 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAZE: Grounded Refinement and Motion-Aware Zero-Shot Event Localization
Apr 01, 2026American football practice generates video at scale, yet the interaction of interest occupies only a brief window of each long, untrimmed clip. Reliable biomechanical analysis, therefore, depends on spatiotemporal localization that identifies both the interacting entities and the onset of contact. We study First Point of Contact (FPOC), defined as the first frame in which a player physically touches a tackle dummy, in unconstrained practice footage with camera motion, clutter, multiple similarly equipped athletes, and rapid pose changes around impact. We present GRAZE, a training-free pipeline for FPOC localization that requires no labeled tackle-contact examples. GRAZE uses Grounding DINO to discover candidate player-dummy interactions, refines them with motion-aware temporal reasoning, and uses SAM2 as an explicit pixel-level verifier of contact rather than relying on detection confidence alone. This separation between candidate discovery and contact confirmation makes the approach robust to cluttered scenes and unstable grounding near impact. On 738 tackle-practice videos, GRAZE produces valid outputs for 97.4% of clips and localizes FPOC within $\pm$ 10 frames on 77.5% of all clips and within $\pm$ 20 frames on 82.7% of all clips. These results show that frame-accurate contact onset localization in real-world practice footage is feasible without task-specific training.
Unmasking Biases and Reliability Concerns in Convolutional Neural Networks Analysis of Cancer Pathology Images
Mar 12, 2026Convolutional Neural Networks have shown promising effectiveness in identifying different types of cancer from radiographs. However, the opaque nature of CNNs makes it difficult to fully understand the way they operate, limiting their assessment to empirical evaluation. Here we study the soundness of the standard practices by which CNNs are evaluated for the purpose of cancer pathology. Thirteen highly used cancer benchmark datasets were analyzed, using four common CNN architectures and different types of cancer, such as melanoma, carcinoma, colorectal cancer, and lung cancer. We compared the accuracy of each model with that of datasets made of cropped segments from the background of the original images that do not contain clinically relevant content. Because the rendered datasets contain no clinical information, the null hypothesis is that the CNNs should provide mere chance-based accuracy when classifying these datasets. The results show that the CNN models provided high accuracy when using the cropped segments, sometimes as high as 93\%, even though they lacked biomedical information. These results show that some CNN architectures are more sensitive to bias than others. The analysis shows that the common practices of machine learning evaluation might lead to unreliable results when applied to cancer pathology. These biases are very difficult to identify, and might mislead researchers as they use available benchmark datasets to test the efficacy of CNN methods.
* Electronics, published
CornViT: A Multi-Stage Convolutional Vision Transformer Framework for Hierarchical Corn Kernel Analysis
Dec 31, 2025Accurate grading of corn kernels is critical for seed certification, directional seeding, and breeding, yet it is still predominantly performed by manual inspection. This work introduces CornViT, a three-stage Convolutional Vision Transformer (CvT) framework that emulates the hierarchical reasoning of human seed analysts for single-kernel evaluation. Three sequential CvT-13 classifiers operate on 384x384 RGB images: Stage 1 distinguishes pure from impure kernels; Stage 2 categorizes pure kernels into flat and round morphologies; and Stage 3 determines the embryo orientation (up vs. down) for pure, flat kernels. Starting from a public corn seed image collection, we manually relabeled and filtered images to construct three stage-specific datasets: 7265 kernels for purity, 3859 pure kernels for morphology, and 1960 pure-flat kernels for embryo orientation, all released as benchmarks. Head-only fine-tuning of ImageNet-22k pretrained CvT-13 backbones yields test accuracies of 93.76% for purity, 94.11% for shape, and 91.12% for embryo-orientation detection. Under identical training conditions, ResNet-50 reaches only 76.56 to 81.02 percent, whereas DenseNet-121 attains 86.56 to 89.38 percent accuracy. These results highlight the advantages of convolution-augmented self-attention for kernel analysis. To facilitate adoption, we deploy CornViT in a Flask-based web application that performs stage-wise inference and exposes interpretable outputs through a browser interface. Together, the CornViT framework, curated datasets, and web application provide a deployable solution for automated corn kernel quality assessment in seed quality workflows. Source code and data are publicly available.
* 23 pages
Galaxy image simplification using Generative AI
Jul 15, 2025Modern digital sky surveys have been acquiring images of billions of galaxies. While these images often provide sufficient details to analyze the shape of the galaxies, accurate analysis of such high volumes of images requires effective automation. Current solutions often rely on machine learning annotation of the galaxy images based on a set of pre-defined classes. Here we introduce a new approach to galaxy image analysis that is based on generative AI. The method simplifies the galaxy images and automatically converts them into a ``skeletonized" form. The simplified images allow accurate measurements of the galaxy shapes and analysis that is not limited to a certain pre-defined set of classes. We demonstrate the method by applying it to galaxy images acquired by the DESI Legacy Survey. The code and data are publicly available. The method was applied to 125,000 DESI Legacy Survey images, and the catalog of the simplified images is publicly available.
Identifying Bias in Deep Neural Networks Using Image Transforms
Dec 17, 2024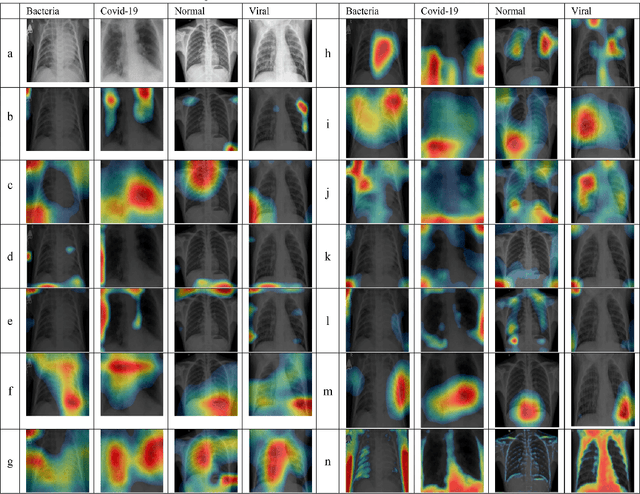
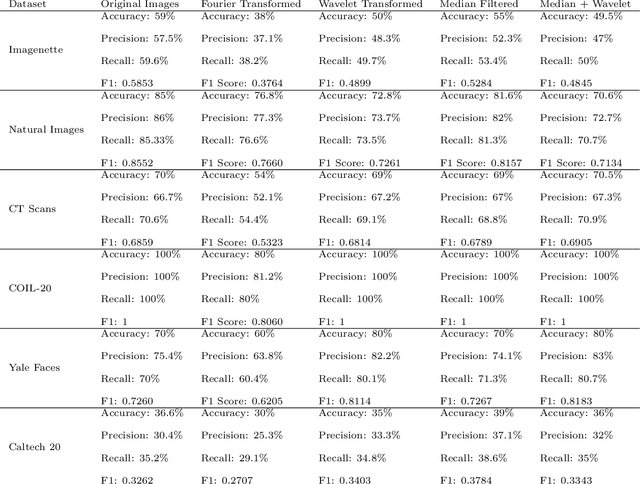


CNNs have become one of the most commonly used computational tool in the past two decades. One of the primary downsides of CNNs is that they work as a ``black box", where the user cannot necessarily know how the image data are analyzed, and therefore needs to rely on empirical evaluation to test the efficacy of a trained CNN. This can lead to hidden biases that affect the performance evaluation of neural networks, but are difficult to identify. Here we discuss examples of such hidden biases in common and widely used benchmark datasets, and propose techniques for identifying dataset biases that can affect the standard performance evaluation metrics. One effective approach to identify dataset bias is to perform image classification by using merely blank background parts of the original images. However, in some situations a blank background in the images is not available, making it more difficult to separate foreground or contextual information from the bias. To overcome this, we propose a method to identify dataset bias without the need to crop background information from the images. That method is based on applying several image transforms to the original images, including Fourier transform, wavelet transforms, median filter, and their combinations. These transforms were applied to recover background bias information that CNNs use to classify images. This transformations affect the contextual visual information in a different manner than it affects the systemic background bias. Therefore, the method can distinguish between contextual information and the bias, and alert on the presence of background bias even without the need to separate sub-images parts from the blank background of the original images. Code used in the experiments is publicly available.
* Computers, published
Analysis and prevention of AI-based phishing email attacks
May 08, 2024Phishing email attacks are among the most common and most harmful cybersecurity attacks. With the emergence of generative AI, phishing attacks can be based on emails generated automatically, making it more difficult to detect them. That is, instead of a single email format sent to a large number of recipients, generative AI can be used to send each potential victim a different email, making it more difficult for cybersecurity systems to identify the scam email before it reaches the recipient. Here we describe a corpus of AI-generated phishing emails. We also use different machine learning tools to test the ability of automatic text analysis to identify AI-generated phishing emails. The results are encouraging, and show that machine learning tools can identify an AI-generated phishing email with high accuracy compared to regular emails or human-generated scam email. By applying descriptive analytic, the specific differences between AI-generated emails and manually crafted scam emails are profiled, and show that AI-generated emails are different in their style from human-generated phishing email scams. Therefore, automatic identification tools can be used as a warning for the user. The paper also describes the corpus of AI-generated phishing emails that is made open to the public, and can be used for consequent studies. While the ability of machine learning to detect AI-generated phishing email is encouraging, AI-generated phishing emails are different from regular phishing emails, and therefore it is important to train machine learning systems also with AI-generated emails in order to repel future phishing attacks that are powered by generative AI.
Outlier galaxy images in the Dark Energy Survey and their identification with unsupervised machine learning
May 02, 2023The Dark Energy Survey is able to collect image data of an extremely large number of extragalactic objects, and it can be reasonably assumed that many unusual objects of high scientific interest are hidden inside these data. Due to the extreme size of DES data, identifying these objects among many millions of other celestial objects is a challenging task. The problem of outlier detection is further magnified by the presence of noisy or saturated images. When the number of tested objects is extremely high, even a small rate of noise or false positives leads to a very large number of false detections, making an automatic system impractical. This study applies an automatic method for automatic detection of outlier objects in the first data release of the Dark Energy Survey. By using machine learning-based outlier detection, the algorithm is able to identify objects that are visually different from the majority of the other objects in the database. An important feature of the algorithm is that it allows to control the false-positive rate, and therefore can be used for practical outlier detection. The algorithm does not provide perfect accuracy in the detection of outlier objects, but it reduces the data substantially to allow practical outlier detection. For instance, the selection of the top 250 objects after applying the algorithm to more than $2\cdot10^6$ DES images provides a collection of uncommon galaxies. Such collection would have been extremely time-consuming to compile by using manual inspection of the data.
A data science and machine learning approach to continuous analysis of Shakespeare's plays
Jan 15, 2023The availability of quantitative methods that can analyze text has provided new ways of examining literature in a manner that was not available in the pre-information era. Here we apply comprehensive machine learning analysis to the work of William Shakespeare. The analysis shows clear change in style of writing over time, with the most significant changes in the sentence length, frequency of adjectives and adverbs, and the sentiments expressed in the text. Applying machine learning to make a stylometric prediction of the year of the play shows a Pearson correlation of 0.71 between the actual and predicted year, indicating that Shakespeare's writing style as reflected by the quantitative measurements changed over time. Additionally, it shows that the stylometrics of some of the plays is more similar to plays written either before or after the year they were written. For instance, Romeo and Juliet is dated 1596, but is more similar in stylometrics to plays written by Shakespeare after 1600. The source code for the analysis is available for free download.
Self-Supervised Approach to Addressing Zero-Shot Learning Problem
Jan 21, 2022
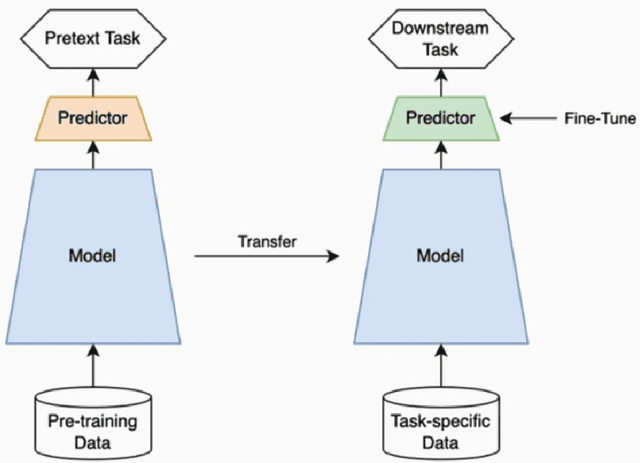
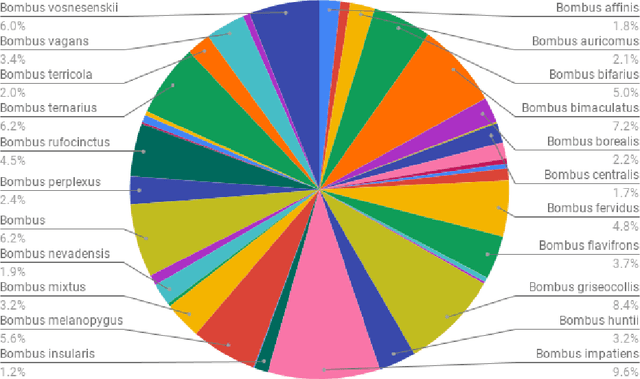
In recent years, self-supervised learning has had significant success in applications involving computer vision and natural language processing. The type of pretext task is important to this boost in performance. One common pretext task is the measure of similarity and dissimilarity between pairs of images. In this scenario, the two images that make up the negative pair are visibly different to humans. However, in entomology, species are nearly indistinguishable and thus hard to differentiate. In this study, we explored the performance of a Siamese neural network using contrastive loss by learning to push apart embeddings of bumblebee species pair that are dissimilar, and pull together similar embeddings. Our experimental results show a 61% F1-score on zero-shot instances, a performance showing 11% improvement on samples of classes that share intersections with the training set.
Systematic biases when using deep neural networks for annotating large catalogs of astronomical images
Jan 10, 2022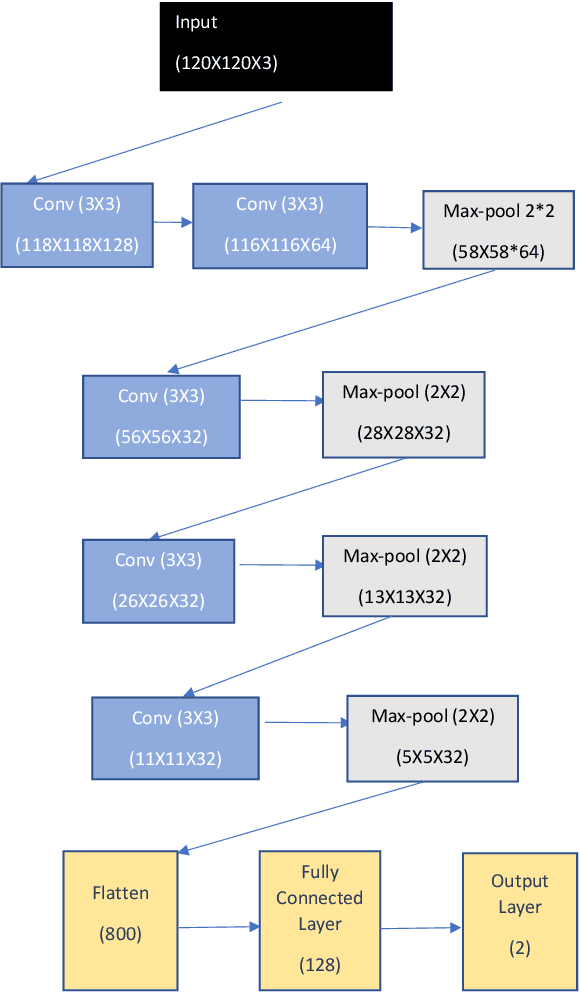
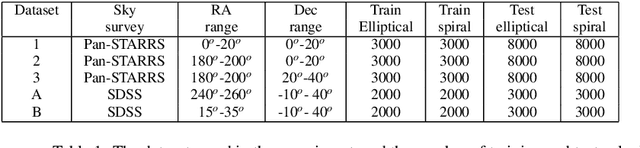
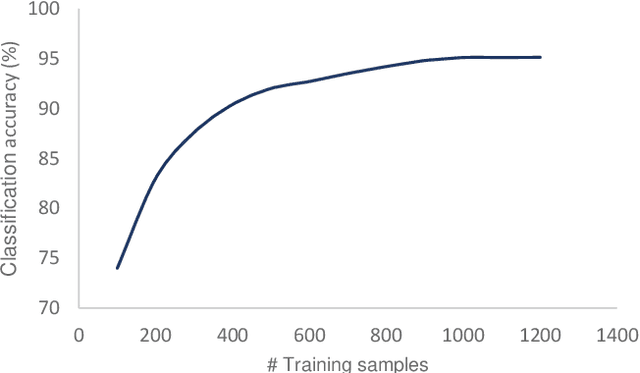

Deep convolutional neural networks (DCNNs) have become the most common solution for automatic image annotation due to their non-parametric nature, good performance, and their accessibility through libraries such as TensorFlow. Among other fields, DCNNs are also a common approach to the annotation of large astronomical image databases acquired by digital sky surveys. One of the main downsides of DCNNs is the complex non-intuitive rules that make DCNNs act as a ``black box", providing annotations in a manner that is unclear to the user. Therefore, the user is often not able to know what information is used by the DCNNs for the classification. Here we demonstrate that the training of a DCNN is sensitive to the context of the training data such as the location of the objects in the sky. We show that for basic classification of elliptical and spiral galaxies, the sky location of the galaxies used for training affects the behavior of the algorithm, and leads to a small but consistent and statistically significant bias. That bias exhibits itself in the form of cosmological-scale anisotropy in the distribution of basic galaxy morphology. Therefore, while DCNNs are powerful tools for annotating images of extended sources, the construction of training sets for galaxy morphology should take into consideration more aspects than the visual appearance of the object. In any case, catalogs created with deep neural networks that exhibit signs of cosmological anisotropy should be interpreted with the possibility of consistent bias.