 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Active Learning with Feature Selection via CUR Matrix Decomposition
Sep 09, 2018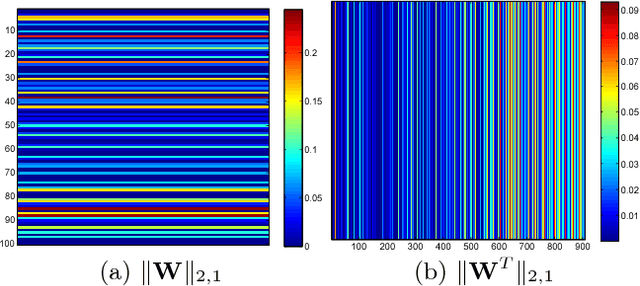
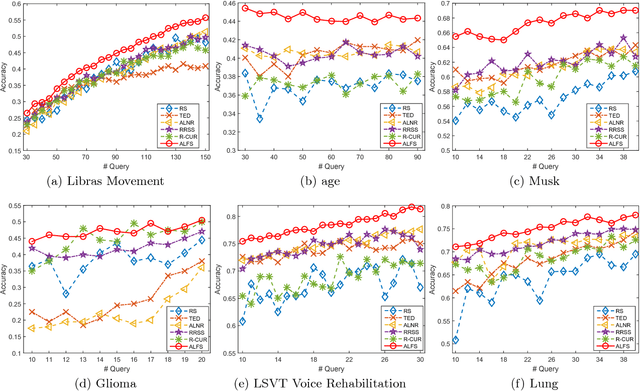
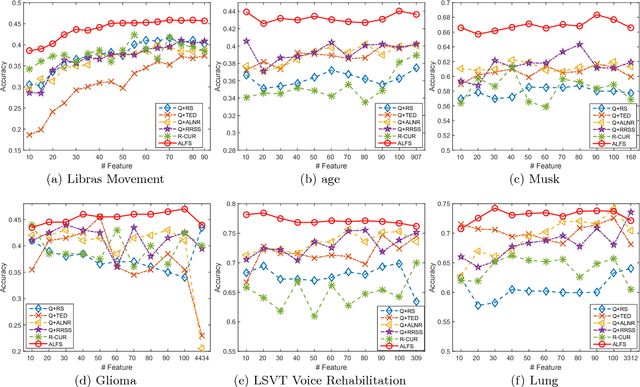
This paper presents an unsupervised learning approach for simultaneous sample and feature selection, which is in contrast to existing works which mainly tackle these two problems separately. In fact the two tasks are often interleaved with each other: noisy and high-dimensional features will bring adverse effect on sample selection, while informative or representative samples will be beneficial to feature selection. Specifically, we propose a framework to jointly conduct active learning and feature selection based on the CUR matrix decomposition. From the data reconstruction perspective, both the selected samples and features can best approximate the original dataset respectively, such that the selected samples characterized by the features are highly representative. In particular, our method runs in one-shot without the procedure of iterative sample selection for progressive labeling. Thus, our model is especially suitable when there are few labeled samples or even in the absence of supervision, which is a particular challenge for existing methods. As the joint learning problem is NP-hard, the proposed formulation involves a convex but non-smooth optimization problem. We solve it efficiently by an iterative algorithm, and prove its global convergence. Experimental results on publicly available datasets corroborate the efficacy of our method compared with the state-of-the-art.
An Anti-fraud System for Car Insurance Claim Based on Visual Evidence
Apr 30, 2018
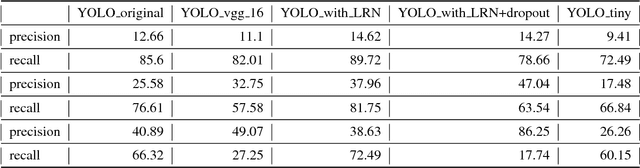

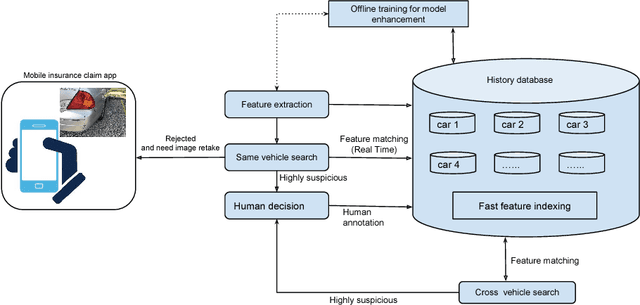
Automatically scene understanding using machine learning algorithms has been widely applied to different industries to reduce the cost of manual labor. Nowadays, insurance companies launch express vehicle insurance claim and settlement by allowing customers uploading pictures taken by mobile devices. This kind of insurance claim is treated as small claim and can be processed either manually or automatically in a quick fashion. However, due to the increasing amount of claims every day, system or people are likely to be fooled by repeated claims for identical case leading to big lost to insurance companies.Thus, an anti-fraud checking before processing the claim is necessary. We create the first data set of car damage images collected from internet and local parking lots. In addition, we proposed an approach to generate robust deep features by locating the damages accurately and efficiently in the images. The state-of-the-art real-time object detector YOLO \cite{redmon2016you}is modified to train and discover damage region as an important part of the pipeline. Both local and global deep features are extracted using VGG model\cite{Simonyan14c}, which are fused later for more robust system performance. Experiments show our approach is effective in preventing fraud claims as well as meet the requirement to speed up the insurance claim prepossessing.
Max-Margin based Discriminative Feature Learning
Apr 03, 2017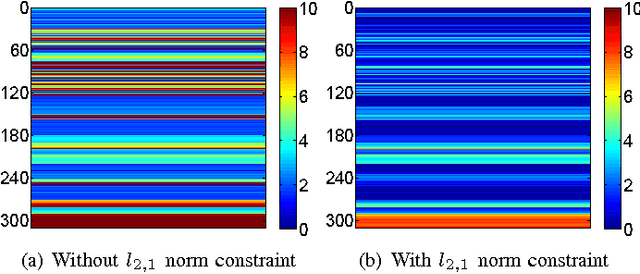
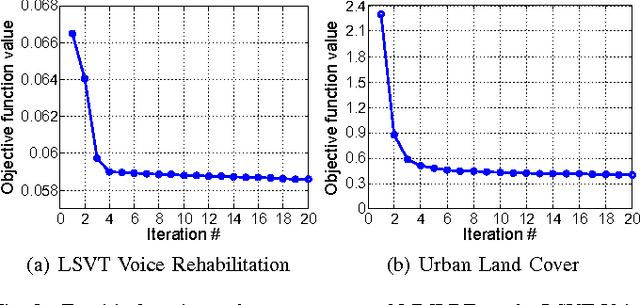
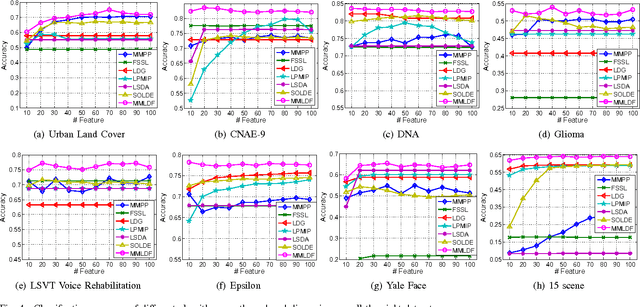
In this paper, we propose a new max-margin based discriminative feature learning method. Specifically, we aim at learning a low-dimensional feature representation, so as to maximize the global margin of the data and make the samples from the same class as close as possible. In order to enhance the robustness to noise, a $l_{2,1}$ norm constraint is introduced to make the transformation matrix in group sparsity. In addition, for multi-class classification tasks, we further intend to learn and leverage the correlation relationships among multiple class tasks for assisting in learning discriminative features. The experimental results demonstrate the power of the proposed method against the related state-of-the-art methods.
Self-Paced Multi-Task Learning
Apr 03, 2017
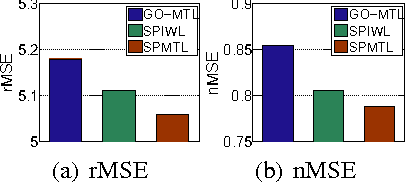

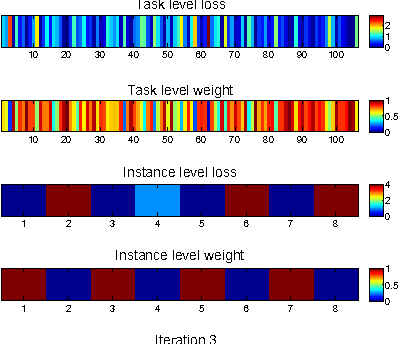
In this paper, we propose a novel multi-task learning (MTL) framework, called Self-Paced Multi-Task Learning (SPMTL). Different from previous works treating all tasks and instances equally when training, SPMTL attempts to jointly learn the tasks by taking into consideration the complexities of both tasks and instances. This is inspired by the cognitive process of human brain that often learns from the easy to the hard. We construct a compact SPMTL formulation by proposing a new task-oriented regularizer that can jointly prioritize the tasks and the instances. Thus it can be interpreted as a self-paced learner for MTL. A simple yet effective algorithm is designed for optimizing the proposed objective function. An error bound for a simplified formulation is also analyzed theoretically. Experimental results on toy and real-world datasets demonstrate the effectiveness of the proposed approach, compared to the state-of-the-art methods.
Autoencoder Regularized Network For Driving Style Representation Learning
Jan 05, 2017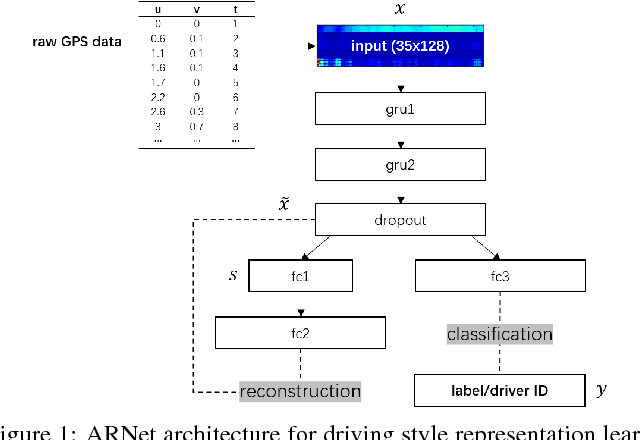
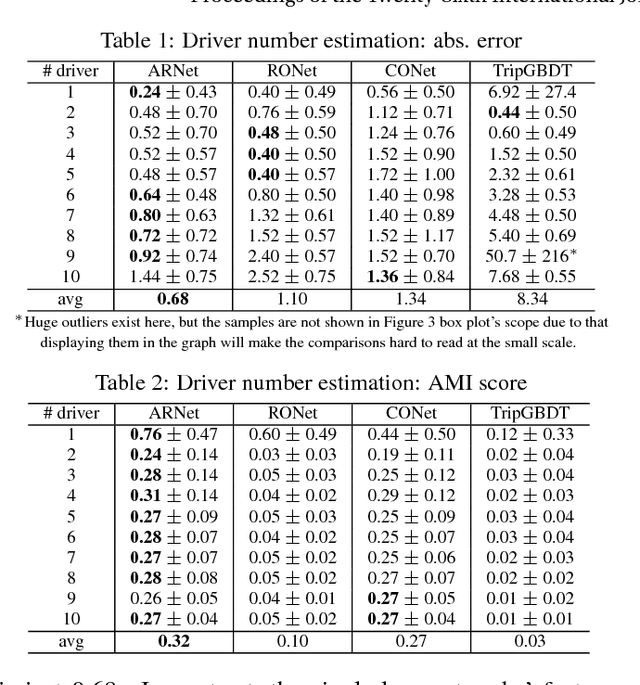
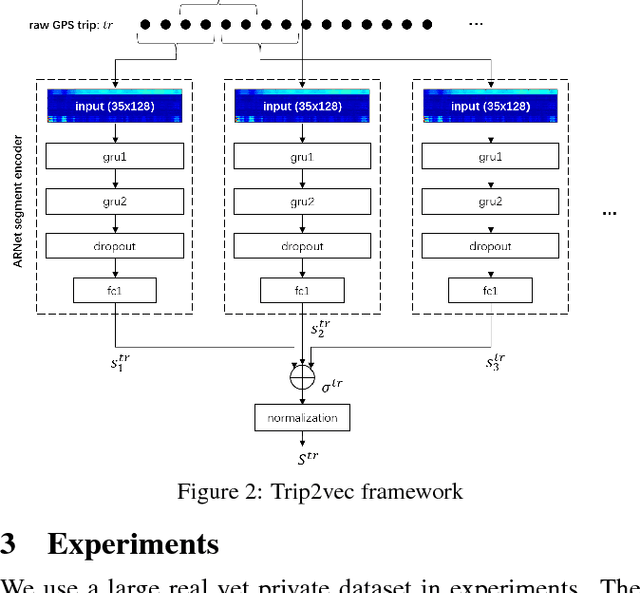
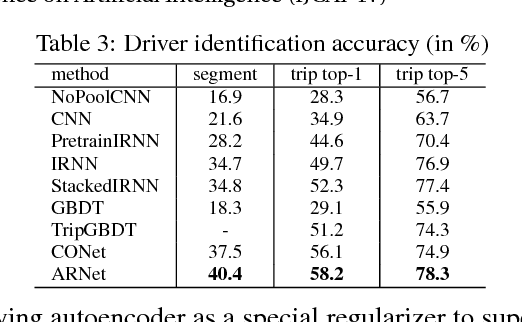
In this paper, we study learning generalized driving style representations from automobile GPS trip data. We propose a novel Autoencoder Regularized deep neural Network (ARNet) and a trip encoding framework trip2vec to learn drivers' driving styles directly from GPS records, by combining supervised and unsupervised feature learning in a unified architecture. Experiments on a challenging driver number estimation problem and the driver identification problem show that ARNet can learn a good generalized driving style representation: It significantly outperforms existing methods and alternative architectures by reaching the least estimation error on average (0.68, less than one driver) and the highest identification accuracy (by at least 3% improvement) compared with traditional supervised learning methods.
Characterizing Driving Styles with Deep Learning
Oct 08, 2016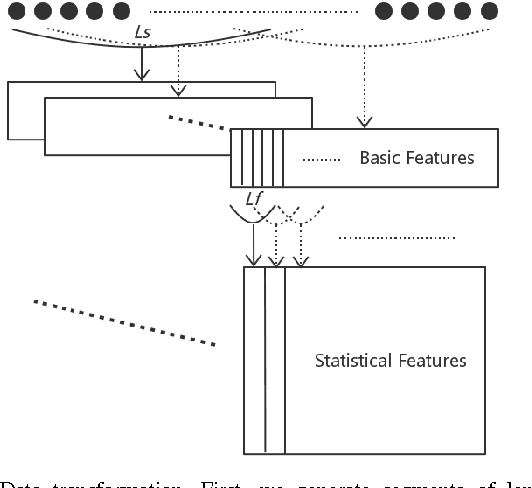
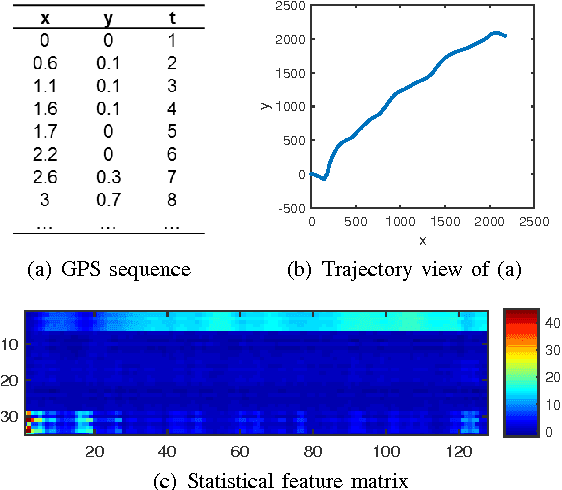
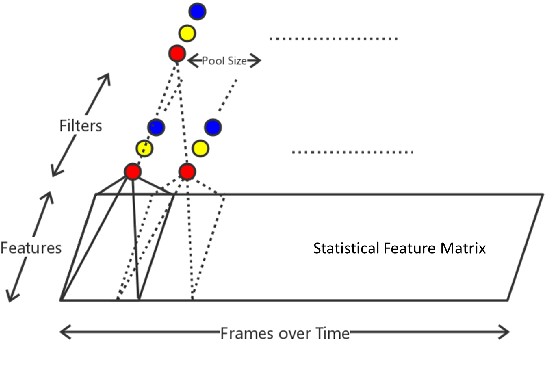
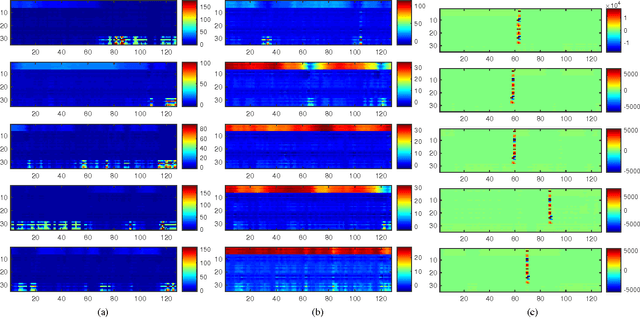
Characterizing driving styles of human drivers using vehicle sensor data, e.g., GPS, is an interesting research problem and an important real-world requirement from automotive industries. A good representation of driving features can be highly valuable for autonomous driving, auto insurance, and many other application scenarios. However, traditional methods mainly rely on handcrafted features, which limit machine learning algorithms to achieve a better performance. In this paper, we propose a novel deep learning solution to this problem, which could be the first attempt of extending deep learning to driving behavior analysis based on GPS data. The proposed approach can effectively extract high level and interpretable features describing complex driving patterns. It also requires significantly less human experience and work. The power of the learned driving style representations are validated through the driver identification problem using a large real dataset.
A Self-Paced Regularization Framework for Multi-Label Learning
Apr 06, 2016
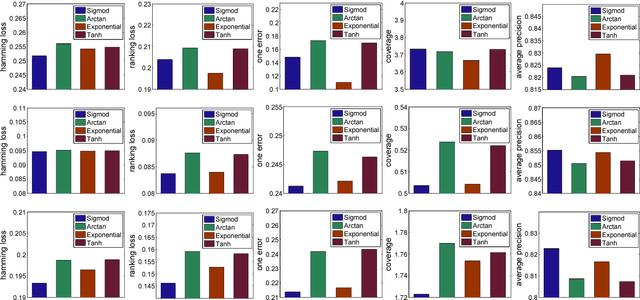
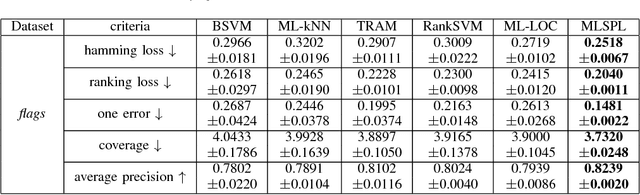
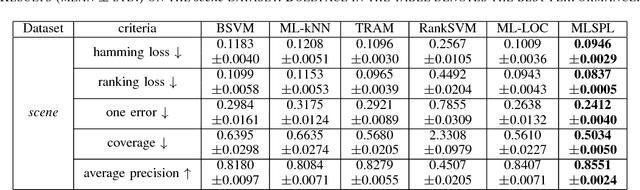
In this paper, we propose a novel multi-label learning framework, called Multi-Label Self-Paced Learning (MLSPL), in an attempt to incorporate the self-paced learning strategy into multi-label learning regime. In light of the benefits of adopting the easy-to-hard strategy proposed by self-paced learning, the devised MLSPL aims to learn multiple labels jointly by gradually including label learning tasks and instances into model training from the easy to the hard. We first introduce a self-paced function as a regularizer in the multi-label learning formulation, so as to simultaneously rank priorities of the label learning tasks and the instances in each learning iteration. Considering that different multi-label learning scenarios often need different self-paced schemes during optimization, we thus propose a general way to find the desired self-paced functions. Experimental results on three benchmark datasets suggest the state-of-the-art performance of our approach.
Dynamic Structure Embedded Online Multiple-Output Regression for Stream Data
Sep 08, 2015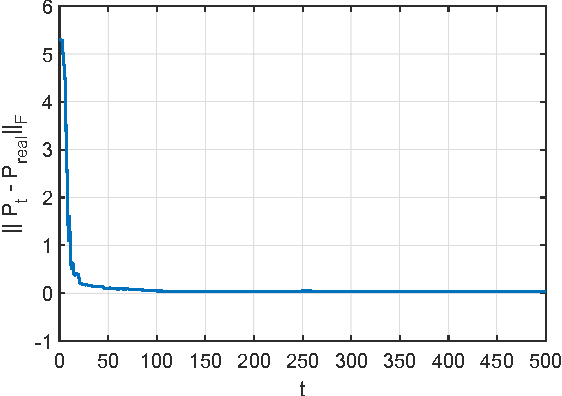
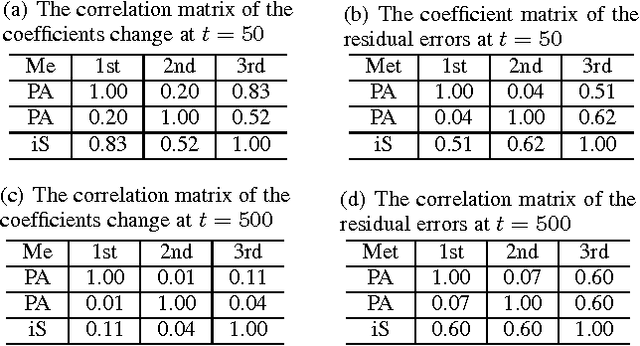
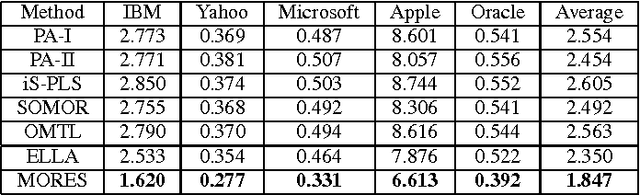
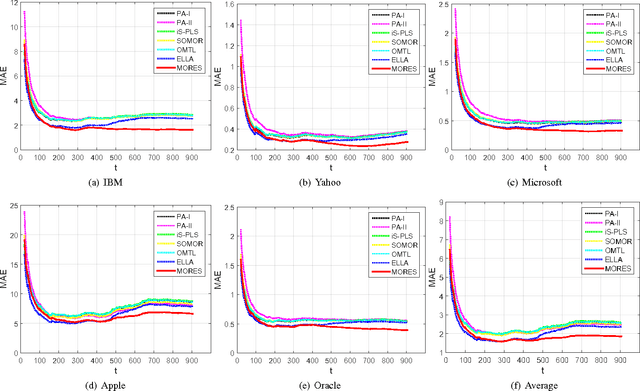
Online multiple-output regression is an important machine learning technique for modeling, predicting, and compressing multi-dimensional correlated data streams. In this paper, we propose a novel online multiple-output regression method, called MORES, for stream data. MORES can \emph{dynamically} learn the structure of the coefficients change in each update step to facilitate the model's continuous refinement. We observe that limited expressive ability of the regression model, especially in the preliminary stage of online update, often leads to the variables in the residual errors being dependent. In light of this point, MORES intends to \emph{dynamically} learn and leverage the structure of the residual errors to improve the prediction accuracy. Moreover, we define three statistical variables to \emph{exactly} represent all the seen samples for \emph{incrementally} calculating prediction loss in each online update round, which can avoid loading all the training data into memory for updating model, and also effectively prevent drastic fluctuation of the model in the presence of noise. Furthermore, we introduce a forgetting factor to set different weights on samples so as to track the data streams' evolving characteristics quickly from the latest samples. Experiments on one synthetic dataset and three real-world datasets validate the effectiveness of the proposed method. In addition, the update speed of MORES is at least 2000 samples processed per second on the three real-world datasets, more than 15 times faster than the state-of-the-art online learning algorithm.
Scaling Up Estimation of Distribution Algorithms For Continuous Optimization
Nov 09, 2011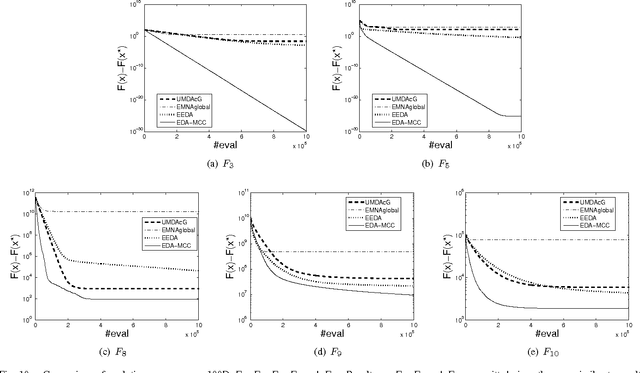
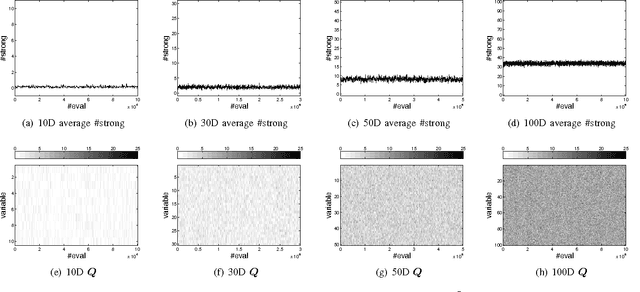
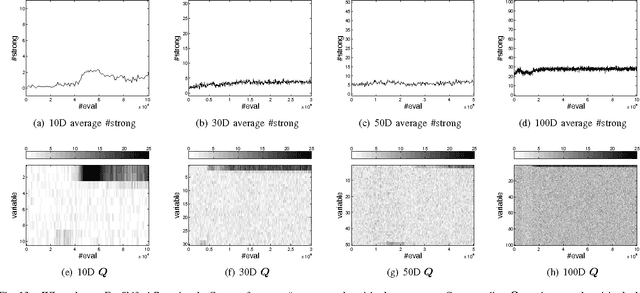
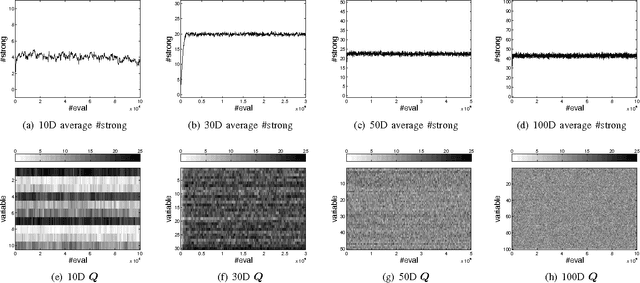
Since Estimation of Distribution Algorithms (EDA) were proposed, many attempts have been made to improve EDAs' performance in the context of global optimization. So far, the studies or applications of multivariate probabilistic model based continuous EDAs are still restricted to rather low dimensional problems (smaller than 100D). Traditional EDAs have difficulties in solving higher dimensional problems because of the curse of dimensionality and their rapidly increasing computational cost. However, scaling up continuous EDAs for higher dimensional optimization is still necessary, which is supported by the distinctive feature of EDAs: Because a probabilistic model is explicitly estimated, from the learnt model one can discover useful properties or features of the problem. Besides obtaining a good solution, understanding of the problem structure can be of great benefit, especially for black box optimization. We propose a novel EDA framework with Model Complexity Control (EDA-MCC) to scale up EDAs. By using Weakly dependent variable Identification (WI) and Subspace Modeling (SM), EDA-MCC shows significantly better performance than traditional EDAs on high dimensional problems. Moreover, the computational cost and the requirement of large population sizes can be reduced in EDA-MCC. In addition to being able to find a good solution, EDA-MCC can also produce a useful problem structure characterization. EDA-MCC is the first successful instance of multivariate model based EDAs that can be effectively applied a general class of up to 500D problems. It also outperforms some newly developed algorithms designed specifically for large scale optimization. In order to understand the strength and weakness of EDA-MCC, we have carried out extensive computational studies of EDA-MCC. Our results have revealed when EDA-MCC is likely to outperform others on what kind of benchmark functions.