 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrightness Perceiving for Recursive Low-Light Image Enhancement
Apr 03, 2025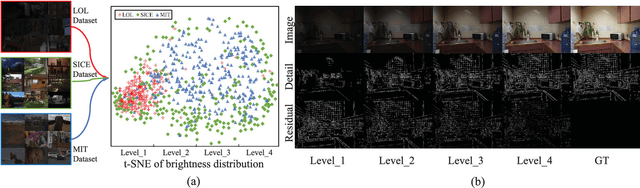



Due to the wide dynamic range in real low-light scenes, there will be large differences in the degree of contrast degradation and detail blurring of captured images, making it difficult for existing end-to-end methods to enhance low-light images to normal exposure. To address the above issue, we decompose low-light image enhancement into a recursive enhancement task and propose a brightness-perceiving-based recursive enhancement framework for high dynamic range low-light image enhancement. Specifically, our recursive enhancement framework consists of two parallel sub-networks: Adaptive Contrast and Texture enhancement network (ACT-Net) and Brightness Perception network (BP-Net). The ACT-Net is proposed to adaptively enhance image contrast and details under the guidance of the brightness adjustment branch and gradient adjustment branch, which are proposed to perceive the degradation degree of contrast and details in low-light images. To adaptively enhance images captured under different brightness levels, BP-Net is proposed to control the recursive enhancement times of ACT-Net by exploring the image brightness distribution properties. Finally, in order to coordinate ACT-Net and BP-Net, we design a novel unsupervised training strategy to facilitate the training procedure. To further validate the effectiveness of the proposed method, we construct a new dataset with a broader brightness distribution by mixing three low-light datasets. Compared with eleven existing representative methods, the proposed method achieves new SOTA performance on six reference and no reference metrics. Specifically, the proposed method improves the PSNR by 0.9 dB compared to the existing SOTA method.
EMoTive: Event-guided Trajectory Modeling for 3D Motion Estimation
Mar 17, 2025Visual 3D motion estimation aims to infer the motion of 2D pixels in 3D space based on visual cues. The key challenge arises from depth variation induced spatio-temporal motion inconsistencies, disrupting the assumptions of local spatial or temporal motion smoothness in previous motion estimation frameworks. In contrast, event cameras offer new possibilities for 3D motion estimation through continuous adaptive pixel-level responses to scene changes. This paper presents EMoTive, a novel event-based framework that models spatio-temporal trajectories via event-guided non-uniform parametric curves, effectively characterizing locally heterogeneous spatio-temporal motion. Specifically, we first introduce Event Kymograph - an event projection method that leverages a continuous temporal projection kernel and decouples spatial observations to encode fine-grained temporal evolution explicitly. For motion representation, we introduce a density-aware adaptation mechanism to fuse spatial and temporal features under event guidance, coupled with a non-uniform rational curve parameterization framework to adaptively model heterogeneous trajectories. The final 3D motion estimation is achieved through multi-temporal sampling of parametric trajectories, yielding optical flow and depth motion fields. To facilitate evaluation, we introduce CarlaEvent3D, a multi-dynamic synthetic dataset for comprehensive validation. Extensive experiments on both this dataset and a real-world benchmark demonstrate the effectiveness of the proposed method.
EF-3DGS: Event-Aided Free-Trajectory 3D Gaussian Splatting
Oct 20, 2024Scene reconstruction from casually captured videos has wide applications in real-world scenarios. With recent advancements in differentiable rendering techniques, several methods have attempted to simultaneously optimize scene representations (NeRF or 3DGS) and camera poses. Despite recent progress, existing methods relying on traditional camera input tend to fail in high-speed (or equivalently low-frame-rate) scenarios. Event cameras, inspired by biological vision, record pixel-wise intensity changes asynchronously with high temporal resolution, providing valuable scene and motion information in blind inter-frame intervals. In this paper, we introduce the event camera to aid scene construction from a casually captured video for the first time, and propose Event-Aided Free-Trajectory 3DGS, called EF-3DGS, which seamlessly integrates the advantages of event cameras into 3DGS through three key components. First, we leverage the Event Generation Model (EGM) to fuse events and frames, supervising the rendered views observed by the event stream. Second, we adopt the Contrast Maximization (CMax) framework in a piece-wise manner to extract motion information by maximizing the contrast of the Image of Warped Events (IWE), thereby calibrating the estimated poses. Besides, based on the Linear Event Generation Model (LEGM), the brightness information encoded in the IWE is also utilized to constrain the 3DGS in the gradient domain. Third, to mitigate the absence of color information of events, we introduce photometric bundle adjustment (PBA) to ensure view consistency across events and frames.We evaluate our method on the public Tanks and Temples benchmark and a newly collected real-world dataset, RealEv-DAVIS. Our project page is https://lbh666.github.io/ef-3dgs/.
MambaPupil: Bidirectional Selective Recurrent model for Event-based Eye tracking
Apr 18, 2024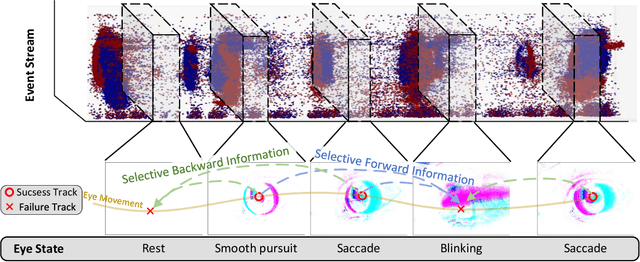
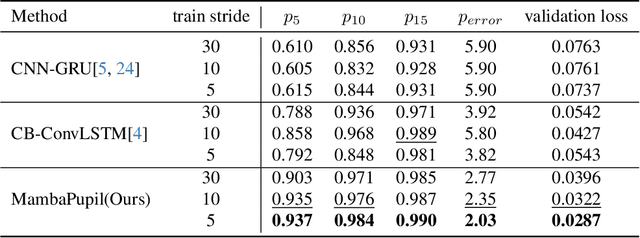
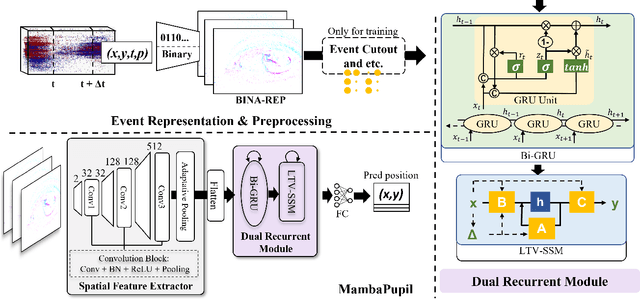

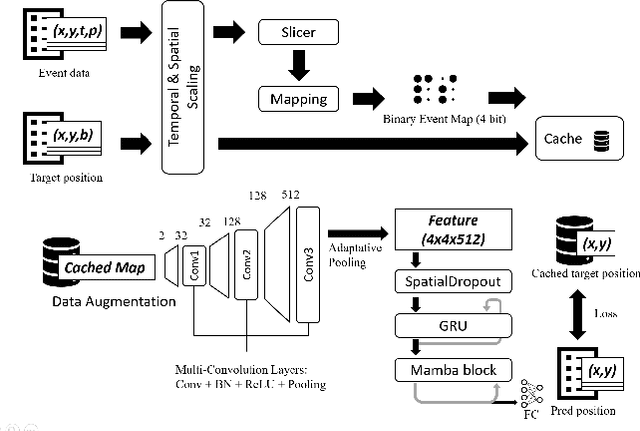
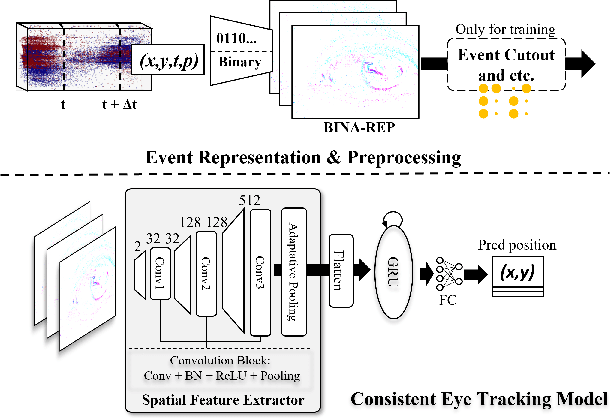
Event-based eye tracking has shown great promise with the high temporal resolution and low redundancy provided by the event camera. However, the diversity and abruptness of eye movement patterns, including blinking, fixating, saccades, and smooth pursuit, pose significant challenges for eye localization. To achieve a stable event-based eye-tracking system, this paper proposes a bidirectional long-term sequence modeling and time-varying state selection mechanism to fully utilize contextual temporal information in response to the variability of eye movements. Specifically, the MambaPupil network is proposed, which consists of the multi-layer convolutional encoder to extract features from the event representations, a bidirectional Gated Recurrent Unit (GRU), and a Linear Time-Varying State Space Module (LTV-SSM), to selectively capture contextual correlation from the forward and backward temporal relationship. Furthermore, the Bina-rep is utilized as a compact event representation, and the tailor-made data augmentation, called as Event-Cutout, is proposed to enhance the model's robustness by applying spatial random masking to the event image. The evaluation on the ThreeET-plus benchmark shows the superior performance of the MambaPupil, which secured the 1st place in CVPR'2024 AIS Event-based Eye Tracking challenge.
Event-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024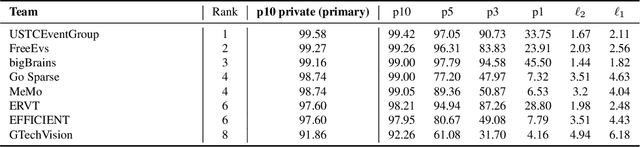

This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.