 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOPPO: Rethinking PPO for Multi-Task Reinforcement Learning with Critic Balancing
May 12, 2026Soft Actor-Critic (SAC) and its variants dominate Multi-Task Reinforcement Learning (MTRL) due to their off-policy sample efficiency, while on-policy methods such as Proximal Policy Optimization (PPO) remain underexplored. We diagnose that PPO in MTRL suffers from a previously overlooked issue: critic-side gradient ill-conditioning, which may cause tail tasks to stall while easy tasks dominate the value function's updates. To address this, we propose TOPPO (Tail-Optimized PPO), a reformulation of PPO via Critic Balancing -- a set of modules that improve gradient conditioning and balance learning dynamics across tasks. Unlike prior approaches that rely on modular architectures or large models, TOPPO targets the optimization bottleneck within PPO itself. Empirically, TOPPO achieves stronger mean and tail-task performance than published SAC-family and ARS-family baselines while using substantially fewer parameters and environment steps on Meta-World+ benchmark. Notably, TOPPO matches or surpasses strong SAC baselines early in training and maintains superior performance at full budget. Ablations confirm the effectiveness of each module in TOPPO and provide insights into their interactions. Our results demonstrate that, with proper optimization, on-policy methods can rival or exceed off-policy approaches in MTRL, challenging the prevailing reliance on SAC and highlighting critic-side gradient conditioning as the central bottleneck.
A Theoretical Analysis of Compositional Generalization in Neural Networks: A Necessary and Sufficient Condition
May 05, 2025



Compositional generalization is a crucial property in artificial intelligence, enabling models to handle novel combinations of known components. While most deep learning models lack this capability, certain models succeed in specific tasks, suggesting the existence of governing conditions. This paper derives a necessary and sufficient condition for compositional generalization in neural networks. Conceptually, it requires that (i) the computational graph matches the true compositional structure, and (ii) components encode just enough information in training. The condition is supported by mathematical proofs. This criterion combines aspects of architecture design, regularization, and training data properties. A carefully designed minimal example illustrates an intuitive understanding of the condition. We also discuss the potential of the condition for assessing compositional generalization before training. This work is a fundamental theoretical study of compositional generalization in neural networks.
LLM-Sketch: Enhancing Network Sketches with LLM
Feb 11, 2025Network stream mining is fundamental to many network operations. Sketches, as compact data structures that offer low memory overhead with bounded accuracy, have emerged as a promising solution for network stream mining. Recent studies attempt to optimize sketches using machine learning; however, these approaches face the challenges of lacking adaptivity to dynamic networks and incurring high training costs. In this paper, we propose LLM-Sketch, based on the insight that fields beyond the flow IDs in packet headers can also help infer flow sizes. By using a two-tier data structure and separately recording large and small flows, LLM-Sketch improves accuracy while minimizing memory usage. Furthermore, it leverages fine-tuned large language models (LLMs) to reliably estimate flow sizes. We evaluate LLM-Sketch on three representative tasks, and the results demonstrate that LLM-Sketch outperforms state-of-the-art methods by achieving a $7.5\times$ accuracy improvement.
On the Expressive Power of Modern Hopfield Networks
Dec 07, 2024Modern Hopfield networks (MHNs) have emerged as powerful tools in deep learning, capable of replacing components such as pooling layers, LSTMs, and attention mechanisms. Recent advancements have enhanced their storage capacity, retrieval speed, and error rates. However, the fundamental limits of their computational expressiveness remain unexplored. Understanding the expressive power of MHNs is crucial for optimizing their integration into deep learning architectures. In this work, we establish rigorous theoretical bounds on the computational capabilities of MHNs using circuit complexity theory. Our key contribution is that we show that MHNs are $\mathsf{DLOGTIME}$-uniform $\mathsf{TC}^0$. Hence, unless $\mathsf{TC}^0 = \mathsf{NC}^1$, a $\mathrm{poly}(n)$-precision modern Hopfield networks with a constant number of layers and $O(n)$ hidden dimension cannot solve $\mathsf{NC}^1$-hard problems such as the undirected graph connectivity problem and the tree isomorphism problem. We also extended our results to Kernelized Hopfield Networks. These results demonstrate the limitation in the expressive power of the modern Hopfield networks. Moreover, Our theoretical analysis provides insights to guide the development of new Hopfield-based architectures.
A Short Survey of Systematic Generalization
Nov 22, 2022This survey includes systematic generalization and a history of how machine learning addresses it. We aim to summarize and organize the related information of both conventional and recent improvements. We first look at the definition of systematic generalization, then introduce Classicist and Connectionist. We then discuss different types of Connectionists and how they approach the generalization. Two crucial problems of variable binding and causality are discussed. We look into systematic generalization in language, vision, and VQA fields. Recent improvements from different aspects are discussed. Systematic generalization has a long history in artificial intelligence. We could cover only a small portion of many contributions. We hope this paper provides a background and is beneficial for discoveries in future work.
On a Built-in Conflict between Deep Learning and Systematic Generalization
Aug 24, 2022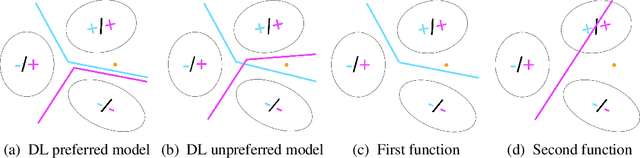
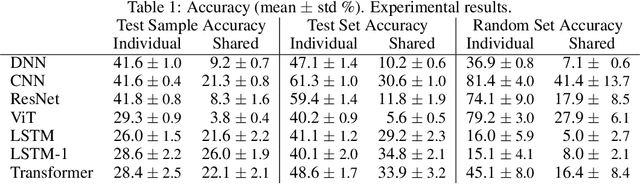
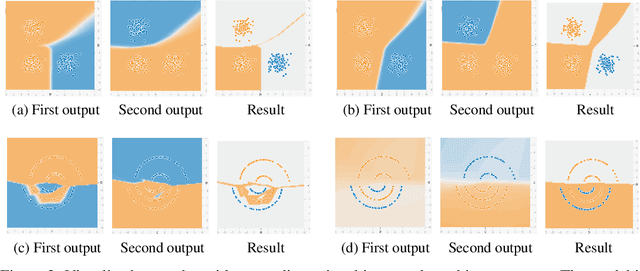
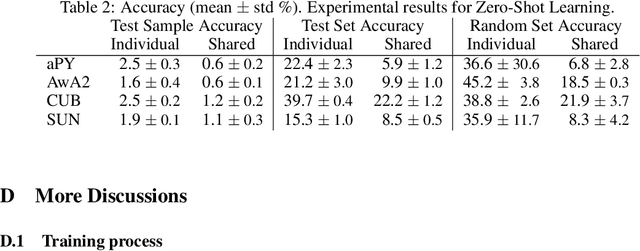
In this paper, we hypothesize that internal function sharing is one of the reasons to weaken o.o.d. or systematic generalization in deep learning for classification tasks. Under equivalent prediction, a model partitions an input space into multiple parts separated by boundaries. The function sharing prefers to reuse boundaries, leading to fewer parts for new outputs, which conflicts with systematic generalization. We show such phenomena in standard deep learning models, such as fully connected, convolutional, residual networks, LSTMs, and (Vision) Transformers. We hope this study provides novel insights into systematic generalization and forms a basis for new research directions.
Efficiently Disentangle Causal Representations
Jan 06, 2022


This paper proposes an efficient approach to learning disentangled representations with causal mechanisms based on the difference of conditional probabilities in original and new distributions. We approximate the difference with models' generalization abilities so that it fits in the standard machine learning framework and can be efficiently computed. In contrast to the state-of-the-art approach, which relies on the learner's adaptation speed to new distribution, the proposed approach only requires evaluating the model's generalization ability. We provide a theoretical explanation for the advantage of the proposed method, and our experiments show that the proposed technique is 1.9--11.0$\times$ more sample efficient and 9.4--32.4 times quicker than the previous method on various tasks. The source code is available at \url{https://github.com/yuanpeng16/EDCR}.
Concepts, Properties and an Approach for Compositional Generalization
Feb 08, 2021


Compositional generalization is the capacity to recognize and imagine a large amount of novel combinations from known components. It is a key in human intelligence, but current neural networks generally lack such ability. This report connects a series of our work for compositional generalization, and summarizes an approach. The first part contains concepts and properties. The second part looks into a machine learning approach. The approach uses architecture design and regularization to regulate information of representations. This report focuses on basic ideas with intuitive and illustrative explanations. We hope this work would be helpful to clarify fundamentals of compositional generalization and lead to advance artificial intelligence.
Multi-AI competing and winning against humans in iterated Rock-Paper-Scissors game
Mar 15, 2020
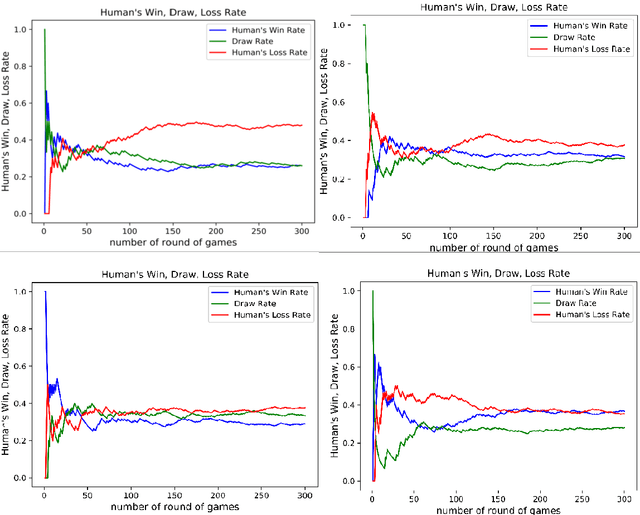
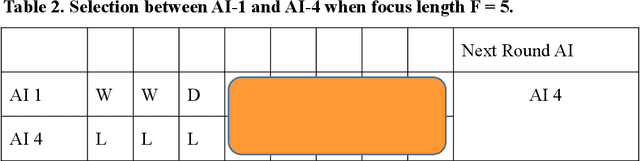
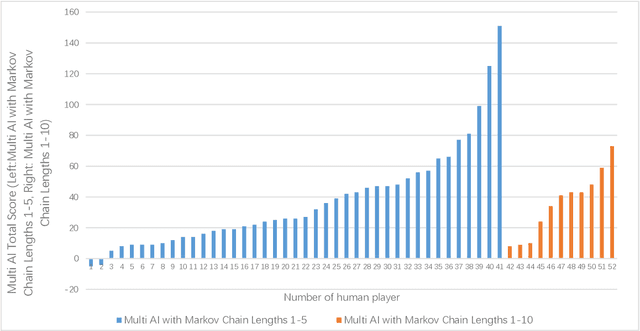
Predicting and modeling human behavior and finding trends within human decision-making process is a major social sciences'problem. Rock Paper Scissors (RPS) is the fundamental strategic question in many game theory problems and real-world competitions. Finding the right approach to beat a particular human opponent is challenging. Here we use Markov Chains with set chain lengths as the single AIs (artificial intelligences) to compete against humans in iterated RPS game. This is the first time that an AI algorithm is applied in RPS human competition behavior studies. We developed an architecture of multi-AI with changeable parameters to adapt to different competition strategies. We introduce a parameter "focus length" (an integer of e.g. 5 or 10) to control the speed and sensitivity for our multi-AI to adapt to the opponent's strategy change. We experimented with 52 different people, each playing 300 rounds continuously against one specific multi-AI model, and demonstrated that our strategy could win over more than 95% of human opponents.
Compositional Generalization for Primitive Substitutions
Oct 07, 2019
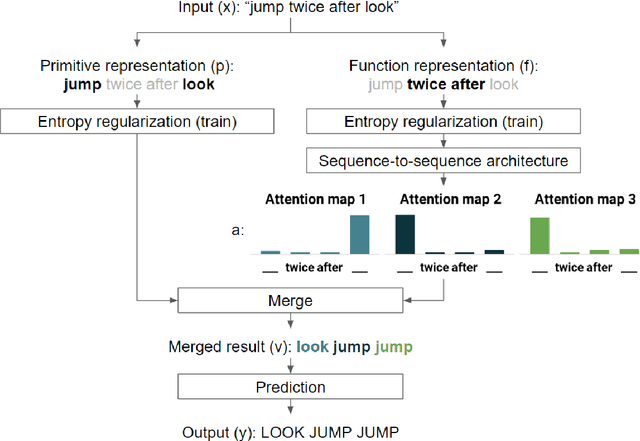
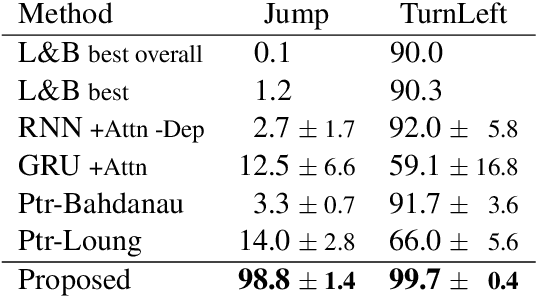

Compositional generalization is a basic mechanism in human language learning, but current neural networks lack such ability. In this paper, we conduct fundamental research for encoding compositionality in neural networks. Conventional methods use a single representation for the input sentence, making it hard to apply prior knowledge of compositionality. In contrast, our approach leverages such knowledge with two representations, one generating attention maps, and the other mapping attended input words to output symbols. We reduce the entropy in each representation to improve generalization. Our experiments demonstrate significant improvements over the conventional methods in five NLP tasks including instruction learning and machine translation. In the SCAN domain, it boosts accuracies from 14.0% to 98.8% in Jump task, and from 92.0% to 99.7% in TurnLeft task. It also beats human performance on a few-shot learning task. We hope the proposed approach can help ease future research towards human-level compositional language learning.