 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRS-Prune: Training-Free Data Pruning at High Ratios for Efficient Remote Sensing Diffusion Foundation Models
Dec 29, 2025Diffusion-based remote sensing (RS) generative foundation models are cruial for downstream tasks. However, these models rely on large amounts of globally representative data, which often contain redundancy, noise, and class imbalance, reducing training efficiency and preventing convergence. Existing RS diffusion foundation models typically aggregate multiple classification datasets or apply simplistic deduplication, overlooking the distributional requirements of generation modeling and the heterogeneity of RS imagery. To address these limitations, we propose a training-free, two-stage data pruning approach that quickly select a high-quality subset under high pruning ratios, enabling a preliminary foundation model to converge rapidly and serve as a versatile backbone for generation, downstream fine-tuning, and other applications. Our method jointly considers local information content with global scene-level diversity and representativeness. First, an entropy-based criterion efficiently removes low-information samples. Next, leveraging RS scene classification datasets as reference benchmarks, we perform scene-aware clustering with stratified sampling to improve clustering effectiveness while reducing computational costs on large-scale unlabeled data. Finally, by balancing cluster-level uniformity and sample representativeness, the method enables fine-grained selection under high pruning ratios while preserving overall diversity and representativeness. Experiments show that, even after pruning 85\% of the training data, our method significantly improves convergence and generation quality. Furthermore, diffusion foundation models trained with our method consistently achieve state-of-the-art performance across downstream tasks, including super-resolution and semantic image synthesis. This data pruning paradigm offers practical guidance for developing RS generative foundation models.
Language Generation and Identification From Partial Enumeration: Tight Density Bounds and Topological Characterizations
Nov 07, 2025The success of large language models (LLMs) has motivated formal theories of language generation and learning. We study the framework of \emph{language generation in the limit}, where an adversary enumerates strings from an unknown language $K$ drawn from a countable class, and an algorithm must generate unseen strings from $K$. Prior work showed that generation is always possible, and that some algorithms achieve positive lower density, revealing a \emph{validity--breadth} trade-off between correctness and coverage. We resolve a main open question in this line, proving a tight bound of $1/2$ on the best achievable lower density. We then strengthen the model to allow \emph{partial enumeration}, where the adversary reveals only an infinite subset $C \subseteq K$. We show that generation in the limit remains achievable, and if $C$ has lower density $α$ in $K$, the algorithm's output achieves density at least $α/2$, matching the upper bound. This generalizes the $1/2$ bound to the partial-information setting, where the generator must recover within a factor $1/2$ of the revealed subset's density. We further revisit the classical Gold--Angluin model of \emph{language identification} under partial enumeration. We characterize when identification in the limit is possible -- when hypotheses $M_t$ eventually satisfy $C \subseteq M \subseteq K$ -- and in the process give a new topological formulation of Angluin's characterization, showing that her condition is precisely equivalent to an appropriate topological space having the $T_D$ separation property.
Density Measures for Language Generation
Apr 19, 2025
The recent successes of large language models (LLMs) have led to a surge of theoretical research into language generation. A recent line of work proposes an abstract view, called language generation in the limit, where generation is seen as a game between an adversary and an algorithm: the adversary generates strings from an unknown language $K$, chosen from a countable collection of candidate languages, and after seeing a finite set of these strings, the algorithm must generate new strings from $K$ that it has not seen before. This formalism highlights a key tension: the trade-off between validity (the algorithm should only produce strings from the language) and breadth (it should be able to produce many strings from the language). This trade-off is central in applied language generation as well, where it appears as a balance between hallucination (generating invalid utterances) and mode collapse (generating only a restricted set of outputs). Despite its importance, this trade-off has been challenging to study quantitatively. We develop ways to quantify this trade-off by formalizing breadth using measures of density. Existing algorithms for language generation in the limit produce output sets that can have zero density in the true language, and this important failure of breadth might seem unavoidable. We show, however, that such a failure is not necessary: we provide an algorithm for language generation in the limit whose outputs have strictly positive density in $K$. We also study the internal representations built by these algorithms, specifically the sequence of hypothesized candidate languages they consider, and show that achieving the strongest form of breadth may require oscillating indefinitely between high- and low-density representations. Our analysis introduces a novel topology on language families, with notions of convergence and limit points playing a key role.
Constructing a Norm for Children's Scientific Drawing: Distribution Features Based on Semantic Similarity of Large Language Models
Feb 21, 2025The use of children's drawings to examining their conceptual understanding has been proven to be an effective method, but there are two major problems with previous research: 1. The content of the drawings heavily relies on the task, and the ecological validity of the conclusions is low; 2. The interpretation of drawings relies too much on the subjective feelings of the researchers. To address this issue, this study uses the Large Language Model (LLM) to identify 1420 children's scientific drawings (covering 9 scientific themes/concepts), and uses the word2vec algorithm to calculate their semantic similarity. The study explores whether there are consistent drawing representations for children on the same theme, and attempts to establish a norm for children's scientific drawings, providing a baseline reference for follow-up children's drawing research. The results show that the representation of most drawings has consistency, manifested as most semantic similarity greater than 0.8. At the same time, it was found that the consistency of the representation is independent of the accuracy (of LLM's recognition), indicating the existence of consistency bias. In the subsequent exploration of influencing factors, we used Kendall rank correlation coefficient to investigate the effects of Sample Size, Abstract Degree, and Focus Points on drawings, and used word frequency statistics to explore whether children represented abstract themes/concepts by reproducing what was taught in class.
Computer Analysis of Architecture Using Automatic Image Understanding
Oct 17, 2018



In the past few years, computer vision and pattern recognition systems have been becoming increasingly more powerful, expanding the range of automatic tasks enabled by machine vision. Here we show that computer analysis of building images can perform quantitative analysis of architecture, and quantify similarities between city architectural styles in a quantitative fashion. Images of buildings from 18 cities and three countries were acquired using Google StreetView, and were used to train a machine vision system to automatically identify the location of the imaged building based on the image visual content. Experimental results show that the automatic computer analysis can automatically identify the geographical location of the StreetView image. More importantly, the algorithm was able to group the cities and countries and provide a phylogeny of the similarities between architectural styles as captured by StreetView images. These results demonstrate that computer vision and pattern recognition algorithms can perform the complex cognitive task of analyzing images of buildings, and can be used to measure and quantify visual similarities and differences between different styles of architectures. This experiment provides a new paradigm for studying architecture, based on a quantitative approach that can enhance the traditional manual observation and analysis. The source code used for the analysis is open and publicly available.
Self-Paced Multi-Task Learning
Apr 03, 2017
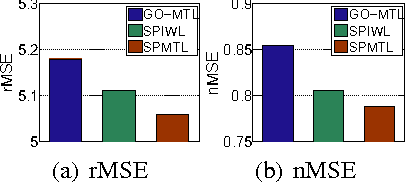

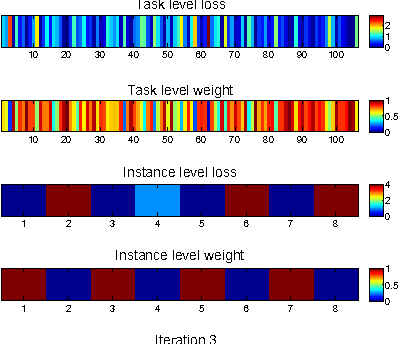
In this paper, we propose a novel multi-task learning (MTL) framework, called Self-Paced Multi-Task Learning (SPMTL). Different from previous works treating all tasks and instances equally when training, SPMTL attempts to jointly learn the tasks by taking into consideration the complexities of both tasks and instances. This is inspired by the cognitive process of human brain that often learns from the easy to the hard. We construct a compact SPMTL formulation by proposing a new task-oriented regularizer that can jointly prioritize the tasks and the instances. Thus it can be interpreted as a self-paced learner for MTL. A simple yet effective algorithm is designed for optimizing the proposed objective function. An error bound for a simplified formulation is also analyzed theoretically. Experimental results on toy and real-world datasets demonstrate the effectiveness of the proposed approach, compared to the state-of-the-art methods.
A Self-Paced Regularization Framework for Multi-Label Learning
Apr 06, 2016
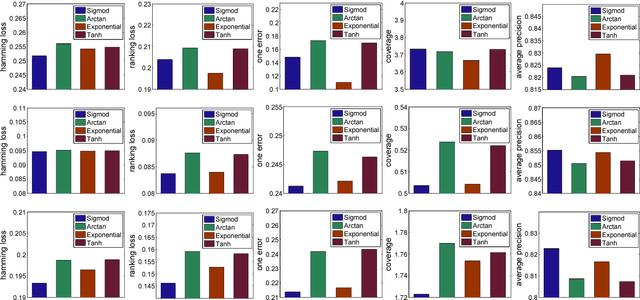
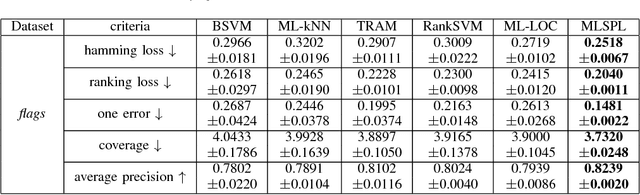
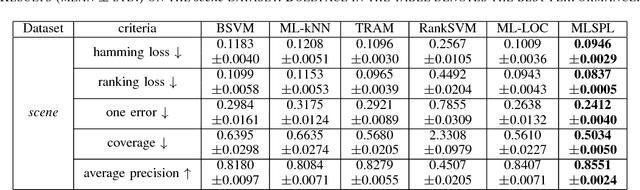
In this paper, we propose a novel multi-label learning framework, called Multi-Label Self-Paced Learning (MLSPL), in an attempt to incorporate the self-paced learning strategy into multi-label learning regime. In light of the benefits of adopting the easy-to-hard strategy proposed by self-paced learning, the devised MLSPL aims to learn multiple labels jointly by gradually including label learning tasks and instances into model training from the easy to the hard. We first introduce a self-paced function as a regularizer in the multi-label learning formulation, so as to simultaneously rank priorities of the label learning tasks and the instances in each learning iteration. Considering that different multi-label learning scenarios often need different self-paced schemes during optimization, we thus propose a general way to find the desired self-paced functions. Experimental results on three benchmark datasets suggest the state-of-the-art performance of our approach.
Dynamic Structure Embedded Online Multiple-Output Regression for Stream Data
Sep 08, 2015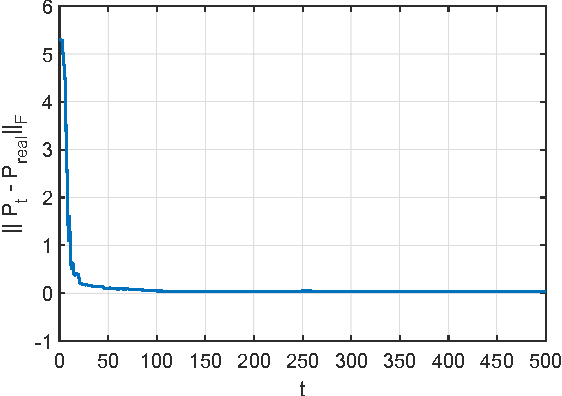
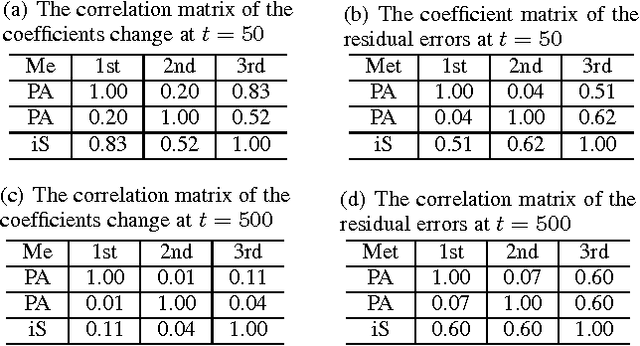
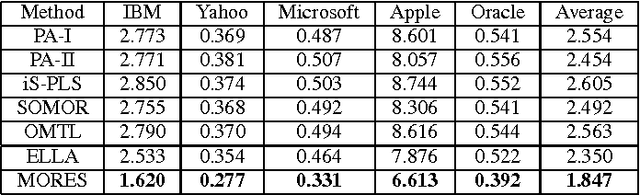
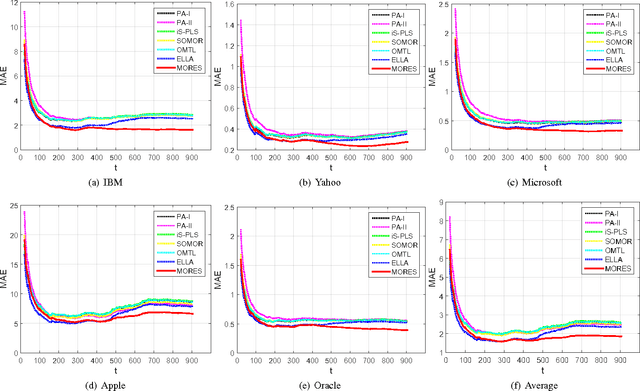
Online multiple-output regression is an important machine learning technique for modeling, predicting, and compressing multi-dimensional correlated data streams. In this paper, we propose a novel online multiple-output regression method, called MORES, for stream data. MORES can \emph{dynamically} learn the structure of the coefficients change in each update step to facilitate the model's continuous refinement. We observe that limited expressive ability of the regression model, especially in the preliminary stage of online update, often leads to the variables in the residual errors being dependent. In light of this point, MORES intends to \emph{dynamically} learn and leverage the structure of the residual errors to improve the prediction accuracy. Moreover, we define three statistical variables to \emph{exactly} represent all the seen samples for \emph{incrementally} calculating prediction loss in each online update round, which can avoid loading all the training data into memory for updating model, and also effectively prevent drastic fluctuation of the model in the presence of noise. Furthermore, we introduce a forgetting factor to set different weights on samples so as to track the data streams' evolving characteristics quickly from the latest samples. Experiments on one synthetic dataset and three real-world datasets validate the effectiveness of the proposed method. In addition, the update speed of MORES is at least 2000 samples processed per second on the three real-world datasets, more than 15 times faster than the state-of-the-art online learning algorithm.