 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025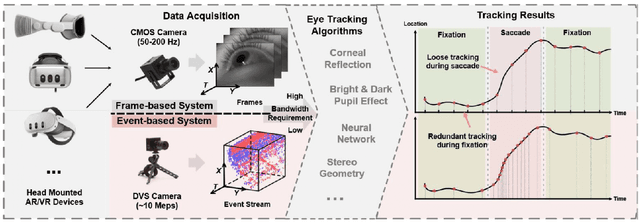
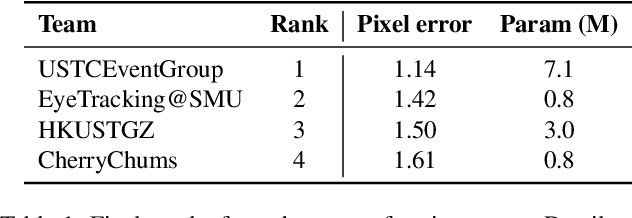
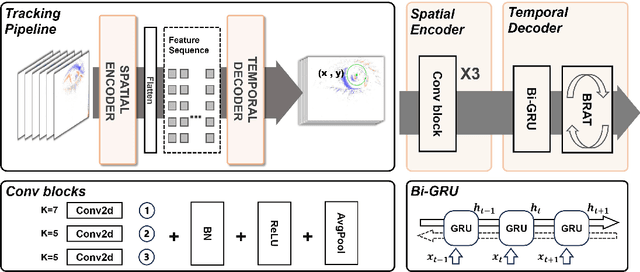

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
Decouple to Reconstruct: High Quality UHD Restoration via Active Feature Disentanglement and Reversible Fusion
Mar 17, 2025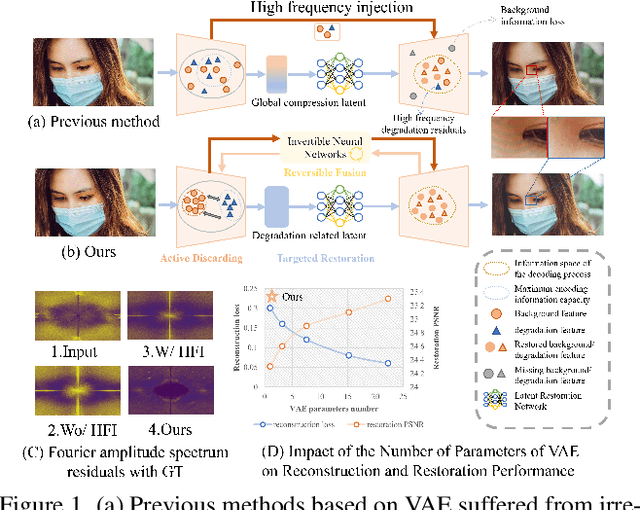
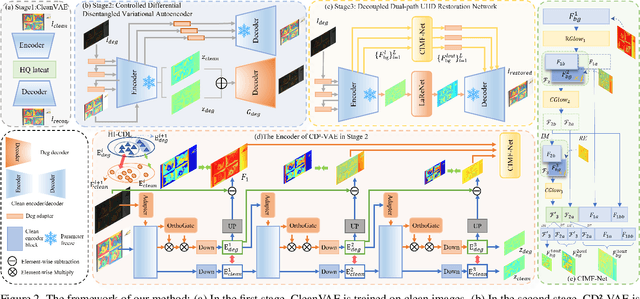

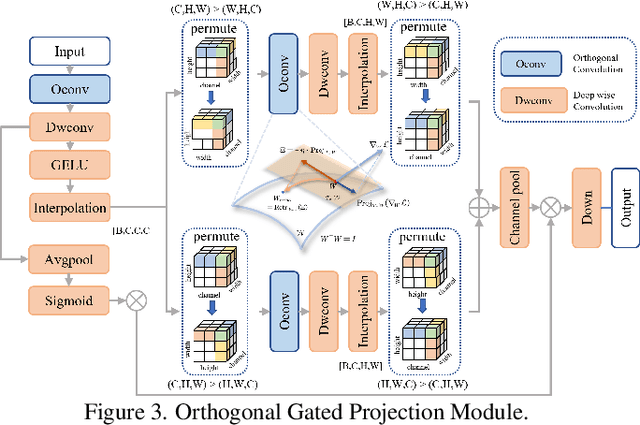
Ultra-high-definition (UHD) image restoration often faces computational bottlenecks and information loss due to its extremely high resolution. Existing studies based on Variational Autoencoders (VAE) improve efficiency by transferring the image restoration process from pixel space to latent space. However, degraded components are inherently coupled with background elements in degraded images, both information loss during compression and information gain during compensation remain uncontrollable. These lead to restored images often exhibiting image detail loss and incomplete degradation removal. To address this issue, we propose a Controlled Differential Disentangled VAE, which utilizes Hierarchical Contrastive Disentanglement Learning and an Orthogonal Gated Projection Module to guide the VAE to actively discard easily recoverable background information while encoding more difficult-to-recover degraded information into the latent space. Additionally, we design a Complex Invertible Multiscale Fusion Network to handle background features, ensuring their consistency, and utilize a latent space restoration network to transform the degraded latent features, leading to more accurate restoration results. Extensive experimental results demonstrate that our method effectively alleviates the information loss problem in VAE models while ensuring computational efficiency, significantly improving the quality of UHD image restoration, and achieves state-of-the-art results in six UHD restoration tasks with only 1M parameters.
Event-Based Tracking Any Point with Motion-Augmented Temporal Consistency
Dec 02, 2024


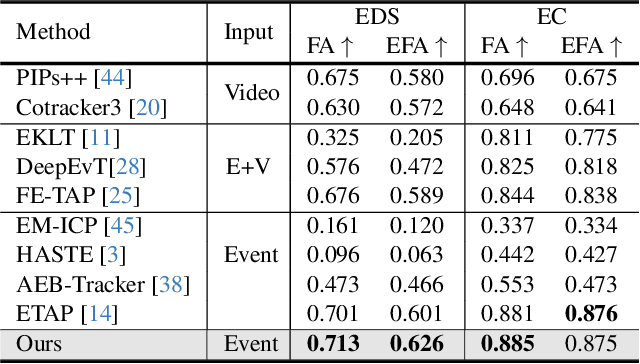
Tracking Any Point (TAP) plays a crucial role in motion analysis. Video-based approaches rely on iterative local matching for tracking, but they assume linear motion during the blind time between frames, which leads to target point loss under large displacements or nonlinear motion. The high temporal resolution and motion blur-free characteristics of event cameras provide continuous, fine-grained motion information, capturing subtle variations with microsecond precision. This paper presents an event-based framework for tracking any point, which tackles the challenges posed by spatial sparsity and motion sensitivity in events through two tailored modules. Specifically, to resolve ambiguities caused by event sparsity, a motion-guidance module incorporates kinematic features into the local matching process. Additionally, a variable motion aware module is integrated to ensure temporally consistent responses that are insensitive to varying velocities, thereby enhancing matching precision. To validate the effectiveness of the approach, an event dataset for tracking any point is constructed by simulation, and is applied in experiments together with two real-world datasets. The experimental results show that the proposed method outperforms existing SOTA methods. Moreover, it achieves 150\% faster processing with competitive model parameters.
MambaPupil: Bidirectional Selective Recurrent model for Event-based Eye tracking
Apr 18, 2024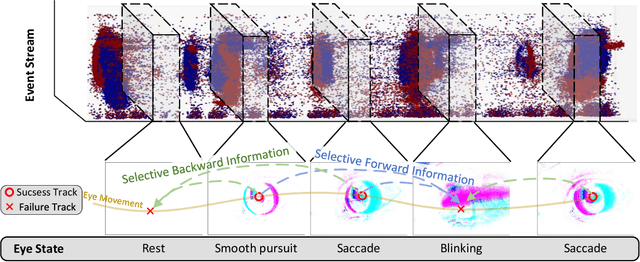
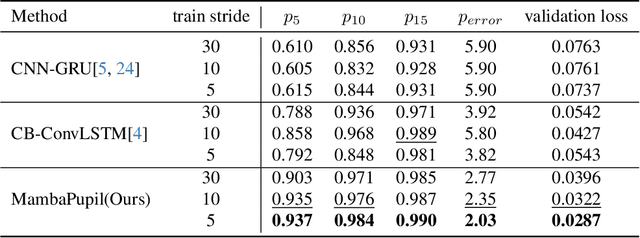
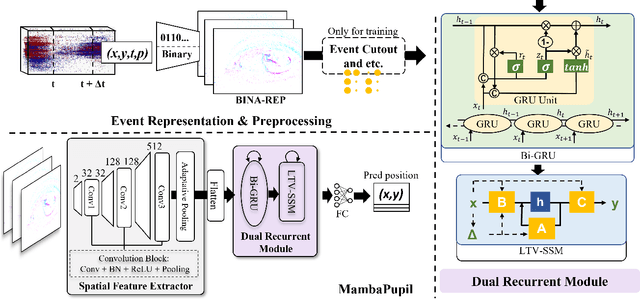

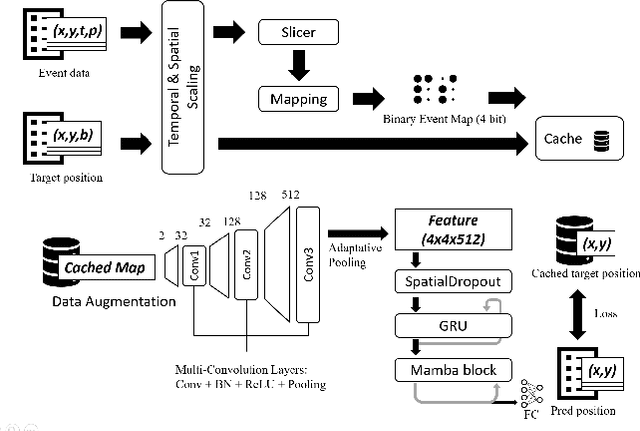
Event-based eye tracking has shown great promise with the high temporal resolution and low redundancy provided by the event camera. However, the diversity and abruptness of eye movement patterns, including blinking, fixating, saccades, and smooth pursuit, pose significant challenges for eye localization. To achieve a stable event-based eye-tracking system, this paper proposes a bidirectional long-term sequence modeling and time-varying state selection mechanism to fully utilize contextual temporal information in response to the variability of eye movements. Specifically, the MambaPupil network is proposed, which consists of the multi-layer convolutional encoder to extract features from the event representations, a bidirectional Gated Recurrent Unit (GRU), and a Linear Time-Varying State Space Module (LTV-SSM), to selectively capture contextual correlation from the forward and backward temporal relationship. Furthermore, the Bina-rep is utilized as a compact event representation, and the tailor-made data augmentation, called as Event-Cutout, is proposed to enhance the model's robustness by applying spatial random masking to the event image. The evaluation on the ThreeET-plus benchmark shows the superior performance of the MambaPupil, which secured the 1st place in CVPR'2024 AIS Event-based Eye Tracking challenge.
Event-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024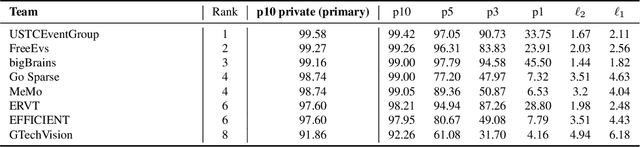
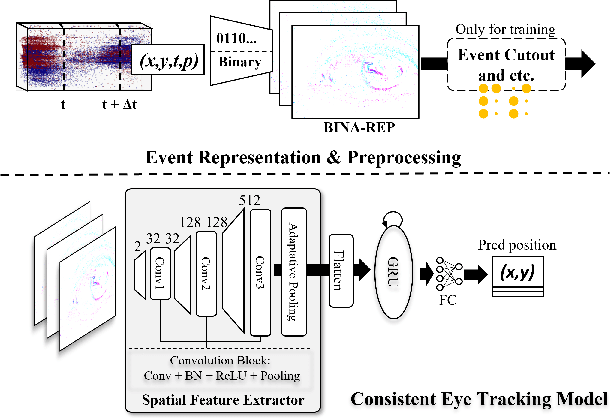

This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.
SCott: Accelerating Diffusion Models with Stochastic Consistency Distillation
Mar 03, 2024
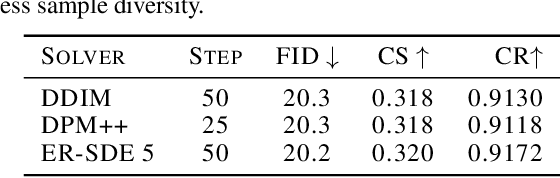
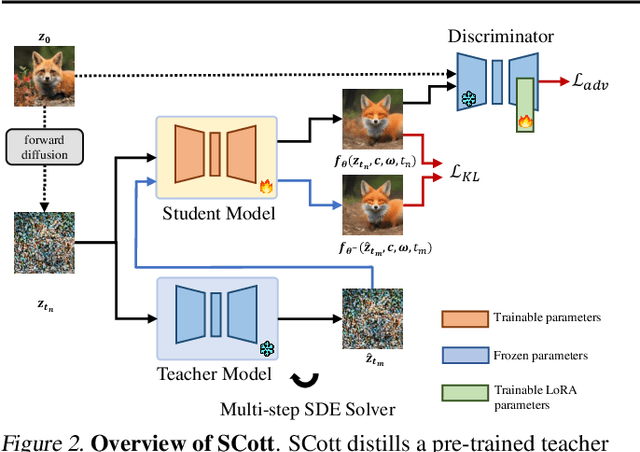
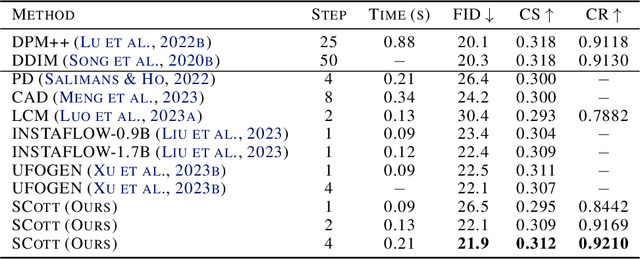
The iterative sampling procedure employed by diffusion models (DMs) often leads to significant inference latency. To address this, we propose Stochastic Consistency Distillation (SCott) to enable accelerated text-to-image generation, where high-quality generations can be achieved with just 1-2 sampling steps, and further improvements can be obtained by adding additional steps. In contrast to vanilla consistency distillation (CD) which distills the ordinary differential equation solvers-based sampling process of a pretrained teacher model into a student, SCott explores the possibility and validates the efficacy of integrating stochastic differential equation (SDE) solvers into CD to fully unleash the potential of the teacher. SCott is augmented with elaborate strategies to control the noise strength and sampling process of the SDE solver. An adversarial loss is further incorporated to strengthen the sample quality with rare sampling steps. Empirically, on the MSCOCO-2017 5K dataset with a Stable Diffusion-V1.5 teacher, SCott achieves an FID (Frechet Inceptio Distance) of 22.1, surpassing that (23.4) of the 1-step InstaFlow (Liu et al., 2023) and matching that of 4-step UFOGen (Xue et al., 2023b). Moreover, SCott can yield more diverse samples than other consistency models for high-resolution image generation (Luo et al., 2023a), with up to 16% improvement in a qualified metric. The code and checkpoints are coming soon.
Deep Spiking-UNet for Image Processing
Jul 20, 2023
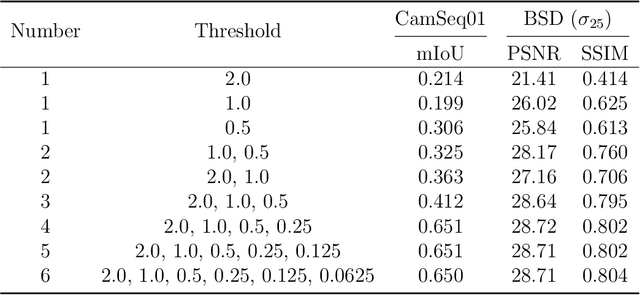

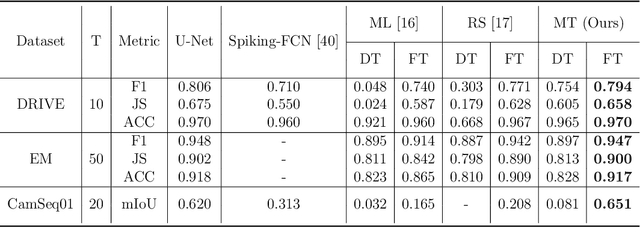
U-Net, known for its simple yet efficient architecture, is widely utilized for image processing tasks and is particularly suitable for deployment on neuromorphic chips. This paper introduces the novel concept of Spiking-UNet for image processing, which combines the power of Spiking Neural Networks (SNNs) with the U-Net architecture. To achieve an efficient Spiking-UNet, we face two primary challenges: ensuring high-fidelity information propagation through the network via spikes and formulating an effective training strategy. To address the issue of information loss, we introduce multi-threshold spiking neurons, which improve the efficiency of information transmission within the Spiking-UNet. For the training strategy, we adopt a conversion and fine-tuning pipeline that leverage pre-trained U-Net models. During the conversion process, significant variability in data distribution across different parts is observed when utilizing skip connections. Therefore, we propose a connection-wise normalization method to prevent inaccurate firing rates. Furthermore, we adopt a flow-based training method to fine-tune the converted models, reducing time steps while preserving performance. Experimental results show that, on image segmentation and denoising, our Spiking-UNet achieves comparable performance to its non-spiking counterpart, surpassing existing SNN methods. Compared with the converted Spiking-UNet without fine-tuning, our Spiking-UNet reduces inference time by approximately 90\%. This research broadens the application scope of SNNs in image processing and is expected to inspire further exploration in the field of neuromorphic engineering. The code for our Spiking-UNet implementation is available at https://github.com/SNNresearch/Spiking-UNet.
Knowledge-Enhanced Hierarchical Information Correlation Learning for Multi-Modal Rumor Detection
Jun 28, 2023



The explosive growth of rumors with text and images on social media platforms has drawn great attention. Existing studies have made significant contributions to cross-modal information interaction and fusion, but they fail to fully explore hierarchical and complex semantic correlation across different modality content, severely limiting their performance on detecting multi-modal rumor. In this work, we propose a novel knowledge-enhanced hierarchical information correlation learning approach (KhiCL) for multi-modal rumor detection by jointly modeling the basic semantic correlation and high-order knowledge-enhanced entity correlation. Specifically, KhiCL exploits cross-modal joint dictionary to transfer the heterogeneous unimodality features into the common feature space and captures the basic cross-modal semantic consistency and inconsistency by a cross-modal fusion layer. Moreover, considering the description of multi-modal content is narrated around entities, KhiCL extracts visual and textual entities from images and text, and designs a knowledge relevance reasoning strategy to find the shortest semantic relevant path between each pair of entities in external knowledge graph, and absorbs all complementary contextual knowledge of other connected entities in this path for learning knowledge-enhanced entity representations. Furthermore, KhiCL utilizes a signed attention mechanism to model the knowledge-enhanced entity consistency and inconsistency of intra-modality and inter-modality entity pairs by measuring their corresponding semantic relevant distance. Extensive experiments have demonstrated the effectiveness of the proposed method.
Location-Free Camouflage Generation Network
Mar 18, 2022



Camouflage is a common visual phenomenon, which refers to hiding the foreground objects into the background images, making them briefly invisible to the human eye. Previous work has typically been implemented by an iterative optimization process. However, these methods struggle in 1) efficiently generating camouflage images using foreground and background with arbitrary structure; 2) camouflaging foreground objects to regions with multiple appearances (e.g. the junction of the vegetation and the mountains), which limit their practical application. To address these problems, this paper proposes a novel Location-free Camouflage Generation Network (LCG-Net) that fuse high-level features of foreground and background image, and generate result by one inference. Specifically, a Position-aligned Structure Fusion (PSF) module is devised to guide structure feature fusion based on the point-to-point structure similarity of foreground and background, and introduce local appearance features point-by-point. To retain the necessary identifiable features, a new immerse loss is adopted under our pipeline, while a background patch appearance loss is utilized to ensure that the hidden objects look continuous and natural at regions with multiple appearances. Experiments show that our method has results as satisfactory as state-of-the-art in the single-appearance regions and are less likely to be completely invisible, but far exceed the quality of the state-of-the-art in the multi-appearance regions. Moreover, our method is hundreds of times faster than previous methods. Benefitting from the unique advantages of our method, we provide some downstream applications for camouflage generation, which show its potential. The related code and dataset will be released at https://github.com/Tale17/LCG-Net.
Lifelong Unsupervised Domain Adaptive Person Re-identification with Coordinated Anti-forgetting and Adaptation
Dec 13, 2021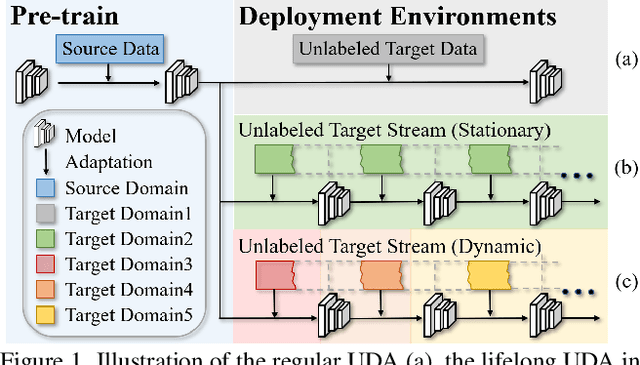

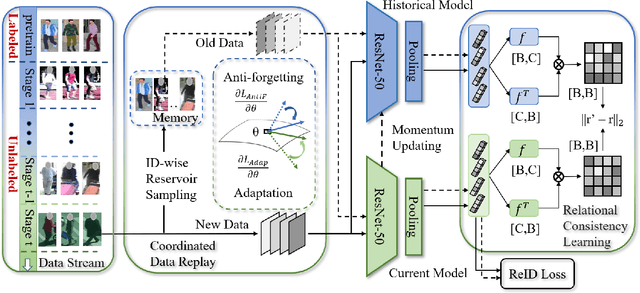
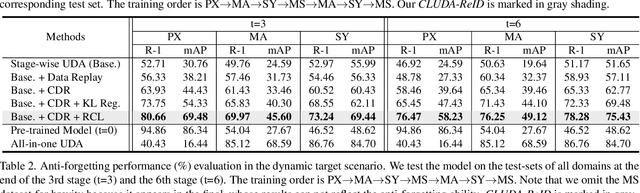
Unsupervised domain adaptive person re-identification (ReID) has been extensively investigated to mitigate the adverse effects of domain gaps. Those works assume the target domain data can be accessible all at once. However, for the real-world streaming data, this hinders the timely adaptation to changing data statistics and sufficient exploitation of increasing samples. In this paper, to address more practical scenarios, we propose a new task, Lifelong Unsupervised Domain Adaptive (LUDA) person ReID. This is challenging because it requires the model to continuously adapt to unlabeled data of the target environments while alleviating catastrophic forgetting for such a fine-grained person retrieval task. We design an effective scheme for this task, dubbed CLUDA-ReID, where the anti-forgetting is harmoniously coordinated with the adaptation. Specifically, a meta-based Coordinated Data Replay strategy is proposed to replay old data and update the network with a coordinated optimization direction for both adaptation and memorization. Moreover, we propose Relational Consistency Learning for old knowledge distillation/inheritance in line with the objective of retrieval-based tasks. We set up two evaluation settings to simulate the practical application scenarios. Extensive experiments demonstrate the effectiveness of our CLUDA-ReID for both scenarios with stationary target streams and scenarios with dynamic target streams.