 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Learning Improves Static Object Geo-localization in Monocular Video
Apr 10, 2020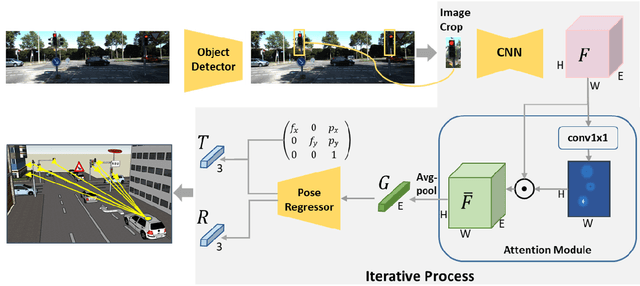
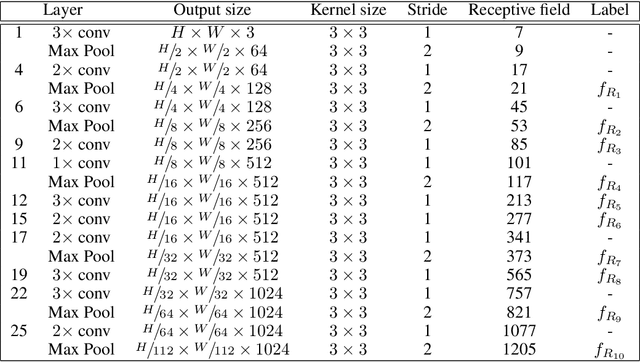
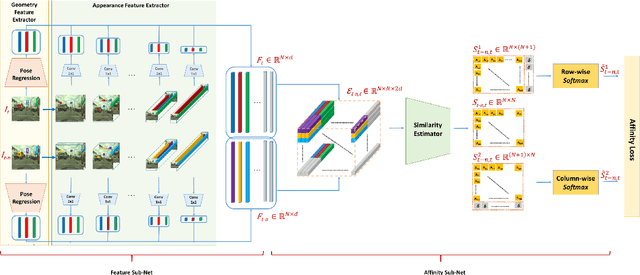
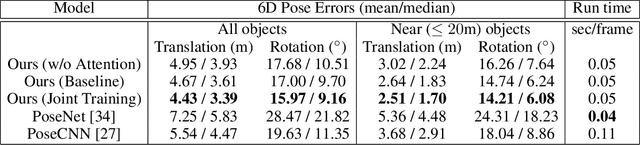
Accurately estimating the position of static objects, such as traffic lights, from the moving camera of a self-driving car is a challenging problem. In this work, we present a system that improves the localization of static objects by jointly-optimizing the components of the system via learning. Our system is comprised of networks that perform: 1) 6DoF object pose estimation from a single image, 2) association of objects between pairs of frames, and 3) multi-object tracking to produce the final geo-localization of the static objects within the scene. We evaluate our approach using a publicly-available data set, focusing on traffic lights due to data availability. For each component, we compare against contemporary alternatives and show significantly-improved performance. We also show that the end-to-end system performance is further improved via joint-training of the constituent models.
Convolutional Neural Network with Median Layers for Denoising Salt-and-Pepper Contaminations
Aug 18, 2019
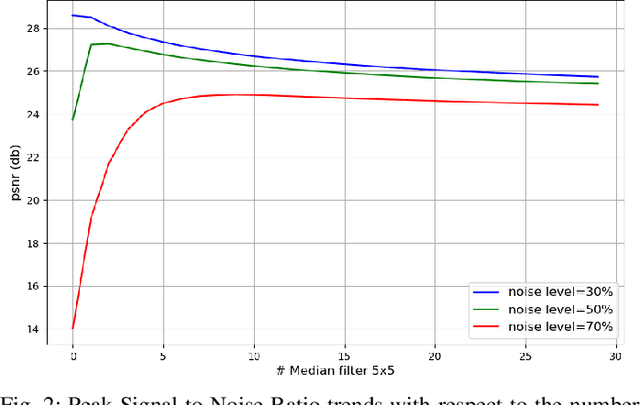
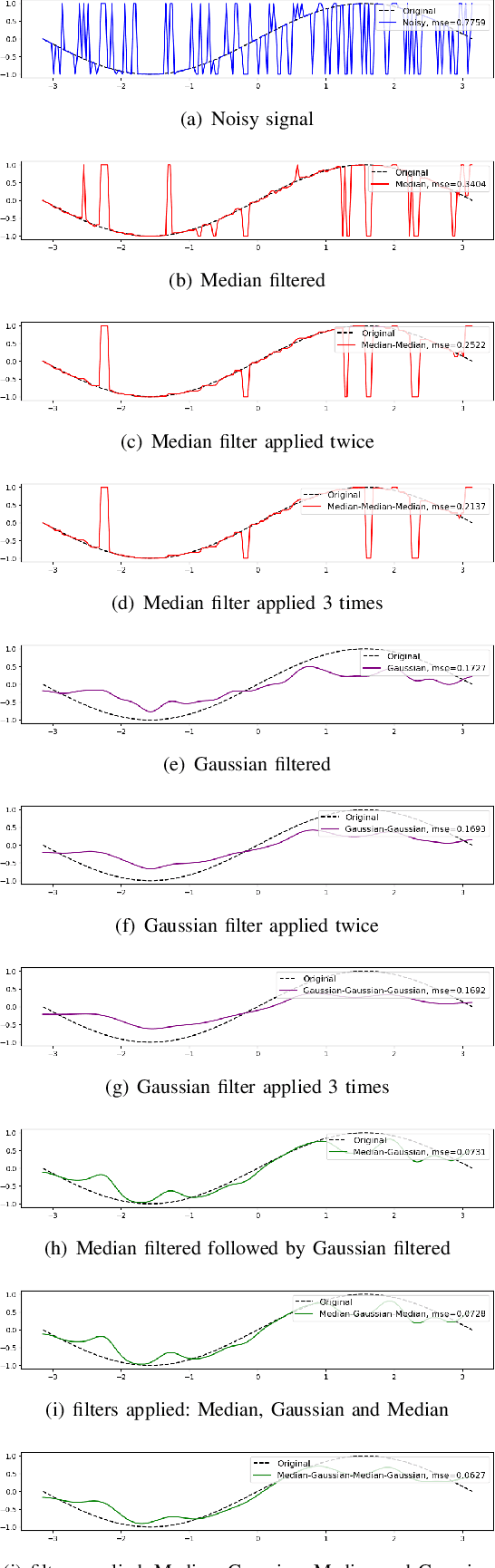
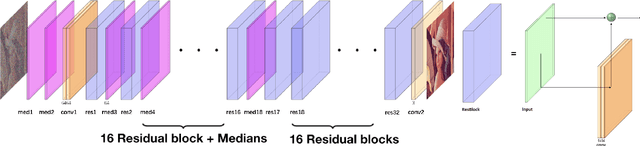
We propose a deep fully convolutional neural network with a new type of layer, named median layer, to restore images contaminated by the salt-and-pepper (s&p) noise. A median layer simply performs median filtering on all feature channels. By adding this kind of layer into some widely used fully convolutional deep neural networks, we develop an end-to-end network that removes the extremely high-level s&p noise without performing any non-trivial preprocessing tasks, which is different from all the existing literature in s&p noise removal. Experiments show that inserting median layers into a simple fully-convolutional network with the L2 loss significantly boosts the signal-to-noise ratio. Quantitative comparisons testify that our network outperforms the state-of-the-art methods with a limited amount of training data. The source code has been released for public evaluation and use (https://github.com/llmpass/medianDenoise).
Joint Mapping and Calibration via Differentiable Sensor Fusion
Nov 21, 2018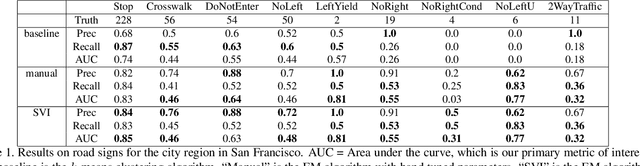


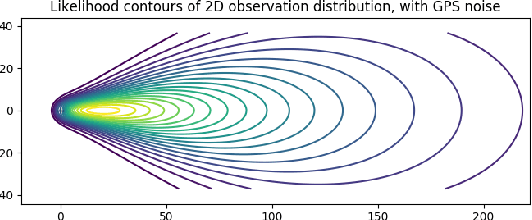
We leverage automatic differentiation (AD) and probabilistic programming languages to develop an end-to-end optimization algorithm for batch triangulation of a large number of unknown objects. Given noisy detections extracted from noisily geo-located street level imagery without depth information, we jointly estimate the number and location of objects of different types, together with parameters for sensor noise characteristics and prior distribution of objects conditioned on side information. The entire algorithm is framed as nested stochastic variational inference. An inner loop solves a soft data association problem via loopy belief propagation; a middle loop performs soft EM clustering using a regularized Newton solver (leveraging an AD framework); an outer loop backpropagates through the inner loops to train global parameters. We place priors over sensor parameters for different traffic object types, and demonstrate improvements with richer priors incorporating knowledge of the environment. We test our algorithm on detections of road signs observed by cars with mounted cameras, though in practice this technique can be used for any geo-tagged images. We assume images do not have depth information (e.g. from lidar or stereo cameras). The detections were extracted by neural image detectors and classifiers, and we independently triangulate each type of sign (e.g. stop, traffic light). We find that our model is more robust to DNN misclassifications than current methods, generalizes across sign types, and can use geometric information to increase precision (e.g. Stop signs seldom occur on highways). Our algorithm outperforms our current production baseline based on k-means clustering. We show that variational inference training allows generalization by learning sign-specific parameters.