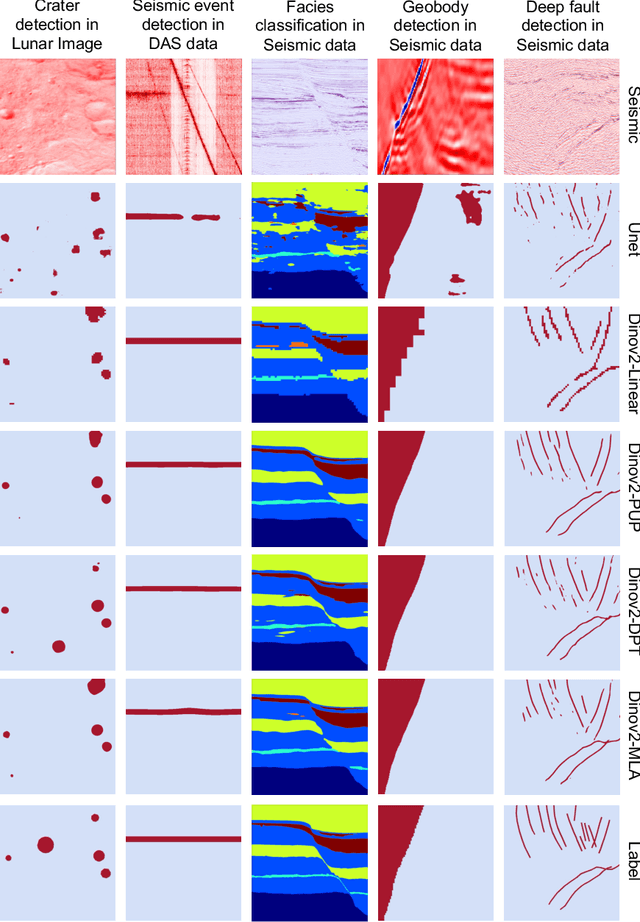
We explore adapting foundation models (FMs) from the computer vision domain to geoscience. FMs, large neural networks trained on massive datasets, excel in diverse tasks with remarkable adaptability and generality. However, geoscience faces challenges like lacking curated training datasets and high computational costs for developing specialized FMs. This study considers adapting FMs from computer vision to geoscience, analyzing their scale, adaptability, and generality for geoscientific data analysis. We introduce a workflow that leverages existing computer vision FMs, fine-tuning them for geoscientific tasks, reducing development costs while enhancing accuracy. Through experiments, we demonstrate this workflow's effectiveness in broad applications to process and interpret geoscientific data of lunar images, seismic data, DAS arrays and so on. Our findings introduce advanced ML techniques to geoscience, proving the feasibility and advantages of cross-domain FMs adaptation, driving further advancements in geoscientific data analysis and offering valuable insights for FMs applications in other scientific domains.
SeisCLIP: A seismology foundation model pre-trained by multi-modal data for multi-purpose seismic feature extraction
Sep 05, 2023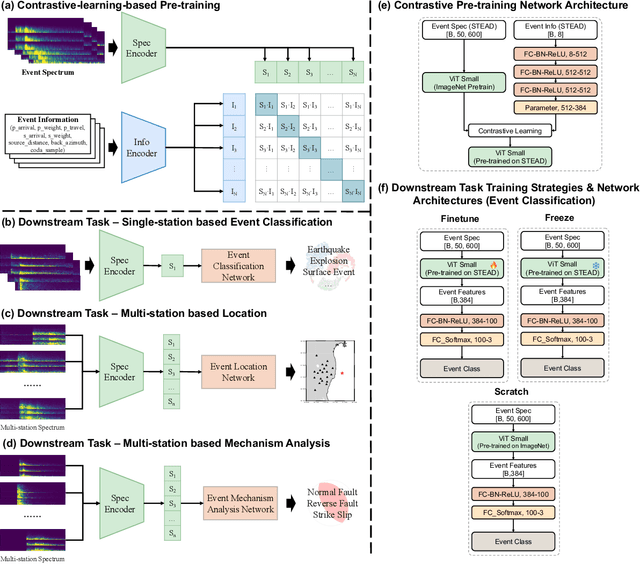

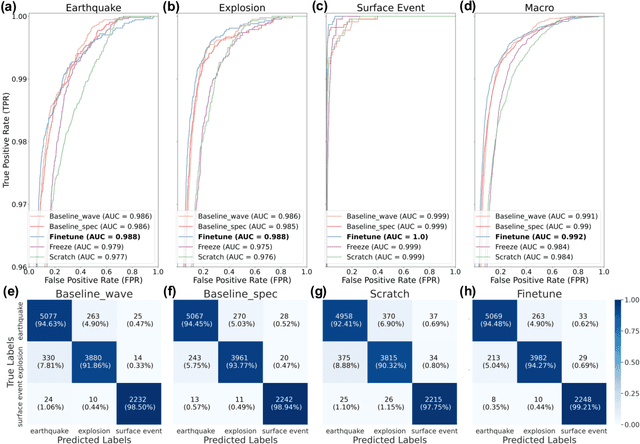
Training specific deep learning models for particular tasks is common across various domains within seismology. However, this approach encounters two limitations: inadequate labeled data for certain tasks and limited generalization across regions. To address these challenges, we develop SeisCLIP, a seismology foundation model trained through contrastive learning from multi-modal data. It consists of a transformer encoder for extracting crucial features from time-frequency seismic spectrum and an MLP encoder for integrating the phase and source information of the same event. These encoders are jointly pre-trained on a vast dataset and the spectrum encoder is subsequently fine-tuned on smaller datasets for various downstream tasks. Notably, SeisCLIP's performance surpasses that of baseline methods in event classification, localization, and focal mechanism analysis tasks, employing distinct datasets from different regions. In conclusion, SeisCLIP holds significant potential as a foundational model in the field of seismology, paving the way for innovative directions in foundation-model-based seismology research.
Multi-task multi-station earthquake monitoring: An all-in-one seismic Phase picking, Location, and Association Network (PLAN)
Jun 24, 2023



Earthquake monitoring is vital for understanding the physics of earthquakes and assessing seismic hazards. A standard monitoring workflow includes the interrelated and interdependent tasks of phase picking, association, and location. Although deep learning methods have been successfully applied to earthquake monitoring, they mostly address the tasks separately and ignore the geographic relationships among stations. Here, we propose a graph neural network that operates directly on multi-station seismic data and achieves simultaneous phase picking, association, and location. Particularly, the inter-station and inter-task physical relationships are informed in the network architecture to promote accuracy, interpretability, and physical consistency among cross-station and cross-task predictions. When applied to data from the Ridgecrest region and Japan regions, this method showed superior performance over previous deep learning-based phase-picking and localization methods. Overall, our study provides for the first time a prototype self-consistent all-in-one system of simultaneous seismic phase picking, association, and location, which has the potential for next-generation autonomous earthquake monitoring.
A Deep-Learning-Based Neural Decoding Framework for Emotional Brain-Computer Interfaces
Mar 08, 2023Reading emotions precisely from segments of neural activity is crucial for the development of emotional brain-computer interfaces. Among all neural decoding algorithms, deep learning (DL) holds the potential to become the most promising one, yet progress has been limited in recent years. One possible reason is that the efficacy of DL strongly relies on training samples, yet the neural data used for training are often from non-human primates and mixed with plenty of noise, which in turn mislead the training of DL models. Given it is difficult to accurately determine animals' emotions from humans' perspective, we assume the dominant noise in neural data representing different emotions is the labeling error. Here, we report the development and application of a neural decoding framework called Emo-Net that consists of a confidence learning (CL) component and a DL component. The framework is fully data-driven and is capable of decoding emotions from multiple datasets obtained from behaving monkeys. In addition to improving the decoding ability, Emo-Net significantly improves the performance of the base DL models, making emotion recognition in animal models possible. In summary, this framework may inspire novel understandings of the neural basis of emotion and drive the realization of close-loop emotional brain-computer interfaces.
Deep learning based sferics recognition for AMT data processing in the dead band
Sep 22, 2022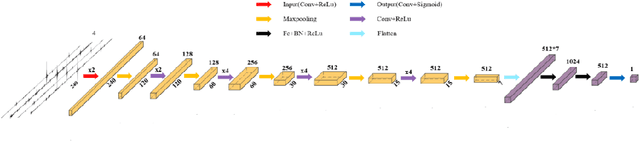
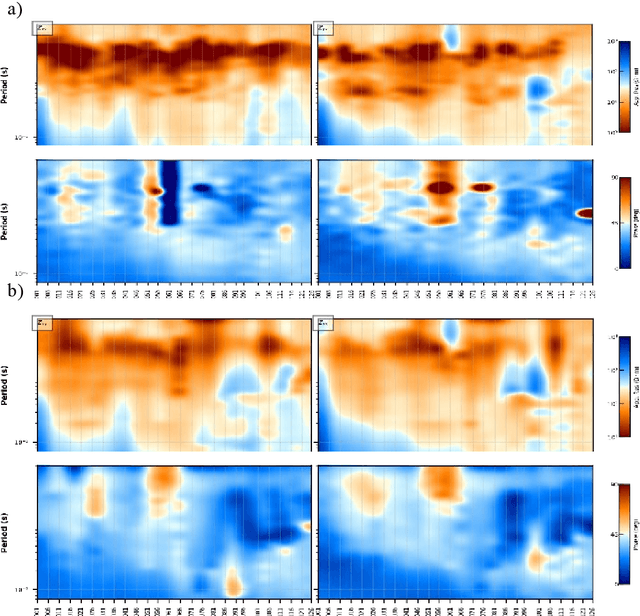
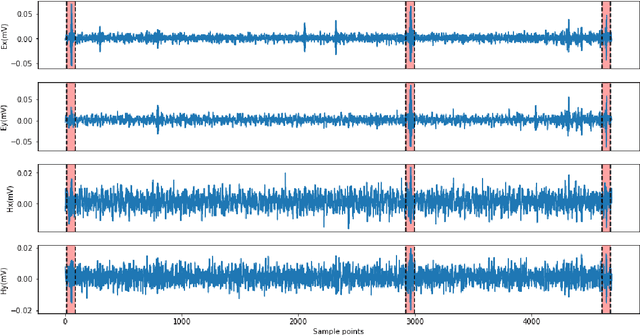
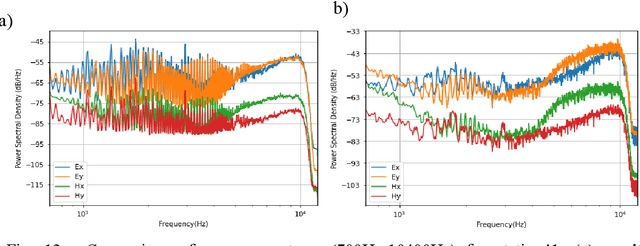
In the audio magnetotellurics (AMT) sounding data processing, the absence of sferic signals in some time ranges typically results in a lack of energy in the AMT dead band, which may cause unreliable resistivity estimate. We propose a deep convolutional neural network (CNN) to automatically recognize sferic signals from redundantly recorded data in a long time range and use them to compensate for the resistivity estimation. We train the CNN by using field time series data with different signal to noise rations that were acquired from different regions in mainland China. To solve the potential overfitting problem due to the limited number of sferic labels, we propose a training strategy that randomly generates training samples (with random data augmentations) while optimizing the CNN model parameters. We stop the training process and data generation until the training loss converges. In addition, we use a weighted binary cross-entropy loss function to solve the sample imbalance problem to better optimize the network, use multiple reasonable metrics to evaluate network performance, and carry out ablation experiments to optimally choose the model hyperparameters. Extensive field data applications show that our trained CNN can robustly recognize sferic signals from noisy time series for subsequent impedance estimation. The subsequent processing results show that our method can significantly improve S/N and effectively solve the problem of lack of energy in dead band. Compared to the traditional processing method without sferic compensation, our method can generate a smoother and more reasonable apparent resistivity-phase curves and depolarized phase tensor, correct the estimation error of sudden drop of high-frequency apparent resistivity and abnormal behavior of phase reversal, and finally better restore the real shallow subsurface resistivity structure.
Convolutional Neural Network with Median Layers for Denoising Salt-and-Pepper Contaminations
Aug 18, 2019
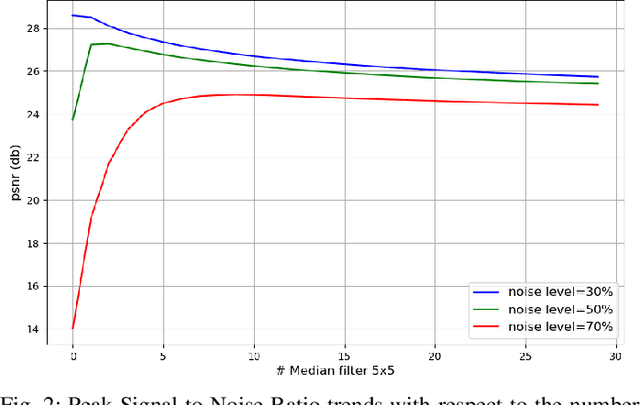
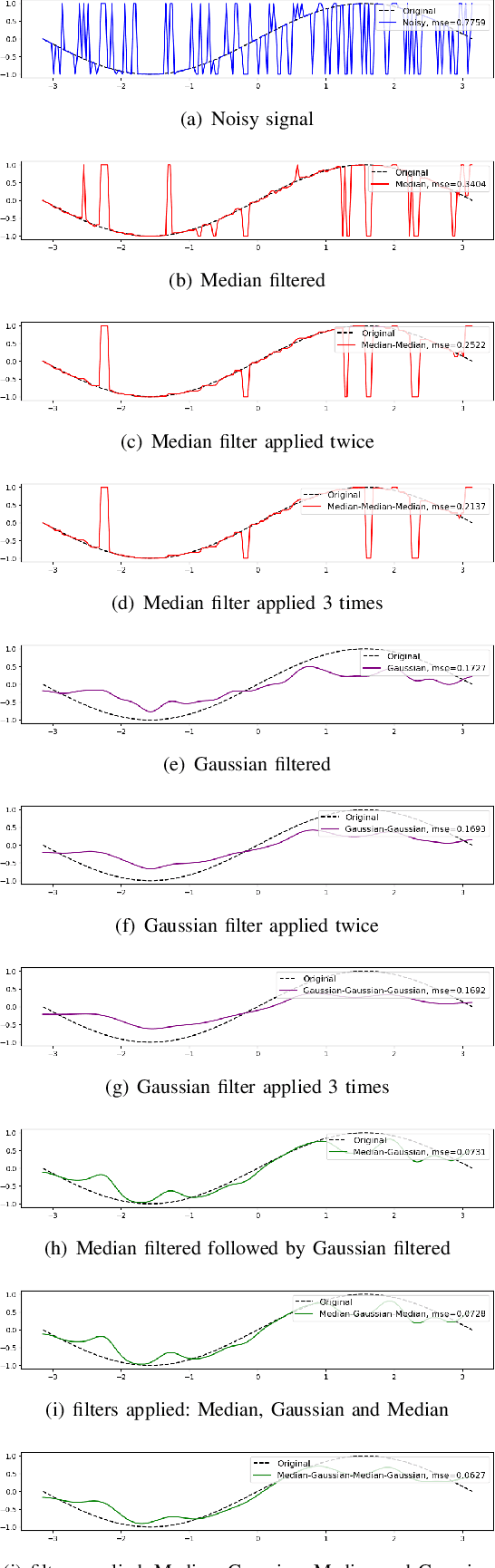
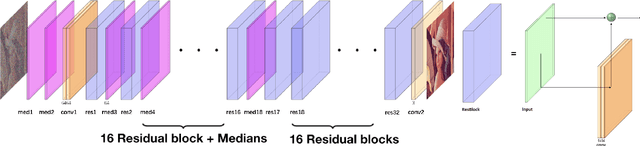
We propose a deep fully convolutional neural network with a new type of layer, named median layer, to restore images contaminated by the salt-and-pepper (s&p) noise. A median layer simply performs median filtering on all feature channels. By adding this kind of layer into some widely used fully convolutional deep neural networks, we develop an end-to-end network that removes the extremely high-level s&p noise without performing any non-trivial preprocessing tasks, which is different from all the existing literature in s&p noise removal. Experiments show that inserting median layers into a simple fully-convolutional network with the L2 loss significantly boosts the signal-to-noise ratio. Quantitative comparisons testify that our network outperforms the state-of-the-art methods with a limited amount of training data. The source code has been released for public evaluation and use (https://github.com/llmpass/medianDenoise).