 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTone Matters: The Impact of Linguistic Tone on Hallucination in VLMs
Jan 10, 2026Vision-Language Models (VLMs) are increasingly used in safety-critical applications that require reliable visual grounding. However, these models often hallucinate details that are not present in the image to satisfy user prompts. While recent datasets and benchmarks have been introduced to evaluate systematic hallucinations in VLMs, many hallucination behaviors remain insufficiently characterized. In particular, prior work primarily focuses on object presence or absence, leaving it unclear how prompt phrasing and structural constraints can systematically induce hallucinations. In this paper, we investigate how different forms of prompt pressure influence hallucination behavior. We introduce Ghost-100, a procedurally generated dataset of synthetic scenes in which key visual details are deliberately removed, enabling controlled analysis of absence-based hallucinations. Using a structured 5-Level Prompt Intensity Framework, we vary prompts from neutral queries to toxic demands and rigid formatting constraints. We evaluate three representative open-weight VLMs: MiniCPM-V 2.6-8B, Qwen2-VL-7B, and Qwen3-VL-8B. Across all three models, hallucination rates do not increase monotonically with prompt intensity. All models exhibit reductions at higher intensity levels at different thresholds, though not all show sustained reduction under maximum coercion. These results suggest that current safety alignment is more effective at detecting semantic hostility than structural coercion, revealing model-specific limitations in handling compliance pressure. Our dataset is available at: https://github.com/bli1/tone-matters
Proof-of-Federated-Learning-Subchain: Free Partner Selection Subchain Based on Federated Learning
Jul 30, 2023



The continuous thriving of the Blockchain society motivates research in novel designs of schemes supporting cryptocurrencies. Previously multiple Proof-of-Deep-Learning(PoDL) consensuses have been proposed to replace hashing with useful work such as deep learning model training tasks. The energy will be more efficiently used while maintaining the ledger. However deep learning models are problem-specific and can be extremely complex. Current PoDL consensuses still require much work to realize in the real world. In this paper, we proposed a novel consensus named Proof-of-Federated-Learning-Subchain(PoFLSC) to fill the gap. We applied a subchain to record the training, challenging, and auditing activities and emphasized the importance of valuable datasets in partner selection. We simulated 20 miners in the subchain to demonstrate the effectiveness of PoFLSC. When we reduce the pool size concerning the reservation priority order, the drop rate difference in the performance in different scenarios further exhibits that the miner with a higher Shapley Value (SV) will gain a better opportunity to be selected when the size of the subchain pool is limited. In the conducted experiments, the PoFLSC consensus supported the subchain manager to be aware of reservation priority and the core partition of contributors to establish and maintain a competitive subchain.
A Study of the Human Perception of Synthetic Faces
Nov 08, 2021


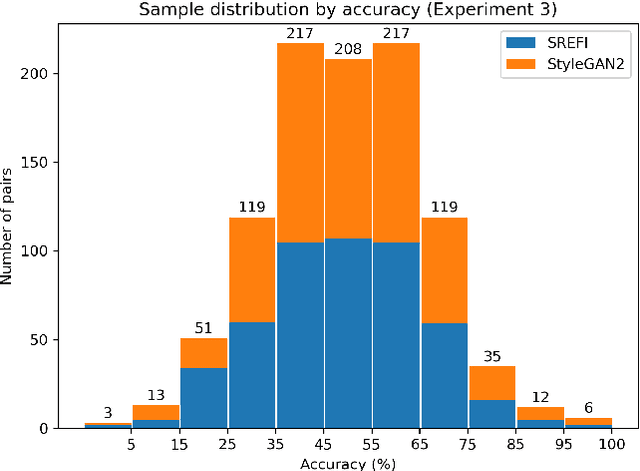
Advances in face synthesis have raised alarms about the deceptive use of synthetic faces. Can synthetic identities be effectively used to fool human observers? In this paper, we introduce a study of the human perception of synthetic faces generated using different strategies including a state-of-the-art deep learning-based GAN model. This is the first rigorous study of the effectiveness of synthetic face generation techniques grounded in experimental techniques from psychology. We answer important questions such as how often do GAN-based and more traditional image processing-based techniques confuse human observers, and are there subtle cues within a synthetic face image that cause humans to perceive it as a fake without having to search for obvious clues? To answer these questions, we conducted a series of large-scale crowdsourced behavioral experiments with different sources of face imagery. Results show that humans are unable to distinguish synthetic faces from real faces under several different circumstances. This finding has serious implications for many different applications where face images are presented to human users.
Measuring Human Perception to Improve Handwritten Document Transcription
Apr 10, 2019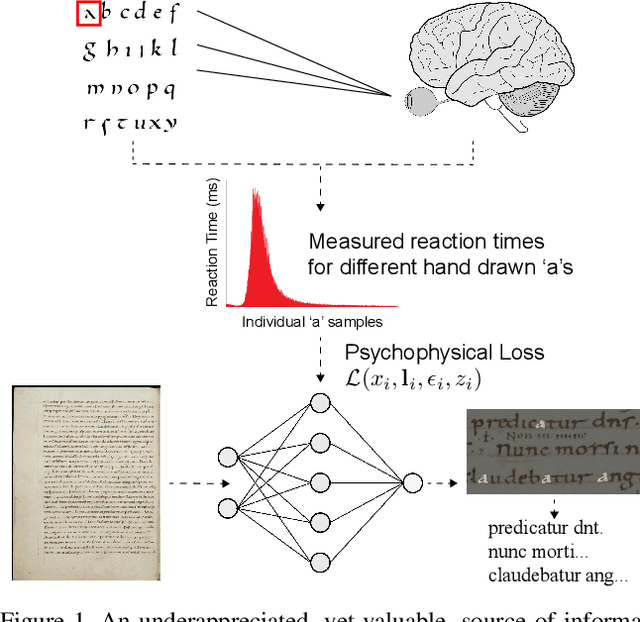

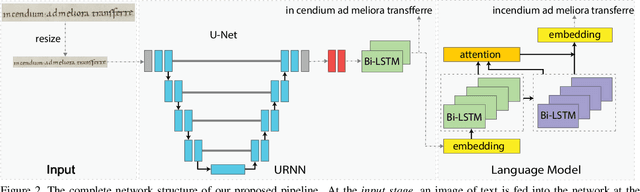

The subtleties of human perception, as measured by vision scientists through the use of psychophysics, are important clues to the internal workings of visual recognition. For instance, measured reaction time can indicate whether a visual stimulus is easy for a subject to recognize, or whether it is hard. In this paper, we consider how to incorporate psychophysical measurements of visual perception into the loss function of a deep neural network being trained for a recognition task, under the assumption that such information can enforce consistency with human behavior. As a case study to assess the viability of this approach, we look at the problem of handwritten document transcription. While good progress has been made towards automatically transcribing modern handwriting, significant challenges remain in transcribing historical documents. Here we work towards a comprehensive transcription solution for Medieval manuscripts that combines networks trained using our novel loss formulation with natural language processing elements. In a baseline assessment, reliable performance is demonstrated for the standard IAM and RIMES datasets. Further, we go on to show feasibility for our approach on a previously published dataset and a new dataset of digitized Latin manuscripts, originally produced by scribes in the Cloister of St. Gall around the middle of the 9th century.
An Anti-fraud System for Car Insurance Claim Based on Visual Evidence
Apr 30, 2018
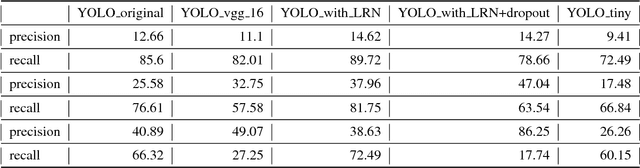

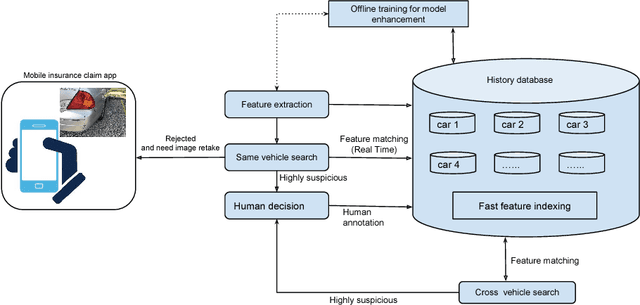
Automatically scene understanding using machine learning algorithms has been widely applied to different industries to reduce the cost of manual labor. Nowadays, insurance companies launch express vehicle insurance claim and settlement by allowing customers uploading pictures taken by mobile devices. This kind of insurance claim is treated as small claim and can be processed either manually or automatically in a quick fashion. However, due to the increasing amount of claims every day, system or people are likely to be fooled by repeated claims for identical case leading to big lost to insurance companies.Thus, an anti-fraud checking before processing the claim is necessary. We create the first data set of car damage images collected from internet and local parking lots. In addition, we proposed an approach to generate robust deep features by locating the damages accurately and efficiently in the images. The state-of-the-art real-time object detector YOLO \cite{redmon2016you}is modified to train and discover damage region as an important part of the pipeline. Both local and global deep features are extracted using VGG model\cite{Simonyan14c}, which are fused later for more robust system performance. Experiments show our approach is effective in preventing fraud claims as well as meet the requirement to speed up the insurance claim prepossessing.