 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the City Teaches the Car: Label-Free 3D Perception from Infrastructure
Mar 17, 2026Building robust 3D perception for self-driving still relies heavily on large-scale data collection and manual annotation, yet this paradigm becomes impractical as deployment expands across diverse cities and regions. Meanwhile, modern cities are increasingly instrumented with roadside units (RSUs), static sensors deployed along roads and at intersections to monitor traffic. This raises a natural question: can the city itself help train the vehicle? We propose infrastructure-taught, label-free 3D perception, a paradigm in which RSUs act as stationary, unsupervised teachers for ego vehicles. Leveraging their fixed viewpoints and repeated observations, RSUs learn local 3D detectors from unlabeled data and broadcast predictions to passing vehicles, which are aggregated as pseudo-label supervision for training a standalone ego detector. The resulting model requires no infrastructure or communication at test time. We instantiate this idea as a fully label-free three-stage pipeline and conduct a concept-and-feasibility study in a CARLA-based multi-agent environment. With CenterPoint, our pipeline achieves 82.3% AP for detecting vehicles, compared to a fully supervised ego upper bound of 94.4%. We further systematically analyze each stage, evaluate its scalability, and demonstrate complementarity with existing ego-centric label-free methods. Together, these results suggest that city infrastructure itself can potentially provide a scalable supervisory signal for autonomous vehicles, positioning infrastructure-taught learning as a promising orthogonal paradigm for reducing annotation cost in 3D perception.
M$^3$-ACE: Rectifying Visual Perception in Multimodal Math Reasoning via Multi-Agentic Context Engineering
Mar 09, 2026Multimodal large language models have recently shown promising progress in visual mathematical reasoning. However, their performance is often limited by a critical yet underexplored bottleneck: inaccurate visual perception. Through systematic analysis, we find that the most failures originate from incorrect or incomplete visual evidence extraction rather than deficiencies in reasoning capability. Moreover, models tend to remain overly confident in their initial perceptions, making standard strategies such as prompt engineering, multi-round self-reflection, or posterior guidance insufficient to reliably correct errors. To address this limitation, we propose M3-ACE, a multi-agentic context engineering framework designed to rectify visual perception in multimodal math reasoning. Instead of directly aggregating final answers, our approach decouples perception and reasoning by dynamically maintaining a shared context centered on visual evidence lists. Multiple agents collaboratively contribute complementary observations, enabling the system to expose inconsistencies and recover missing perceptual information. To support stable multi-turn collaboration, we further introduce two lightweight tools: a Summary Tool that organizes evidence from different agents into consistent, complementary, and conflicting components, and a Refine Tool that filters unreliable samples and guides iterative correction. Extensive experiments demonstrate that M3-ACE substantially improves visual mathematical reasoning performance across multiple benchmarks. Our method establishes new state-of-the-art results 89.1 on the MathVision benchmark and achieves consistent improvements on other related datasets, including MathVista and MathVerse. These results highlight the importance of perception-centric multi-agent collaboration for advancing multimodal reasoning systems.
Joint Optimization of Flexible Antenna Array Shape and Beamforming for Secure Communication
Feb 27, 2026Flexible antenna arrays (FAAs) can physically reshape their geometry to add new spatial degrees of freedom, whereas transmit beamforming adjusts the complex element weights to electronically steer and shape the array's radiation pattern, thereby significantly improving communication performance. This paper is the first to explore the integration of FAA geometry control and beamforming for physical layer security enhancement, where a base station equipped with an FAA communicates with a legitimate user in the presence of passive eavesdroppers. To safeguard confidential transmissions, we formulate a new secrecy rate maximization problem that jointly optimizes the transmit beamforming vector and a continuous FAA shape control parameter. Due to the non convex nature of the problem, an alternating optimization algorithm is developed to decompose the joint design into tractable subproblems, which are solved iteratively to refine both the FAA geometry and beamforming strategy. Simulation results confirm that the proposed joint optimization framework significantly outperforms conventional fixed shape or beamforming only schemes, demonstrating the potential of FAA enabled reconfigurability for secure wireless communications.
PieArena: Frontier Language Agents Achieve MBA-Level Negotiation Performance and Reveal Novel Behavioral Differences
Feb 05, 2026We present an in-depth evaluation of LLMs' ability to negotiate, a central business task that requires strategic reasoning, theory of mind, and economic value creation. To do so, we introduce PieArena, a large-scale negotiation benchmark grounded in multi-agent interactions over realistic scenarios drawn from an MBA negotiation course at an elite business school. We find systematic evidence of AGI-level performance in which a representative frontier agent (GPT-5) matches or outperforms trained business-school students, despite a semester of general negotiation instruction and targeted coaching immediately prior to the task. We further study the effects of joint-intentionality agentic scaffolding and find asymmetric gains, with large improvements for mid- and lower-tier LMs and diminishing returns for frontier LMs. Beyond deal outcomes, PieArena provides a multi-dimensional negotiation behavioral profile, revealing novel cross-model heterogeneity, masked by deal-outcome-only benchmarks, in deception, computation accuracy, instruction compliance, and perceived reputation. Overall, our results suggest that frontier language agents are already intellectually and psychologically capable of deployment in high-stakes economic settings, but deficiencies in robustness and trustworthiness remain open challenges.
Towards the Holographic Characteristic of LLMs for Efficient Short-text Generation
Jan 30, 2026The recent advancements in Large Language Models (LLMs) have attracted interest in exploring their in-context learning abilities and chain-of-thought capabilities. However, there are few studies investigating the specific traits related to the powerful generation capacity of LLMs. This paper aims to delve into the generation characteristics exhibited by LLMs. Through our investigation, we have discovered that language models tend to capture target-side keywords at the beginning of the generation process. We name this phenomenon the Holographic Characteristic of language models. For the purpose of exploring this characteristic and further improving the inference efficiency of language models, we propose a plugin called HOLO, which leverages the Holographic Characteristic to extract target-side keywords from language models within a limited number of generation steps and complements the sentence with a parallel lexically constrained text generation method. To verify the effectiveness of HOLO, we conduct massive experiments on language models of varying architectures and scales in the short-text generation scenario. The results demonstrate that HOLO achieves comparable performance to the baselines in terms of both automatic and human-like evaluation metrics and highlight the potential of the Holographic Characteristic.
Ternary Spiking Neural Networks Enhanced by Complemented Neurons and Membrane Potential Aggregation
Jan 22, 2026Spiking Neural Networks (SNNs) are promising energy-efficient models and powerful framworks of modeling neuron dynamics. However, existing binary spiking neurons exhibit limited biological plausibilities and low information capacity. Recently developed ternary spiking neuron possesses higher consistency with biological principles (i.e. excitation-inhibition balance mechanism). Despite of this, the ternary spiking neuron suffers from defects including iterative information loss, temporal gradient vanishing and irregular distributions of membrane potentials. To address these issues, we propose Complemented Ternary Spiking Neuron (CTSN), a novel ternary spiking neuron model that incorporates an learnable complemental term to store information from historical inputs. CTSN effectively improves the deficiencies of ternary spiking neuron, while the embedded learnable factors enable CTSN to adaptively adjust neuron dynamics, providing strong neural heterogeneity. Furthermore, based on the temporal evolution features of ternary spiking neurons' membrane potential distributions, we propose the Temporal Membrane Potential Regularization (TMPR) training method. TMPR introduces time-varying regularization strategy utilizing membrane potentials, furhter enhancing the training process by creating extra backpropagation paths. We validate our methods through extensive experiments on various datasets, demonstrating remarkable performance advances.
Enhancing LLM-Based Data Annotation with Error Decomposition
Jan 17, 2026Large language models offer a scalable alternative to human coding for data annotation tasks, enabling the scale-up of research across data-intensive domains. While LLMs are already achieving near-human accuracy on objective annotation tasks, their performance on subjective annotation tasks, such as those involving psychological constructs, is less consistent and more prone to errors. Standard evaluation practices typically collapse all annotation errors into a single alignment metric, but this simplified approach may obscure different kinds of errors that affect final analytical conclusions in different ways. Here, we propose a diagnostic evaluation paradigm that incorporates a human-in-the-loop step to separate task-inherent ambiguity from model-driven inaccuracies and assess annotation quality in terms of their potential downstream impacts. We refine this paradigm on ordinal annotation tasks, which are common in subjective annotation. The refined paradigm includes: (1) a diagnostic taxonomy that categorizes LLM annotation errors along two dimensions: source (model-specific vs. task-inherent) and type (boundary ambiguity vs. conceptual misidentification); (2) a lightweight human annotation test to estimate task-inherent ambiguity from LLM annotations; and (3) a computational method to decompose observed LLM annotation errors following our taxonomy. We validate this paradigm on four educational annotation tasks, demonstrating both its conceptual validity and practical utility. Theoretically, our work provides empirical evidence for why excessively high alignment is unrealistic in specific annotation tasks and why single alignment metrics inadequately reflect the quality of LLM annotations. In practice, our paradigm can be a low-cost diagnostic tool that assesses the suitability of a given task for LLM annotation and provides actionable insights for further technical optimization.
Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
Jan 15, 2026Multi-agent systems have evolved into practical LLM-driven collaborators for many applications, gaining robustness from diversity and cross-checking. However, multi-agent RL (MARL) training is resource-intensive and unstable: co-adapting teammates induce non-stationarity, and rewards are often sparse and high-variance. Therefore, we introduce \textbf{Multi-Agent Test-Time Reinforcement Learning (MATTRL)}, a framework that injects structured textual experience into multi-agent deliberation at inference time. MATTRL forms a multi-expert team of specialists for multi-turn discussions, retrieves and integrates test-time experiences, and reaches consensus for final decision-making. We also study credit assignment for constructing a turn-level experience pool, then reinjecting it into the dialogue. Across challenging benchmarks in medicine, math, and education, MATTRL improves accuracy by an average of 3.67\% over a multi-agent baseline, and by 8.67\% over comparable single-agent baselines. Ablation studies examine different credit-assignment schemes and provide a detailed comparison of how they affect training outcomes. MATTRL offers a stable, effective and efficient path to distribution-shift-robust multi-agent reasoning without tuning.
Beyond Redundancy: Diverse and Specialized Multi-Expert Sparse Autoencoder
Nov 07, 2025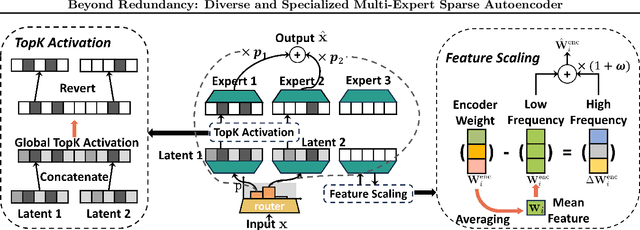
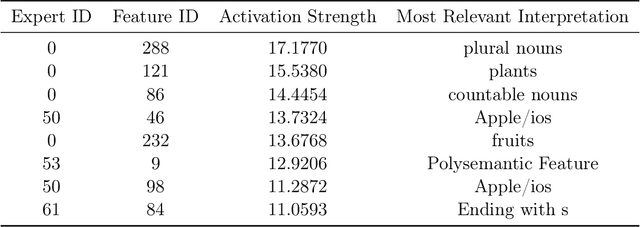
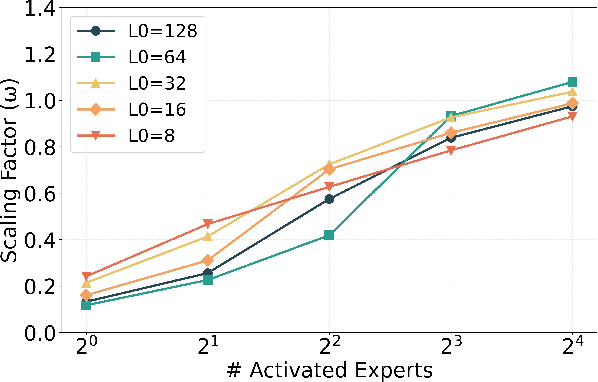
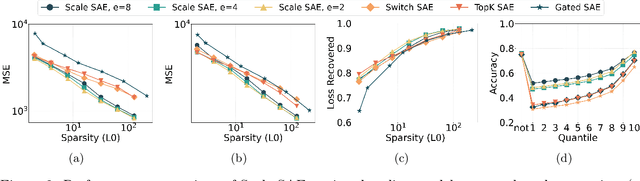
Sparse autoencoders (SAEs) have emerged as a powerful tool for interpreting large language models (LLMs) by decomposing token activations into combinations of human-understandable features. While SAEs provide crucial insights into LLM explanations, their practical adoption faces a fundamental challenge: better interpretability demands that SAEs' hidden layers have high dimensionality to satisfy sparsity constraints, resulting in prohibitive training and inference costs. Recent Mixture of Experts (MoE) approaches attempt to address this by partitioning SAEs into narrower expert networks with gated activation, thereby reducing computation. In a well-designed MoE, each expert should focus on learning a distinct set of features. However, we identify a \textit{critical limitation} in MoE-SAE: Experts often fail to specialize, which means they frequently learn overlapping or identical features. To deal with it, we propose two key innovations: (1) Multiple Expert Activation that simultaneously engages semantically weighted expert subsets to encourage specialization, and (2) Feature Scaling that enhances diversity through adaptive high-frequency scaling. Experiments demonstrate a 24\% lower reconstruction error and a 99\% reduction in feature redundancy compared to existing MoE-SAE methods. This work bridges the interpretability-efficiency gap in LLM analysis, allowing transparent model inspection without compromising computational feasibility.
EvHand-FPV: Efficient Event-Based 3D Hand Tracking from First-Person View
Sep 17, 2025Hand tracking holds great promise for intuitive interaction paradigms, but frame-based methods often struggle to meet the requirements of accuracy, low latency, and energy efficiency, especially in resource-constrained settings such as Extended Reality (XR) devices. Event cameras provide $\mu$s-level temporal resolution at mW-level power by asynchronously sensing brightness changes. In this work, we present EvHand-FPV, a lightweight framework for egocentric First-Person-View 3D hand tracking from a single event camera. We construct an event-based FPV dataset that couples synthetic training data with 3D labels and real event data with 2D labels for evaluation to address the scarcity of egocentric benchmarks. EvHand-FPV also introduces a wrist-based region of interest (ROI) that localizes the hand region via geometric cues, combined with an end-to-end mapping strategy that embeds ROI offsets into the network to reduce computation without explicit reconstruction, and a multi-task learning strategy with an auxiliary geometric feature head that improves representations without test-time overhead. On our real FPV test set, EvHand-FPV improves 2D-AUCp from 0.77 to 0.85 while reducing parameters from 11.2M to 1.2M by 89% and FLOPs per inference from 1.648G to 0.185G by 89%. It also maintains a competitive 3D-AUCp of 0.84 on synthetic data. These results demonstrate accurate and efficient egocentric event-based hand tracking suitable for on-device XR applications. The dataset and code are available at https://github.com/zen5x5/EvHand-FPV.