 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorse Neural Networks for Uncertainty Quantification
Jul 02, 2023We introduce a new deep generative model useful for uncertainty quantification: the Morse neural network, which generalizes the unnormalized Gaussian densities to have modes of high-dimensional submanifolds instead of just discrete points. Fitting the Morse neural network via a KL-divergence loss yields 1) a (unnormalized) generative density, 2) an OOD detector, 3) a calibration temperature, 4) a generative sampler, along with in the supervised case 5) a distance aware-classifier. The Morse network can be used on top of a pre-trained network to bring distance-aware calibration w.r.t the training data. Because of its versatility, the Morse neural networks unifies many techniques: e.g., the Entropic Out-of-Distribution Detector of (Mac\^edo et al., 2021) in OOD detection, the one class Deep Support Vector Description method of (Ruff et al., 2018) in anomaly detection, or the Contrastive One Class classifier in continuous learning (Sun et al., 2021). The Morse neural network has connections to support vector machines, kernel methods, and Morse theory in topology.
Neural Spline Search for Quantile Probabilistic Modeling
Jan 12, 2023Accurate estimation of output quantiles is crucial in many use cases, where it is desired to model the range of possibility. Modeling target distribution at arbitrary quantile levels and at arbitrary input attribute levels are important to offer a comprehensive picture of the data, and requires the quantile function to be expressive enough. The quantile function describing the target distribution using quantile levels is critical for quantile regression. Although various parametric forms for the distributions (that the quantile function specifies) can be adopted, an everlasting problem is selecting the most appropriate one that can properly approximate the data distributions. In this paper, we propose a non-parametric and data-driven approach, Neural Spline Search (NSS), to represent the observed data distribution without parametric assumptions. NSS is flexible and expressive for modeling data distributions by transforming the inputs with a series of monotonic spline regressions guided by symbolic operators. We demonstrate that NSS outperforms previous methods on synthetic, real-world regression and time-series forecasting tasks.
Benchmarking Bayesian Deep Learning on Diabetic Retinopathy Detection Tasks
Nov 23, 2022Bayesian deep learning seeks to equip deep neural networks with the ability to precisely quantify their predictive uncertainty, and has promised to make deep learning more reliable for safety-critical real-world applications. Yet, existing Bayesian deep learning methods fall short of this promise; new methods continue to be evaluated on unrealistic test beds that do not reflect the complexities of downstream real-world tasks that would benefit most from reliable uncertainty quantification. We propose the RETINA Benchmark, a set of real-world tasks that accurately reflect such complexities and are designed to assess the reliability of predictive models in safety-critical scenarios. Specifically, we curate two publicly available datasets of high-resolution human retina images exhibiting varying degrees of diabetic retinopathy, a medical condition that can lead to blindness, and use them to design a suite of automated diagnosis tasks that require reliable predictive uncertainty quantification. We use these tasks to benchmark well-established and state-of-the-art Bayesian deep learning methods on task-specific evaluation metrics. We provide an easy-to-use codebase for fast and easy benchmarking following reproducibility and software design principles. We provide implementations of all methods included in the benchmark as well as results computed over 100 TPU days, 20 GPU days, 400 hyperparameter configurations, and evaluation on at least 6 random seeds each.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022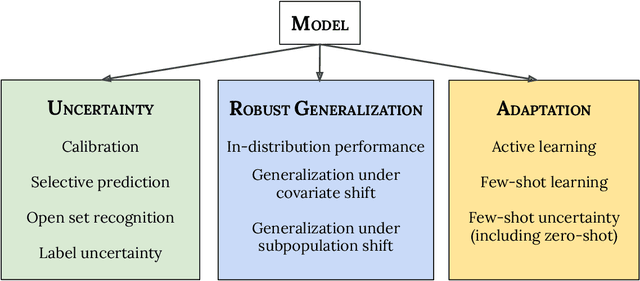

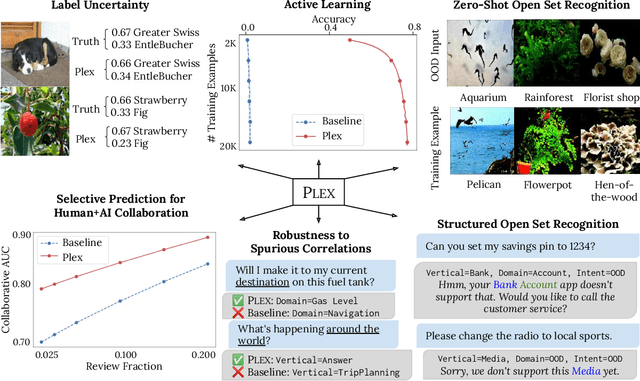

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021
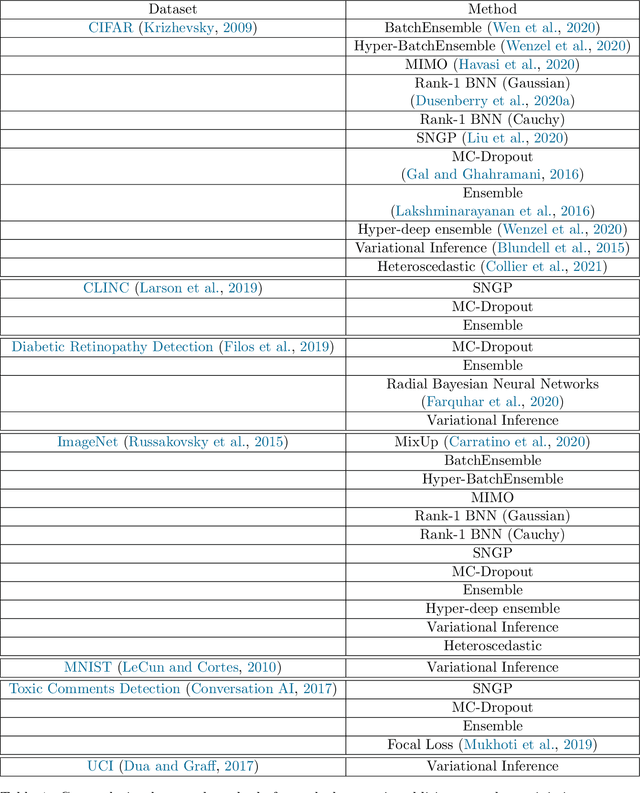
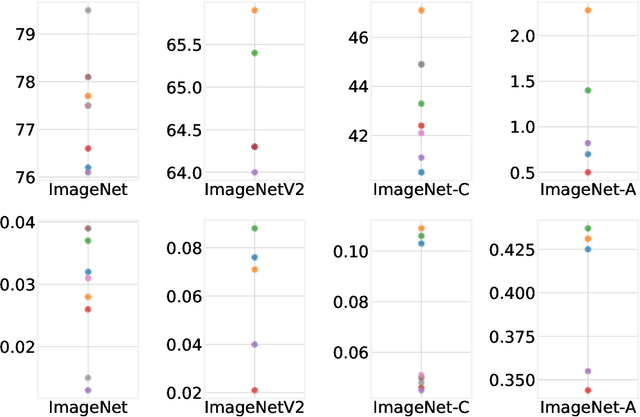
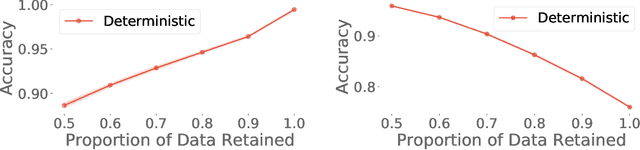
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.
Combining Ensembles and Data Augmentation can Harm your Calibration
Oct 19, 2020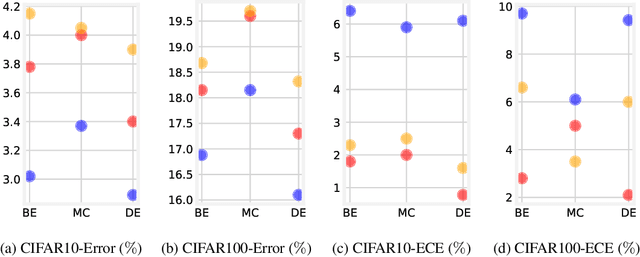
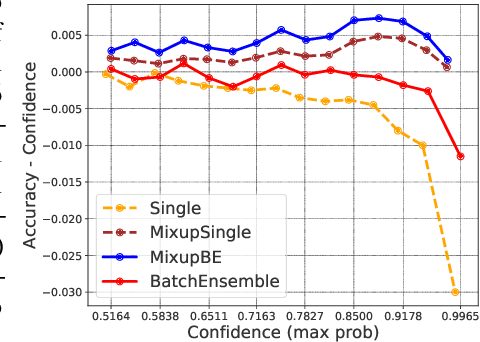
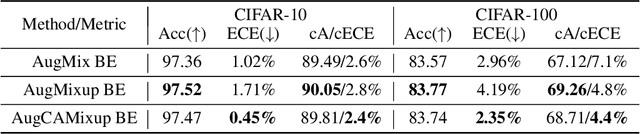
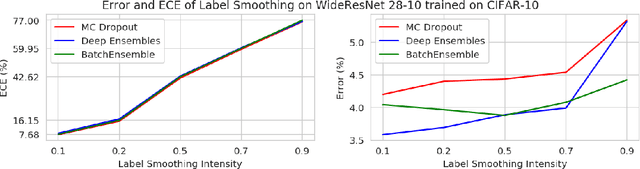
Ensemble methods which average over multiple neural network predictions are a simple approach to improve a model's calibration and robustness. Similarly, data augmentation techniques, which encode prior information in the form of invariant feature transformations, are effective for improving calibration and robustness. In this paper, we show a surprising pathology: combining ensembles and data augmentation can harm model calibration. This leads to a trade-off in practice, whereby improved accuracy by combining the two techniques comes at the expense of calibration. On the other hand, selecting only one of the techniques ensures good uncertainty estimates at the expense of accuracy. We investigate this pathology and identify a compounding under-confidence among methods which marginalize over sets of weights and data augmentation techniques which soften labels. Finally, we propose a simple correction, achieving the best of both worlds with significant accuracy and calibration gains over using only ensembles or data augmentation individually. Applying the correction produces new state-of-the art in uncertainty calibration across CIFAR-10, CIFAR-100, and ImageNet.
Efficient and Scalable Bayesian Neural Nets with Rank-1 Factors
May 14, 2020
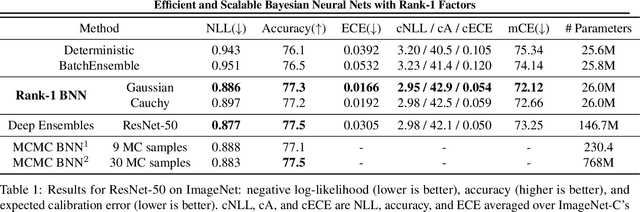
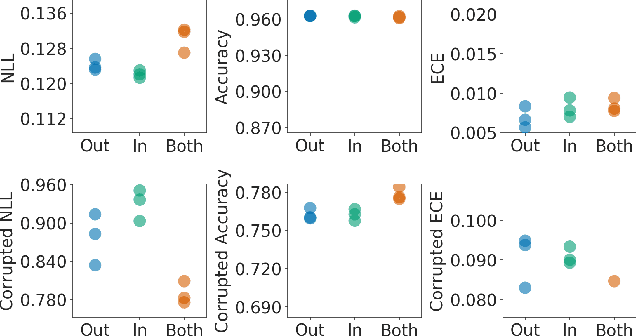
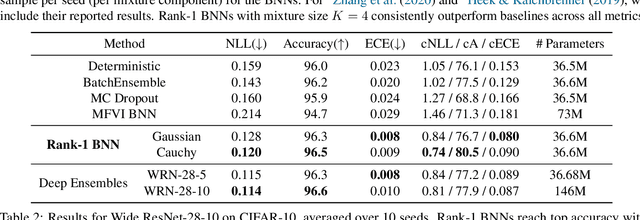
Bayesian neural networks (BNNs) demonstrate promising success in improving the robustness and uncertainty quantification of modern deep learning. However, they generally struggle with underfitting at scale and parameter efficiency. On the other hand, deep ensembles have emerged as alternatives for uncertainty quantification that, while outperforming BNNs on certain problems, also suffer from efficiency issues. It remains unclear how to combine the strengths of these two approaches and remediate their common issues. To tackle this challenge, we propose a rank-1 parameterization of BNNs, where each weight matrix involves only a distribution on a rank-1 subspace. We also revisit the use of mixture approximate posteriors to capture multiple modes, where unlike typical mixtures, this approach admits a significantly smaller memory increase (e.g., only a 0.4% increase for a ResNet-50 mixture of size 10). We perform a systematic empirical study on the choices of prior, variational posterior, and methods to improve training. For ResNet-50 on ImageNet, Wide ResNet 28-10 on CIFAR-10/100, and an RNN on MIMIC-III, rank-1 BNNs achieve state-of-the-art performance across log-likelihood, accuracy, and calibration on the test sets and out-of-distribution variants.
Graph Convolutional Transformer: Learning the Graphical Structure of Electronic Health Records
Jun 28, 2019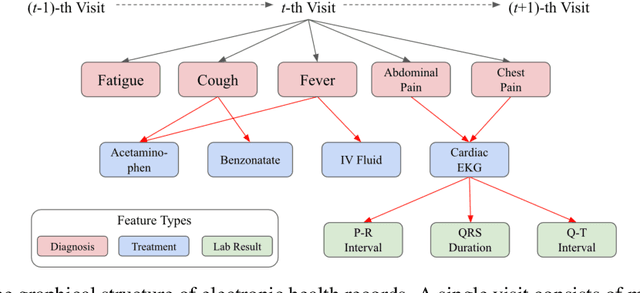

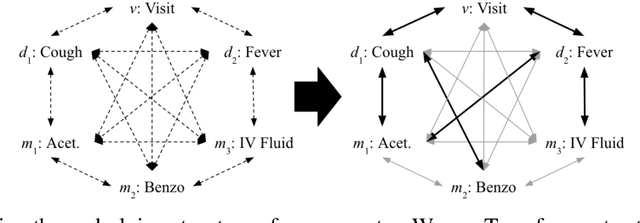
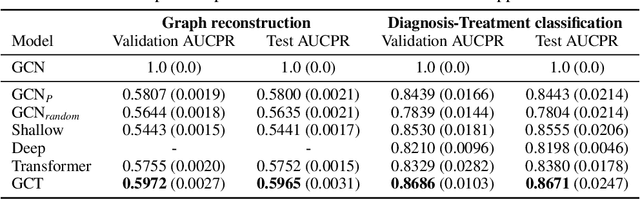
Effective modeling of electronic health records (EHR) is rapidly becoming an important topic in both academia and industry. A recent study showed that utilizing the graphical structure underlying EHR data (e.g. relationship between diagnoses and treatments) improves the performance of prediction tasks such as heart failure diagnosis prediction. However, EHR data do not always contain complete structure information. Moreover, when it comes to claims data, structure information is completely unavailable to begin with. Under such circumstances, can we still do better than just treating EHR data as a flat-structured bag-of-features? In this paper, we study the possibility of utilizing the implicit structure of EHR by using the Transformer for prediction tasks on EHR data. Specifically, we argue that the Transformer is a suitable model to learn the hidden EHR structure, and propose the Graph Convolutional Transformer, which uses data statistics to guide the structure learning process. Our model empirically demonstrated superior prediction performance to previous approaches on both synthetic data and publicly available EHR data on encounter-based prediction tasks such as graph reconstruction and readmission prediction, indicating that it can serve as an effective general-purpose representation learning algorithm for EHR data.
Analyzing the Role of Model Uncertainty for Electronic Health Records
Jun 10, 2019
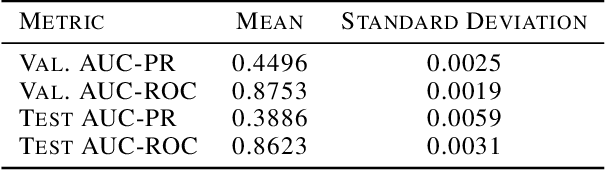
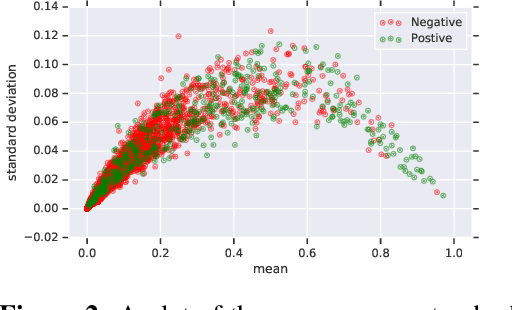
In medicine, both ethical and monetary costs of incorrect predictions can be significant, and the complexity of the problems often necessitates increasingly complex models. Recent work has shown that changing just the random seed is enough for otherwise well-tuned deep neural networks to vary in their individual predicted probabilities. In light of this, we investigate the role of model uncertainty methods in the medical domain. Using RNN ensembles and various Bayesian RNNs, we show that population-level metrics, such as AUC-PR, AUC-ROC, log-likelihood, and calibration error, do not capture model uncertainty. Meanwhile, the presence of significant variability in patient-specific predictions and optimal decisions motivates the need for capturing model uncertainty. Understanding the uncertainty for individual patients is an area with clear clinical impact, such as determining when a model decision is likely to be brittle. We further show that RNNs with only Bayesian embeddings can be a more efficient way to capture model uncertainty compared to ensembles, and we analyze how model uncertainty is impacted across individual input features and patient subgroups.
Bayesian Layers: A Module for Neural Network Uncertainty
Dec 11, 2018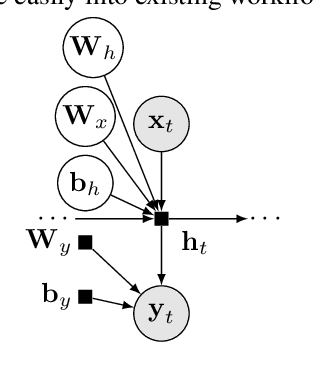


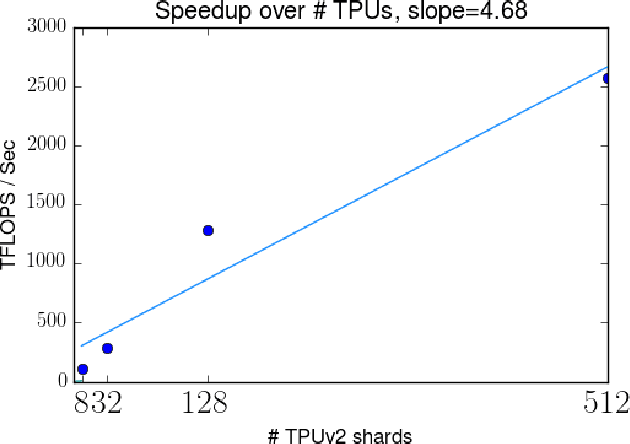
We describe Bayesian Layers, a module designed for fast experimentation with neural network uncertainty. It extends neural network libraries with layers capturing uncertainty over weights (Bayesian neural nets), pre-activation units (dropout), activations ("stochastic output layers"), and the function itself (Gaussian processes). With reversible layers, one can also propagate uncertainty from input to output such as for flow-based distributions and constant-memory backpropagation. Bayesian Layers are a drop-in replacement for other layers, maintaining core features that one typically desires for experimentation. As demonstration, we fit a 10-billion parameter "Bayesian Transformer" on 512 TPUv2 cores, which replaces attention layers with their Bayesian counterpart.