 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Chain-of-Thought via Latent-Variable Inference
Nov 28, 2023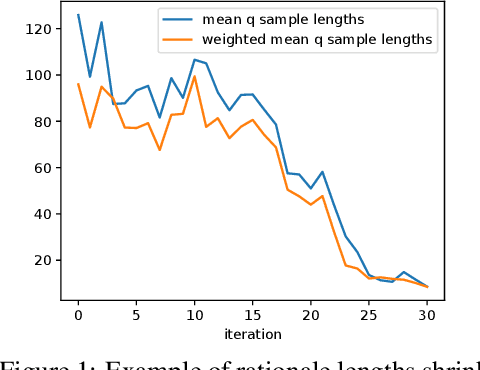
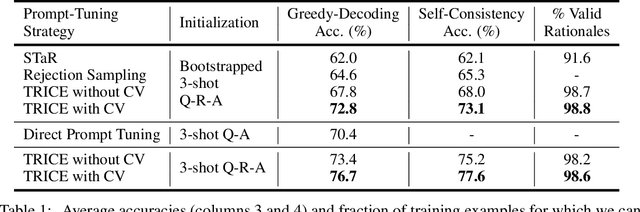
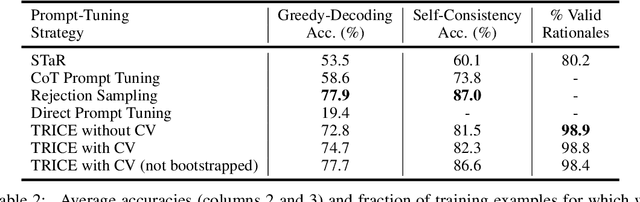
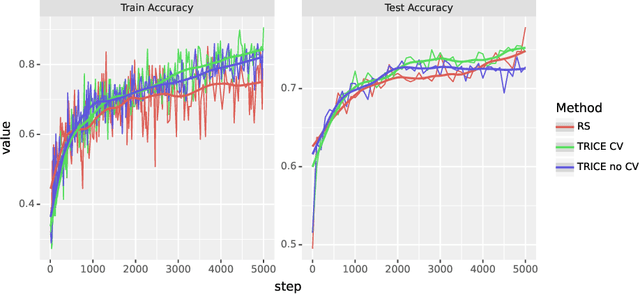
Large language models (LLMs) solve problems more accurately and interpretably when instructed to work out the answer step by step using a ``chain-of-thought'' (CoT) prompt. One can also improve LLMs' performance on a specific task by supervised fine-tuning, i.e., by using gradient ascent on some tunable parameters to maximize the average log-likelihood of correct answers from a labeled training set. Naively combining CoT with supervised tuning requires supervision not just of the correct answers, but also of detailed rationales that lead to those answers; these rationales are expensive to produce by hand. Instead, we propose a fine-tuning strategy that tries to maximize the \emph{marginal} log-likelihood of generating a correct answer using CoT prompting, approximately averaging over all possible rationales. The core challenge is sampling from the posterior over rationales conditioned on the correct answer; we address it using a simple Markov-chain Monte Carlo (MCMC) expectation-maximization (EM) algorithm inspired by the self-taught reasoner (STaR), memoized wake-sleep, Markovian score climbing, and persistent contrastive divergence. This algorithm also admits a novel control-variate technique that drives the variance of our gradient estimates to zero as the model improves. Applying our technique to GSM8K and the tasks in BIG-Bench Hard, we find that this MCMC-EM fine-tuning technique typically improves the model's accuracy on held-out examples more than STaR or prompt-tuning with or without CoT.
Reparameterized Variational Rejection Sampling
Sep 26, 2023Traditional approaches to variational inference rely on parametric families of variational distributions, with the choice of family playing a critical role in determining the accuracy of the resulting posterior approximation. Simple mean-field families often lead to poor approximations, while rich families of distributions like normalizing flows can be difficult to optimize and usually do not incorporate the known structure of the target distribution due to their black-box nature. To expand the space of flexible variational families, we revisit Variational Rejection Sampling (VRS) [Grover et al., 2018], which combines a parametric proposal distribution with rejection sampling to define a rich non-parametric family of distributions that explicitly utilizes the known target distribution. By introducing a low-variance reparameterized gradient estimator for the parameters of the proposal distribution, we make VRS an attractive inference strategy for models with continuous latent variables. We argue theoretically and demonstrate empirically that the resulting method--Reparameterized Variational Rejection Sampling (RVRS)--offers an attractive trade-off between computational cost and inference fidelity. In experiments we show that our method performs well in practice and that it is well-suited for black-box inference, especially for models with local latent variables.
On Uncertainty Calibration and Selective Generation in Probabilistic Neural Summarization: A Benchmark Study
Apr 17, 2023



Modern deep models for summarization attains impressive benchmark performance, but they are prone to generating miscalibrated predictive uncertainty. This means that they assign high confidence to low-quality predictions, leading to compromised reliability and trustworthiness in real-world applications. Probabilistic deep learning methods are common solutions to the miscalibration problem. However, their relative effectiveness in complex autoregressive summarization tasks are not well-understood. In this work, we thoroughly investigate different state-of-the-art probabilistic methods' effectiveness in improving the uncertainty quality of the neural summarization models, across three large-scale benchmarks with varying difficulty. We show that the probabilistic methods consistently improve the model's generation and uncertainty quality, leading to improved selective generation performance (i.e., abstaining from low-quality summaries) in practice. We also reveal notable failure patterns of probabilistic methods widely-adopted in NLP community (e.g., Deep Ensemble and Monte Carlo Dropout), cautioning the importance of choosing appropriate method for the data setting.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022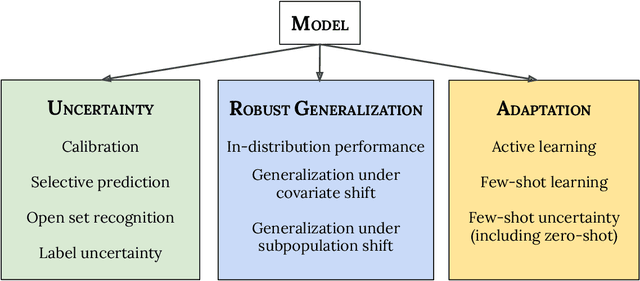

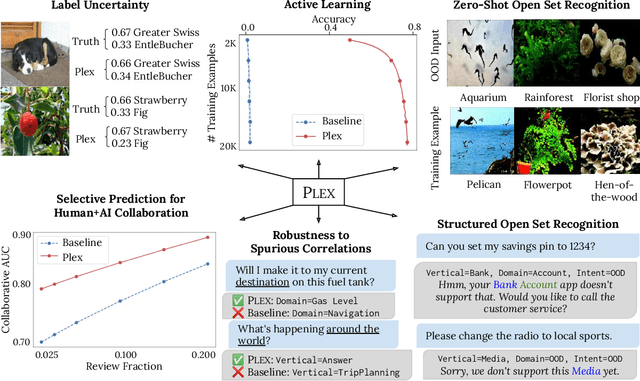

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Surrogate Likelihoods for Variational Annealed Importance Sampling
Dec 22, 2021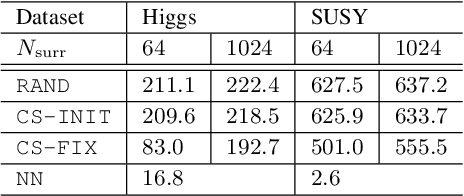
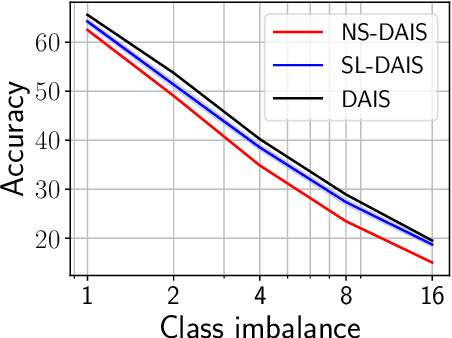

Variational inference is a powerful paradigm for approximate Bayesian inference with a number of appealing properties, including support for model learning and data subsampling. By contrast MCMC methods like Hamiltonian Monte Carlo do not share these properties but remain attractive since, contrary to parametric methods, MCMC is asymptotically unbiased. For these reasons researchers have sought to combine the strengths of both classes of algorithms, with recent approaches coming closer to realizing this vision in practice. However, supporting data subsampling in these hybrid methods can be a challenge, a shortcoming that we address by introducing a surrogate likelihood that can be learned jointly with other variational parameters. We argue theoretically that the resulting algorithm permits the user to make an intuitive trade-off between inference fidelity and computational cost. In an extensive empirical comparison we show that our method performs well in practice and that it is well-suited for black-box inference in probabilistic programming frameworks.
Composable Effects for Flexible and Accelerated Probabilistic Programming in NumPyro
Dec 24, 2019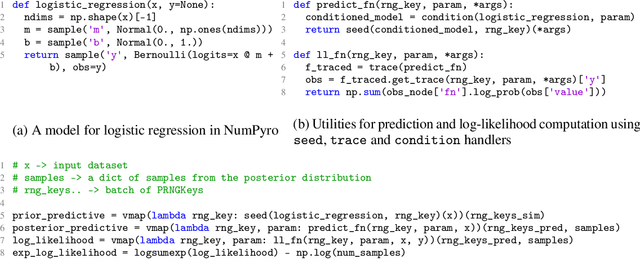
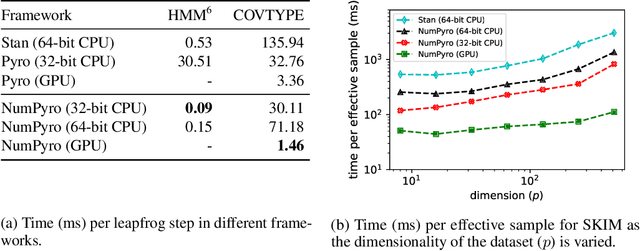

NumPyro is a lightweight library that provides an alternate NumPy backend to the Pyro probabilistic programming language with the same modeling interface, language primitives and effect handling abstractions. Effect handlers allow Pyro's modeling API to be extended to NumPyro despite its being built atop a fundamentally different JAX-based functional backend. In this work, we demonstrate the power of composing Pyro's effect handlers with the program transformations that enable hardware acceleration, automatic differentiation, and vectorization in JAX. In particular, NumPyro provides an iterative formulation of the No-U-Turn Sampler (NUTS) that can be end-to-end JIT compiled, yielding an implementation that is much faster than existing alternatives in both the small and large dataset regimes.
Functional Tensors for Probabilistic Programming
Oct 23, 2019
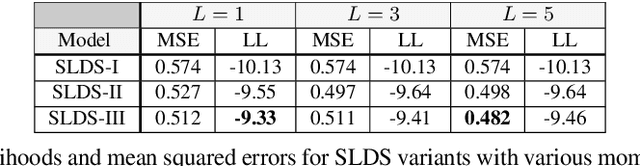
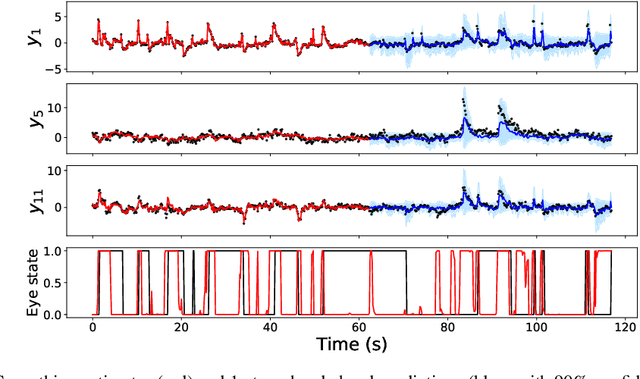
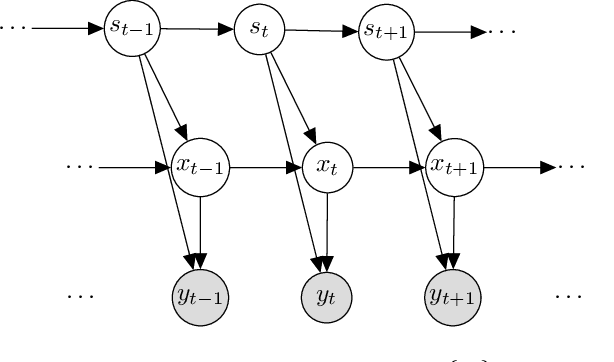
It is a significant challenge to design probabilistic programming systems that can accommodate a wide variety of inference strategies within a unified framework. Noting that the versatility of modern automatic differentiation frameworks is based in large part on the unifying concept of tensors, we describe a software abstraction --functional tensors-- that captures many of the benefits of tensors, while also being able to describe continuous probability distributions. Moreover, functional tensors are a natural candidate for generalized variable elimination and parallel-scan filtering algorithms that enable parallel exact inference for a large family of tractable modeling motifs. We demonstrate the versatility of functional tensors by integrating them into the modeling frontend and inference backend of the Pyro programming language. In experiments we show that the resulting framework enables a large variety of inference strategies, including those that mix exact and approximate inference.