 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Tensors for Probabilistic Programming
Oct 23, 2019
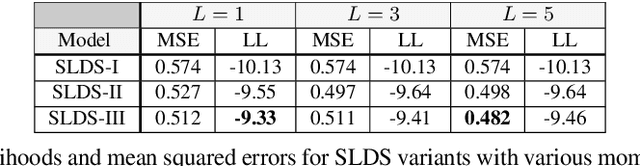
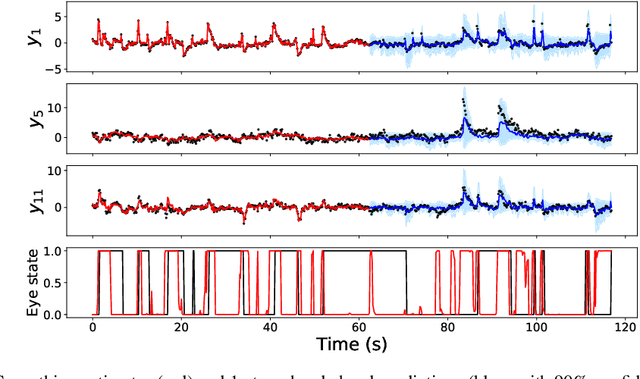
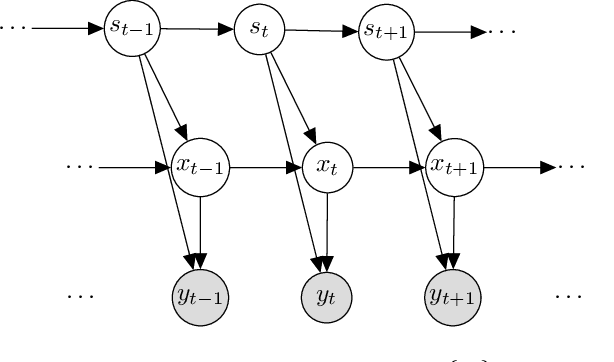
It is a significant challenge to design probabilistic programming systems that can accommodate a wide variety of inference strategies within a unified framework. Noting that the versatility of modern automatic differentiation frameworks is based in large part on the unifying concept of tensors, we describe a software abstraction --functional tensors-- that captures many of the benefits of tensors, while also being able to describe continuous probability distributions. Moreover, functional tensors are a natural candidate for generalized variable elimination and parallel-scan filtering algorithms that enable parallel exact inference for a large family of tractable modeling motifs. We demonstrate the versatility of functional tensors by integrating them into the modeling frontend and inference backend of the Pyro programming language. In experiments we show that the resulting framework enables a large variety of inference strategies, including those that mix exact and approximate inference.
Tensor Variable Elimination for Plated Factor Graphs
Feb 08, 2019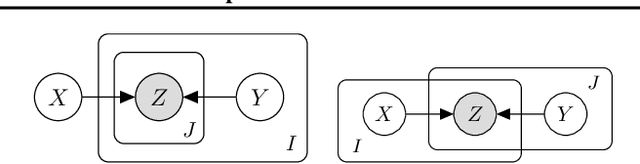
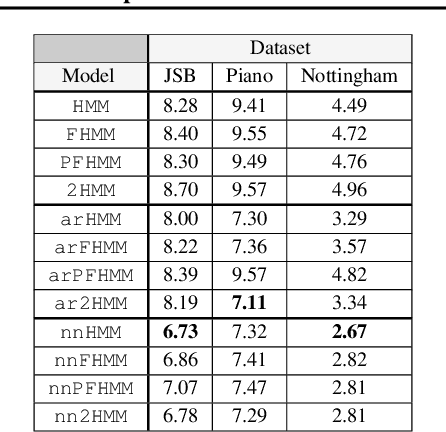
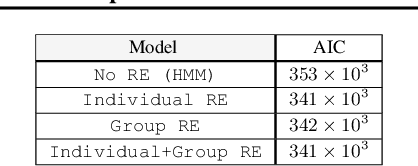
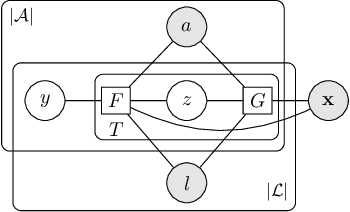
A wide class of machine learning algorithms can be reduced to variable elimination on factor graphs. While factor graphs provide a unifying notation for these algorithms, they do not provide a compact way to express repeated structure when compared to plate diagrams for directed graphical models. To exploit efficient tensor algebra in graphs with plates of variables, we generalize undirected factor graphs to plated factor graphs and variable elimination to a tensor variable elimination algorithm that operates directly on plated factor graphs. Moreover, we generalize complexity bounds based on treewidth and characterize the class of plated factor graphs for which inference is tractable. As an application, we integrate tensor variable elimination into the Pyro probabilistic programming language to enable exact inference in discrete latent variable models with repeated structure. We validate our methods with experiments on both directed and undirected graphical models, including applications to polyphonic music modeling, animal movement modeling, and latent sentiment analysis.
Joint Mapping and Calibration via Differentiable Sensor Fusion
Nov 21, 2018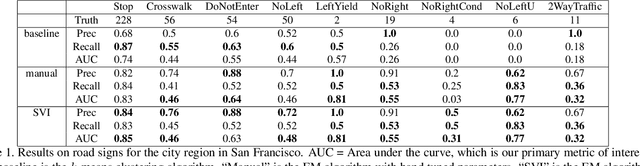


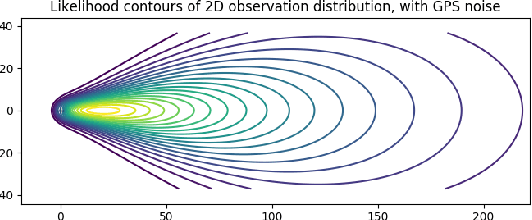
We leverage automatic differentiation (AD) and probabilistic programming languages to develop an end-to-end optimization algorithm for batch triangulation of a large number of unknown objects. Given noisy detections extracted from noisily geo-located street level imagery without depth information, we jointly estimate the number and location of objects of different types, together with parameters for sensor noise characteristics and prior distribution of objects conditioned on side information. The entire algorithm is framed as nested stochastic variational inference. An inner loop solves a soft data association problem via loopy belief propagation; a middle loop performs soft EM clustering using a regularized Newton solver (leveraging an AD framework); an outer loop backpropagates through the inner loops to train global parameters. We place priors over sensor parameters for different traffic object types, and demonstrate improvements with richer priors incorporating knowledge of the environment. We test our algorithm on detections of road signs observed by cars with mounted cameras, though in practice this technique can be used for any geo-tagged images. We assume images do not have depth information (e.g. from lidar or stereo cameras). The detections were extracted by neural image detectors and classifiers, and we independently triangulate each type of sign (e.g. stop, traffic light). We find that our model is more robust to DNN misclassifications than current methods, generalizes across sign types, and can use geometric information to increase precision (e.g. Stop signs seldom occur on highways). Our algorithm outperforms our current production baseline based on k-means clustering. We show that variational inference training allows generalization by learning sign-specific parameters.
Pyro: Deep Universal Probabilistic Programming
Oct 18, 2018


Pyro is a probabilistic programming language built on Python as a platform for developing advanced probabilistic models in AI research. To scale to large datasets and high-dimensional models, Pyro uses stochastic variational inference algorithms and probability distributions built on top of PyTorch, a modern GPU-accelerated deep learning framework. To accommodate complex or model-specific algorithmic behavior, Pyro leverages Poutine, a library of composable building blocks for modifying the behavior of probabilistic programs.
Pathwise Derivatives Beyond the Reparameterization Trick
Jul 05, 2018
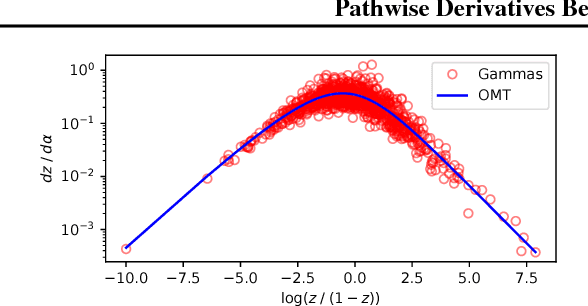
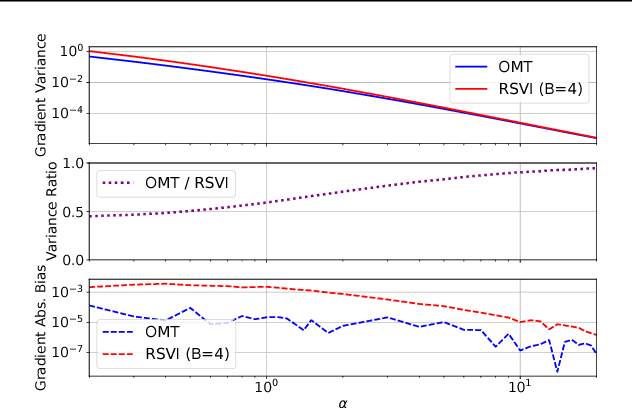
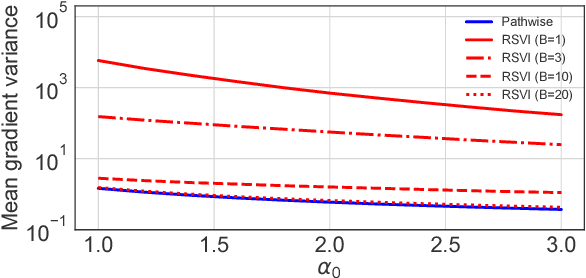
We observe that gradients computed via the reparameterization trick are in direct correspondence with solutions of the transport equation in the formalism of optimal transport. We use this perspective to compute (approximate) pathwise gradients for probability distributions not directly amenable to the reparameterization trick: Gamma, Beta, and Dirichlet. We further observe that when the reparameterization trick is applied to the Cholesky-factorized multivariate Normal distribution, the resulting gradients are suboptimal in the sense of optimal transport. We derive the optimal gradients and show that they have reduced variance in a Gaussian Process regression task. We demonstrate with a variety of synthetic experiments and stochastic variational inference tasks that our pathwise gradients are competitive with other methods.
Scaling Nonparametric Bayesian Inference via Subsample-Annealing
Feb 22, 2014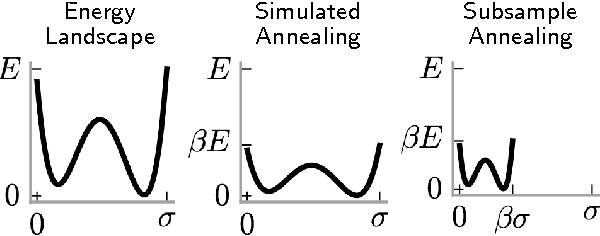
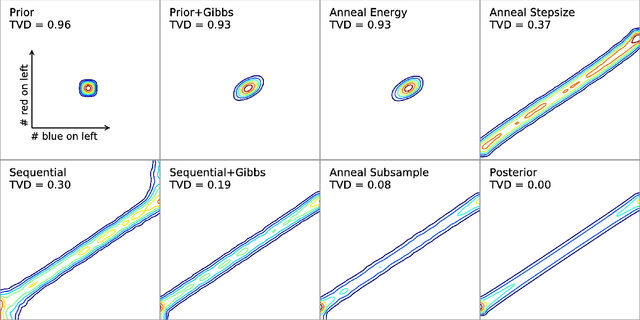
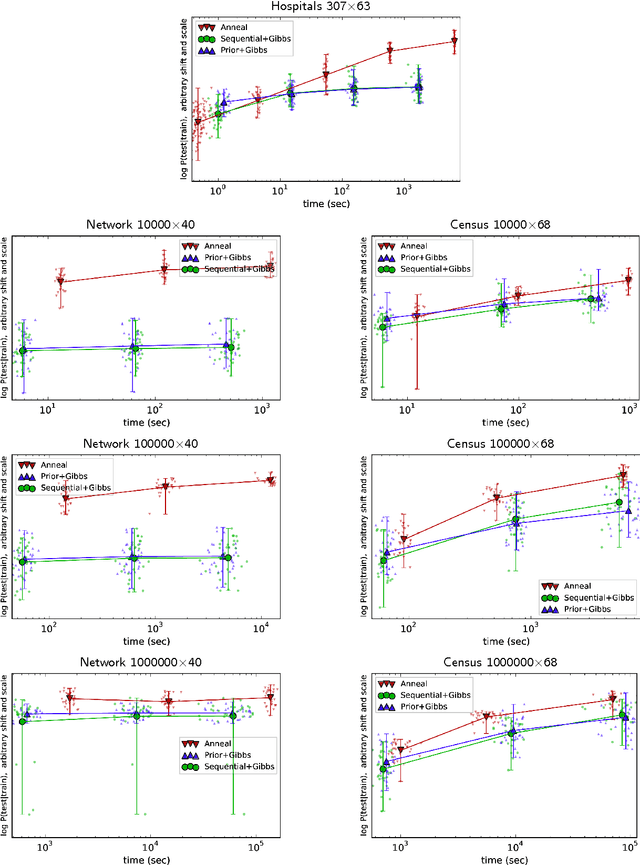
We describe an adaptation of the simulated annealing algorithm to nonparametric clustering and related probabilistic models. This new algorithm learns nonparametric latent structure over a growing and constantly churning subsample of training data, where the portion of data subsampled can be interpreted as the inverse temperature beta(t) in an annealing schedule. Gibbs sampling at high temperature (i.e., with a very small subsample) can more quickly explore sketches of the final latent state by (a) making longer jumps around latent space (as in block Gibbs) and (b) lowering energy barriers (as in simulated annealing). We prove subsample annealing speeds up mixing time N^2 -> N in a simple clustering model and exp(N) -> N in another class of models, where N is data size. Empirically subsample-annealing outperforms naive Gibbs sampling in accuracy-per-wallclock time, and can scale to larger datasets and deeper hierarchical models. We demonstrate improved inference on million-row subsamples of US Census data and network log data and a 307-row hospital rating dataset, using a Pitman-Yor generalization of the Cross Categorization model.