 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025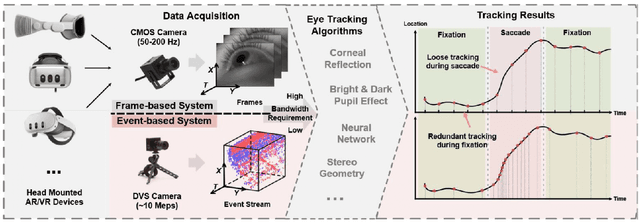
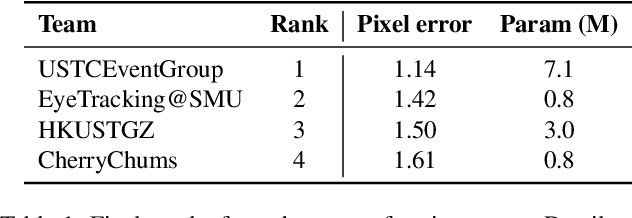

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
Real-time Speech Enhancement on Raw Signals with Deep State-space Modeling
Sep 07, 2024We present aTENNuate, a simple deep state-space autoencoder configured for efficient online raw speech enhancement in an end-to-end fashion. The network's performance is primarily evaluated on raw speech denoising, with additional assessments on tasks such as super-resolution and de-quantization. We benchmark aTENNuate on the VoiceBank + DEMAND and the Microsoft DNS1 synthetic test sets. The network outperforms previous real-time denoising models in terms of PESQ score, parameter count, MACs, and latency. Even as a raw waveform processing model, the model maintains high fidelity to the clean signal with minimal audible artifacts. In addition, the model remains performant even when the noisy input is compressed down to 4000Hz and 4 bits, suggesting general speech enhancement capabilities in low-resource environments. Code is available at github.com/Brainchip-Inc/aTENNuate
Raw Speech Enhancement with Deep State Space Modeling
Sep 05, 2024We present aTENNuate, a simple deep state-space autoencoder configured for efficient online raw speech enhancement in an end-to-end fashion. The network's performance is primarily evaluated on raw speech denoising, with additional assessments on tasks such as super-resolution and de-quantization. We benchmark aTENNuate on the VoiceBank + DEMAND and the Microsoft DNS1 synthetic test sets. The network outperforms previous real-time denoising models in terms of PESQ score, parameter count, MACs, and latency. Even as a raw waveform processing model, the model maintains high fidelity to the clean signal with minimal audible artifacts. In addition, the model remains performant even when the noisy input is compressed down to 4000Hz and 4 bits, suggesting general speech enhancement capabilities in low-resource environments.
Building Temporal Kernels with Orthogonal Polynomials
May 22, 2024
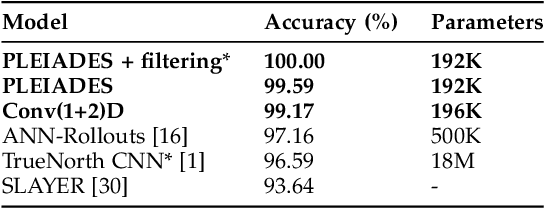


We introduce a class of models named PLEIADES (PoLynomial Expansion In Adaptive Distributed Event-based Systems), which contains temporal convolution kernels generated from orthogonal polynomial basis functions. We focus on interfacing these networks with event-based data to perform online spatiotemporal classification and detection with low latency. By virtue of using structured temporal kernels and event-based data, we have the freedom to vary the sample rate of the data along with the discretization step-size of the network without additional finetuning. We experimented with three event-based benchmarks and obtained state-of-the-art results on all three by large margins with significantly smaller memory and compute costs. We achieved: 1) 99.59% accuracy with 192K parameters on the DVS128 hand gesture recognition dataset and 100% with a small additional output filter; 2) 99.58% test accuracy with 277K parameters on the AIS 2024 eye tracking challenge; and 3) 0.556 mAP with 576k parameters on the PROPHESEE 1 Megapixel Automotive Detection Dataset.
Event-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024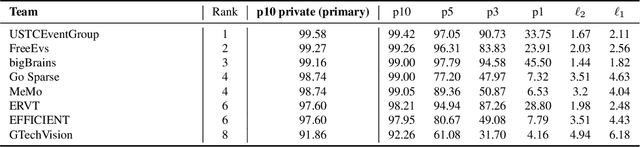
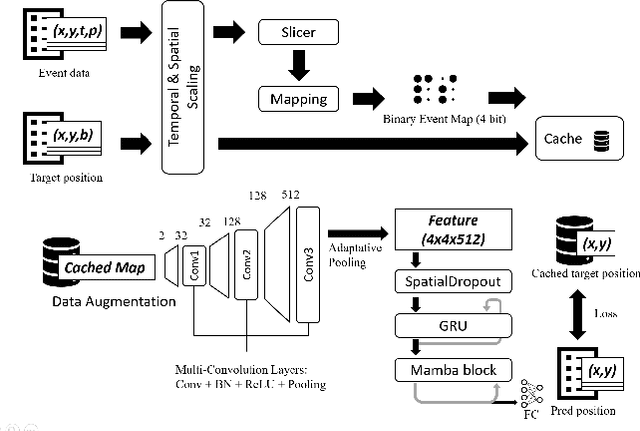
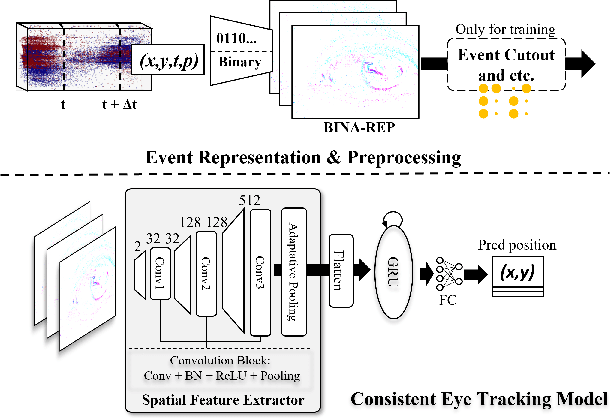

This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.
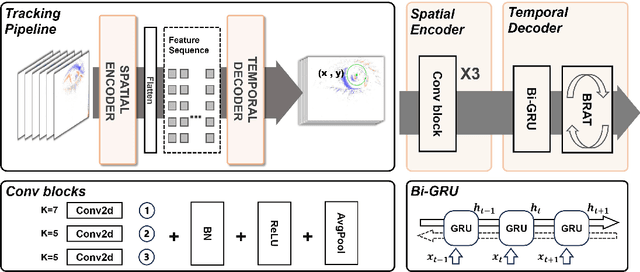
A Lightweight Spatiotemporal Network for Online Eye Tracking with Event Camera
Apr 13, 2024Event-based data are commonly encountered in edge computing environments where efficiency and low latency are critical. To interface with such data and leverage their rich temporal features, we propose a causal spatiotemporal convolutional network. This solution targets efficient implementation on edge-appropriate hardware with limited resources in three ways: 1) deliberately targets a simple architecture and set of operations (convolutions, ReLU activations) 2) can be configured to perform online inference efficiently via buffering of layer outputs 3) can achieve more than 90% activation sparsity through regularization during training, enabling very significant efficiency gains on event-based processors. In addition, we propose a general affine augmentation strategy acting directly on the events, which alleviates the problem of dataset scarcity for event-based systems. We apply our model on the AIS 2024 event-based eye tracking challenge, reaching a score of 0.9916 p10 accuracy on the Kaggle private testset.
Mode-Assisted Unsupervised Learning of Restricted Boltzmann Machines
Jan 19, 2020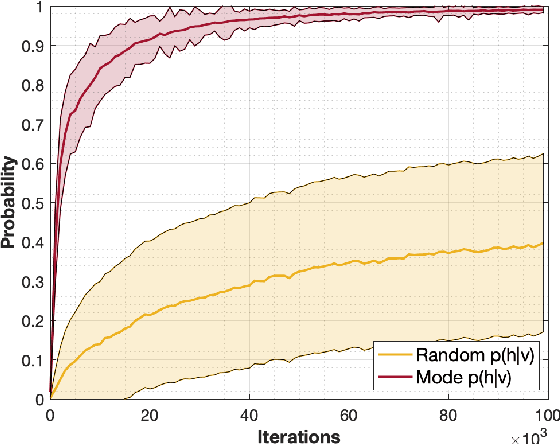
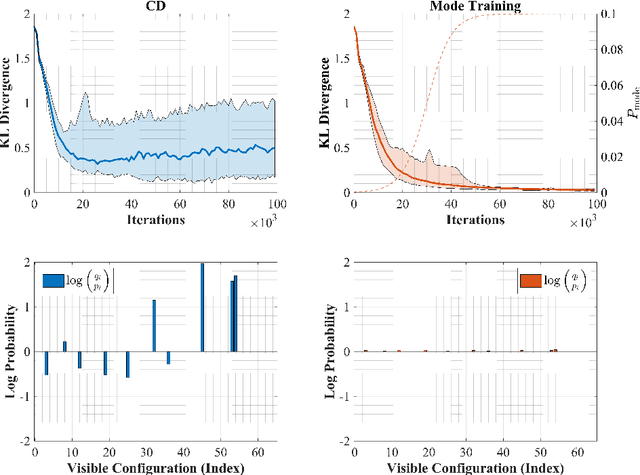
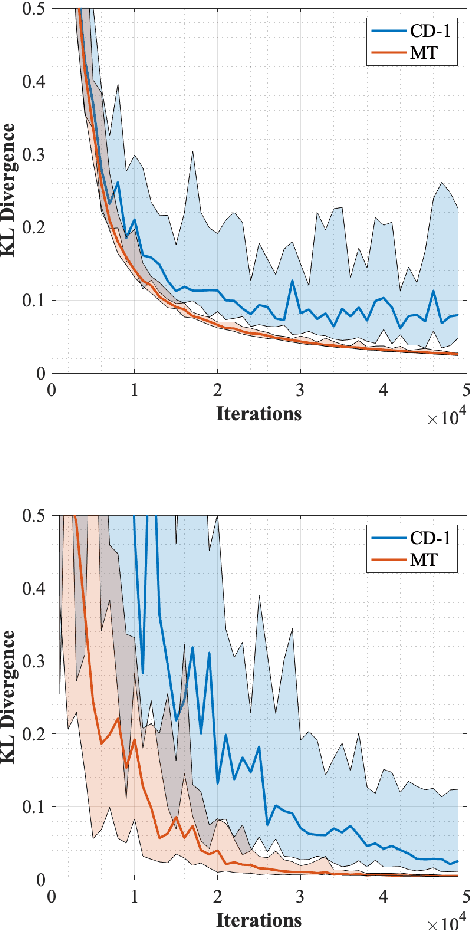
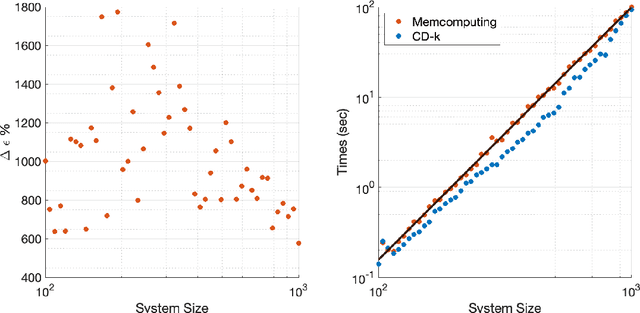
Restricted Boltzmann machines (RBMs) are a powerful class of generative models, but their training requires computing a gradient that, unlike supervised backpropagation on typical loss functions, is notoriously difficult even to approximate. Here, we show that properly combining standard gradient updates with an off-gradient direction, constructed from samples of the RBM ground state (mode), improves their training dramatically over traditional gradient methods. This approach, which we call mode training, promotes faster training and stability, in addition to lower converged relative entropy (KL divergence). Along with the proofs of stability and convergence of this method, we also demonstrate its efficacy on synthetic datasets where we can compute KL divergences exactly, as well as on a larger machine learning standard, MNIST. The mode training we suggest is quite versatile, as it can be applied in conjunction with any given gradient method, and is easily extended to more general energy-based neural network structures such as deep, convolutional and unrestricted Boltzmann machines.
Generating Weighted MAX-2-SAT Instances of Tunable Difficulty with Frustrated Loops
May 14, 2019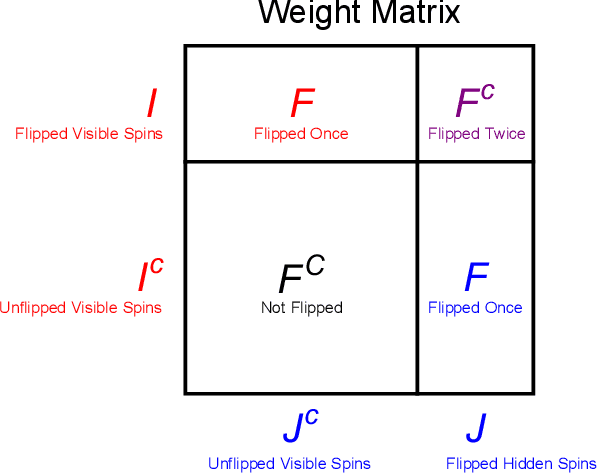

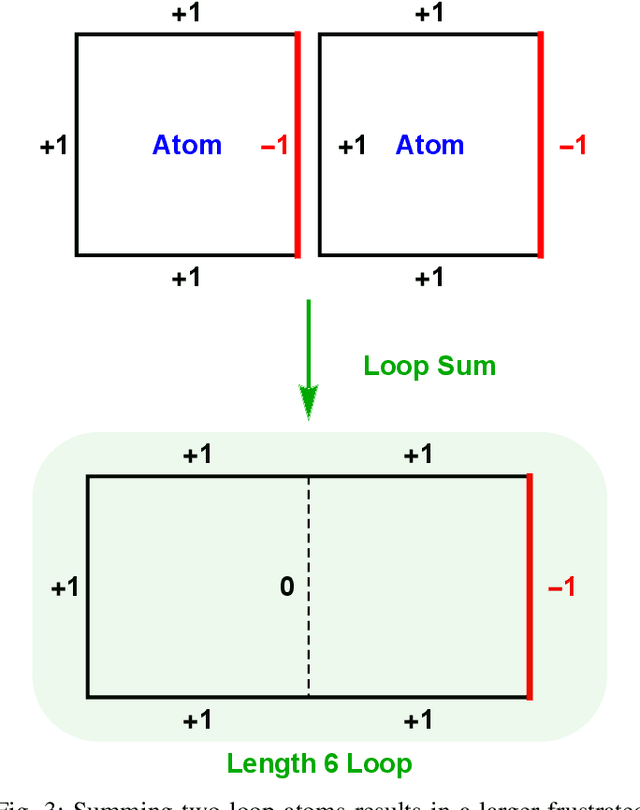

Many optimization problems can be cast into the maximum satisfiability (MAX-SAT) form, and many solvers have been developed for tackling such problems. To evaluate the performance of a MAX-SAT solver, it is convenient to generate difficult MAX-SAT instances with solutions known in advance. Here, we propose a method of generating weighted MAX-2-SAT instances inspired by the frustrated-loop algorithm used by the quantum annealing community to generate Ising spin-glass instances with nearest-neighbor coupling. Our algorithm is extended to instances whose underlying coupling graph is general, though we focus here on the case of bipartite coupling, with the associated energy being the restricted Boltzmann machine (RBM) energy. It is shown that any MAX-2-SAT problem can be reduced to the problem of minimizing an RBM energy over the nodal values. The algorithm is designed such that the difficulty of the generated instances can be tuned through a central parameter known as the frustration index. Two versions of the algorithm are presented: the random- and structured-loop algorithms. For the random-loop algorithm, we provide a thorough theoretical and empirical analysis on its mathematical properties from the perspective of frustration, and observe empirically, using simulated annealing, a double phase transition behavior in the difficulty scaling behavior driven by the frustration index. For the structured-loop algorithm, we show that it offers an improvement in difficulty of the generated instances over the random-loop algorithm, with the improvement factor scaling super-exponentially with respect to the frustration index for instances at high loop density. At the end of the paper, we provide a brief discussion of the relevance of this work to the pre-training of RBMs.
On the Universality of Memcomputing Machines
Dec 23, 2017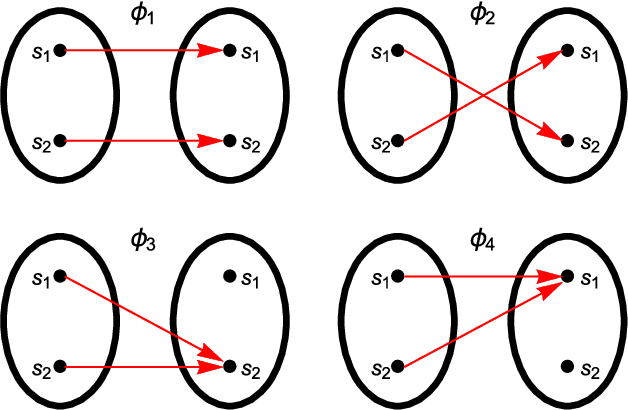
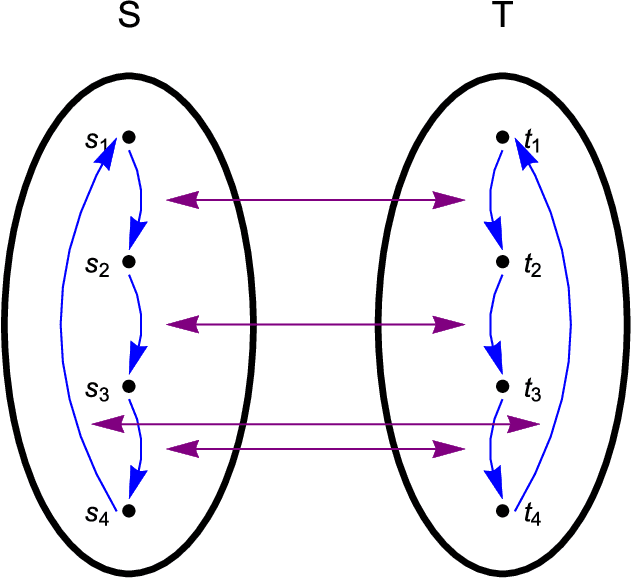
Universal memcomputing machines (UMMs) [IEEE Trans. Neural Netw. Learn. Syst. 26, 2702 (2015)] represent a novel computational model in which memory (time non-locality) accomplishes both tasks of storing and processing of information. UMMs have been shown to be Turing-complete, namely they can simulate any Turing machine. In this paper, using set theory and cardinality arguments, we compare them with liquid-state machines (or "reservoir computing") and quantum machines ("quantum computing"). We show that UMMs can simulate both types of machines, hence they are both "liquid-" or "reservoir-complete" and "quantum-complete". Of course, these statements pertain only to the type of problems these machines can solve, and not to the amount of resources required for such simulations. Nonetheless, the method presented here provides a general framework in which to describe the relation between UMMs and any other type of computational model.