 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS3LAM: Gaussian Semantic Splatting SLAM
Mar 29, 2026Recently, the multi-modal fusion of RGB, depth, and semantics has shown great potential in dense Simultaneous Localization and Mapping (SLAM). However, a prerequisite for generating consistent semantic maps is the availability of dense, efficient, and scalable scene representations. Existing semantic SLAM systems based on explicit representations are often limited by resolution and an inability to predict unknown areas. Conversely, implicit representations typically rely on time-consuming ray tracing, failing to meet real-time requirements. Fortunately, 3D Gaussian Splatting (3DGS) has emerged as a promising representation that combines the efficiency of point-based methods with the continuity of geometric structures. To this end, we propose GS3LAM, a Gaussian Semantic Splatting SLAM framework that processes multimodal data to render consistent, dense semantic maps in real-time. GS3LAM models the scene as a Semantic Gaussian Field (SG-Field) and jointly optimizes camera poses and the field via multimodal error constraints. Furthermore, a Depth-adaptive Scale Regularization (DSR) scheme is introduced to resolve misalignments between scale-invariant Gaussians and geometric surfaces. To mitigate catastrophic forgetting, we propose a Random Sampling-based Keyframe Mapping (RSKM) strategy, which demonstrates superior performance over common local covisibility optimization methods. Extensive experiments on benchmark datasets show that GS3LAM achieves increased tracking robustness, superior rendering quality, and enhanced semantic precision compared to state-of-the-art methods. Source code is available at https://github.com/lif314/GS3LAM.
SceneTransporter: Optimal Transport-Guided Compositional Latent Diffusion for Single-Image Structured 3D Scene Generation
Feb 26, 2026We introduce SceneTransporter, an end-to-end framework for structured 3D scene generation from a single image. While existing methods generate part-level 3D objects, they often fail to organize these parts into distinct instances in open-world scenes. Through a debiased clustering probe, we reveal a critical insight: this failure stems from the lack of structural constraints within the model's internal assignment mechanism. Based on this finding, we reframe the task of structured 3D scene generation as a global correlation assignment problem. To solve this, SceneTransporter formulates and solves an entropic Optimal Transport (OT) objective within the denoising loop of the compositional DiT model. This formulation imposes two powerful structural constraints. First, the resulting transport plan gates cross-attention to enforce an exclusive, one-to-one routing of image patches to part-level 3D latents, preventing entanglement. Second, the competitive nature of the transport encourages the grouping of similar patches, a process that is further regularized by an edge-based cost, to form coherent objects and prevent fragmentation. Extensive experiments show that SceneTransporter outperforms existing methods on open-world scene generation, significantly improving instance-level coherence and geometric fidelity. Code and models will be publicly available at https://2019epwl.github.io/SceneTransporter/.
SmartSplat: Feature-Smart Gaussians for Scalable Compression of Ultra-High-Resolution Images
Dec 23, 2025Recent advances in generative AI have accelerated the production of ultra-high-resolution visual content, posing significant challenges for efficient compression and real-time decoding on end-user devices. Inspired by 3D Gaussian Splatting, recent 2D Gaussian image models improve representation efficiency, yet existing methods struggle to balance compression ratio and reconstruction fidelity in ultra-high-resolution scenarios. To address this issue, we propose SmartSplat, a highly adaptive and feature-aware GS-based image compression framework that supports arbitrary image resolutions and compression ratios. SmartSplat leverages image-aware features such as gradients and color variances, introducing a Gradient-Color Guided Variational Sampling strategy together with an Exclusion-based Uniform Sampling scheme to improve the non-overlapping coverage of Gaussian primitives in pixel space. In addition, we propose a Scale-Adaptive Gaussian Color Sampling method to enhance color initialization across scales. Through joint optimization of spatial layout, scale, and color initialization, SmartSplat efficiently captures both local structures and global textures using a limited number of Gaussians, achieving high reconstruction quality under strong compression. Extensive experiments on DIV8K and a newly constructed 16K dataset demonstrate that SmartSplat consistently outperforms state-of-the-art methods at comparable compression ratios and exceeds their compression limits, showing strong scalability and practical applicability. The code is publicly available at https://github.com/lif314/SmartSplat.
Vision-Language Semantic Aggregation Leveraging Foundation Model for Generalizable Medical Image Segmentation
Sep 10, 2025
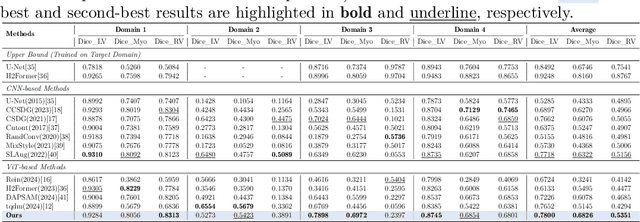
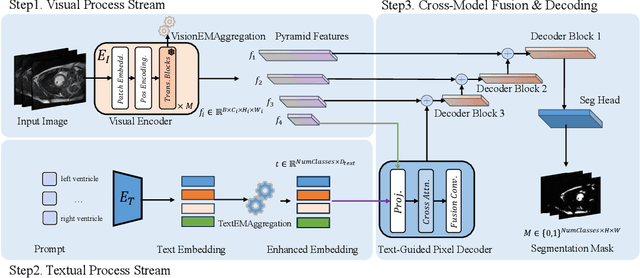
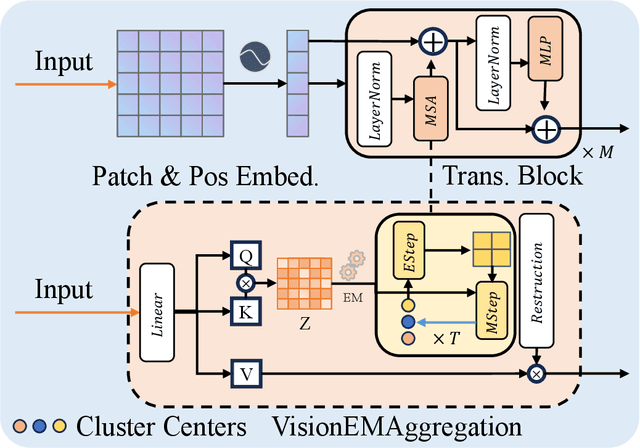
Multimodal models have achieved remarkable success in natural image segmentation, yet they often underperform when applied to the medical domain. Through extensive study, we attribute this performance gap to the challenges of multimodal fusion, primarily the significant semantic gap between abstract textual prompts and fine-grained medical visual features, as well as the resulting feature dispersion. To address these issues, we revisit the problem from the perspective of semantic aggregation. Specifically, we propose an Expectation-Maximization (EM) Aggregation mechanism and a Text-Guided Pixel Decoder. The former mitigates feature dispersion by dynamically clustering features into compact semantic centers to enhance cross-modal correspondence. The latter is designed to bridge the semantic gap by leveraging domain-invariant textual knowledge to effectively guide deep visual representations. The synergy between these two mechanisms significantly improves the model's generalization ability. Extensive experiments on public cardiac and fundus datasets demonstrate that our method consistently outperforms existing SOTA approaches across multiple domain generalization benchmarks.
semi-PD: Towards Efficient LLM Serving via Phase-Wise Disaggregated Computation and Unified Storage
Apr 28, 2025Existing large language model (LLM) serving systems fall into two categories: 1) a unified system where prefill phase and decode phase are co-located on the same GPU, sharing the unified computational resource and storage, and 2) a disaggregated system where the two phases are disaggregated to different GPUs. The design of the disaggregated system addresses the latency interference and sophisticated scheduling issues in the unified system but leads to storage challenges including 1) replicated weights for both phases that prevent flexible deployment, 2) KV cache transfer overhead between the two phases, 3) storage imbalance that causes substantial wasted space of the GPU capacity, and 4) suboptimal resource adjustment arising from the difficulties in migrating KV cache. Such storage inefficiency delivers poor serving performance under high request rates. In this paper, we identify that the advantage of the disaggregated system lies in the disaggregated computation, i.e., partitioning the computational resource to enable the asynchronous computation of two phases. Thus, we propose a novel LLM serving system, semi-PD, characterized by disaggregated computation and unified storage. In semi-PD, we introduce a computation resource controller to achieve disaggregated computation at the streaming multi-processor (SM) level, and a unified memory manager to manage the asynchronous memory access from both phases. semi-PD has a low-overhead resource adjustment mechanism between the two phases, and a service-level objective (SLO) aware dynamic partitioning algorithm to optimize the SLO attainment. Compared to state-of-the-art systems, semi-PD maintains lower latency at higher request rates, reducing the average end-to-end latency per request by 1.27-2.58x on DeepSeek series models, and serves 1.55-1.72x more requests adhering to latency constraints on Llama series models.
FlashOverlap: A Lightweight Design for Efficiently Overlapping Communication and Computation
Apr 28, 2025Generative models have achieved remarkable success across various applications, driving the demand for multi-GPU computing. Inter-GPU communication becomes a bottleneck in multi-GPU computing systems, particularly on consumer-grade GPUs. By exploiting concurrent hardware execution, overlapping computation and communication latency is an effective technique for mitigating the communication overhead. We identify that an efficient and adaptable overlapping design should satisfy (1) tile-wise overlapping to maximize the overlapping opportunity, (2) interference-free computation to maintain the original computational performance, and (3) communication agnosticism to reduce the development burden against varying communication primitives. Nevertheless, current designs fail to simultaneously optimize for all of those features. To address the issue, we propose FlashOverlap, a lightweight design characterized by tile-wise overlapping, interference-free computation, and communication agnosticism. FlashOverlap utilizes a novel signaling mechanism to identify tile-wise data dependency without interrupting the computation process, and reorders data to contiguous addresses, enabling communication by simply calling NCCL APIs. Experiments show that such a lightweight design achieves up to 1.65x speedup, outperforming existing works in most cases.
Constructing a Norm for Children's Scientific Drawing: Distribution Features Based on Semantic Similarity of Large Language Models
Feb 21, 2025The use of children's drawings to examining their conceptual understanding has been proven to be an effective method, but there are two major problems with previous research: 1. The content of the drawings heavily relies on the task, and the ecological validity of the conclusions is low; 2. The interpretation of drawings relies too much on the subjective feelings of the researchers. To address this issue, this study uses the Large Language Model (LLM) to identify 1420 children's scientific drawings (covering 9 scientific themes/concepts), and uses the word2vec algorithm to calculate their semantic similarity. The study explores whether there are consistent drawing representations for children on the same theme, and attempts to establish a norm for children's scientific drawings, providing a baseline reference for follow-up children's drawing research. The results show that the representation of most drawings has consistency, manifested as most semantic similarity greater than 0.8. At the same time, it was found that the consistency of the representation is independent of the accuracy (of LLM's recognition), indicating the existence of consistency bias. In the subsequent exploration of influencing factors, we used Kendall rank correlation coefficient to investigate the effects of Sample Size, Abstract Degree, and Focus Points on drawings, and used word frequency statistics to explore whether children represented abstract themes/concepts by reproducing what was taught in class.
KN-LIO: Geometric Kinematics and Neural Field Coupled LiDAR-Inertial Odometry
Jan 08, 2025Recent advancements in LiDAR-Inertial Odometry (LIO) have boosted a large amount of applications. However, traditional LIO systems tend to focus more on localization rather than mapping, with maps consisting mostly of sparse geometric elements, which is not ideal for downstream tasks. Recent emerging neural field technology has great potential in dense mapping, but pure LiDAR mapping is difficult to work on high-dynamic vehicles. To mitigate this challenge, we present a new solution that tightly couples geometric kinematics with neural fields to enhance simultaneous state estimation and dense mapping capabilities. We propose both semi-coupled and tightly coupled Kinematic-Neural LIO (KN-LIO) systems that leverage online SDF decoding and iterated error-state Kalman filtering to fuse laser and inertial data. Our KN-LIO minimizes information loss and improves accuracy in state estimation, while also accommodating asynchronous multi-LiDAR inputs. Evaluations on diverse high-dynamic datasets demonstrate that our KN-LIO achieves performance on par with or superior to existing state-of-the-art solutions in pose estimation and offers improved dense mapping accuracy over pure LiDAR-based methods. The relevant code and datasets will be made available at https://**.
Estimating unknown parameters in differential equations with a reinforcement learning based PSO method
Nov 13, 2024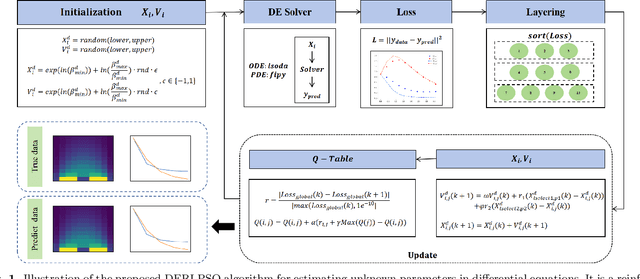

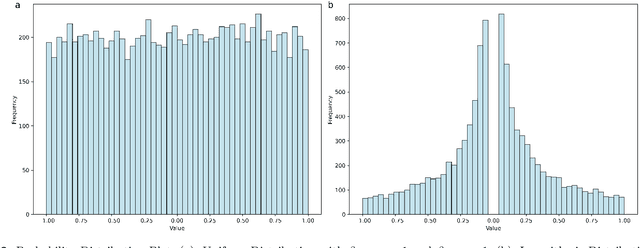

Differential equations offer a foundational yet powerful framework for modeling interactions within complex dynamic systems and are widely applied across numerous scientific fields. One common challenge in this area is estimating the unknown parameters of these dynamic relationships. However, traditional numerical optimization methods rely on the selection of initial parameter values, making them prone to local optima. Meanwhile, deep learning and Bayesian methods require training models on specific differential equations, resulting in poor versatility. This paper reformulates the parameter estimation problem of differential equations as an optimization problem by introducing the concept of particles from the particle swarm optimization algorithm. Building on reinforcement learning-based particle swarm optimization (RLLPSO), this paper proposes a novel method, DERLPSO, for estimating unknown parameters of differential equations. We compared its performance on three typical ordinary differential equations with the state-of-the-art methods, including the RLLPSO algorithm, traditional numerical methods, deep learning approaches, and Bayesian methods. The experimental results demonstrate that our DERLPSO consistently outperforms other methods in terms of performance, achieving an average Mean Square Error of 1.13e-05, which reduces the error by approximately 4 orders of magnitude compared to other methods. Apart from ordinary differential equations, our DERLPSO also show great promise for estimating unknown parameters of partial differential equations. The DERLPSO method proposed in this paper has high accuracy, is independent of initial parameter values, and possesses strong versatility and stability. This work provides new insights into unknown parameter estimation for differential equations.
Towards Autonomous Indoor Parking: A Globally Consistent Semantic SLAM System and A Semantic Localization Subsystem
Oct 16, 2024



We propose a globally consistent semantic SLAM system (GCSLAM) and a semantic-fusion localization subsystem (SF-Loc), which achieves accurate semantic mapping and robust localization in complex parking lots. Visual cameras (front-view and surround-view), IMU, and wheel encoder form the input sensor configuration of our system. The first part of our work is GCSLAM. GCSLAM introduces a novel factor graph for the optimization of poses and semantic map, which incorporates innovative error terms based on multi-sensor data and BEV (bird's-eye view) semantic information. Additionally, GCSLAM integrates a Global Slot Management module that stores and manages parking slot observations. SF-Loc is the second part of our work, which leverages the semantic map built by GCSLAM to conduct map-based localization. SF-Loc integrates registration results and odometry poses with a novel factor graph. Our system demonstrates superior performance over existing SLAM on two real-world datasets, showing excellent capabilities in robust global localization and precise semantic mapping.