 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Differentiable Adaptive Kalman Filtering via Optimal Transport
Aug 09, 2025Learning-based filtering has demonstrated strong performance in non-linear dynamical systems, particularly when the statistics of noise are unknown. However, in real-world deployments, environmental factors, such as changing wind conditions or electromagnetic interference, can induce unobserved noise-statistics drift, leading to substantial degradation of learning-based methods. To address this challenge, we propose OTAKNet, the first online solution to noise-statistics drift within learning-based adaptive Kalman filtering. Unlike existing learning-based methods that perform offline fine-tuning using batch pointwise matching over entire trajectories, OTAKNet establishes a connection between the state estimate and the drift via one-step predictive measurement likelihood, and addresses it using optimal transport. This leverages OT's geometry - aware cost and stable gradients to enable fully online adaptation without ground truth labels or retraining. We compare OTAKNet against classical model-based adaptive Kalman filtering and offline learning-based filtering. The performance is demonstrated on both synthetic and real-world NCLT datasets, particularly under limited training data.
From Long Videos to Engaging Clips: A Human-Inspired Video Editing Framework with Multimodal Narrative Understanding
Jul 03, 2025The rapid growth of online video content, especially on short video platforms, has created a growing demand for efficient video editing techniques that can condense long-form videos into concise and engaging clips. Existing automatic editing methods predominantly rely on textual cues from ASR transcripts and end-to-end segment selection, often neglecting the rich visual context and leading to incoherent outputs. In this paper, we propose a human-inspired automatic video editing framework (HIVE) that leverages multimodal narrative understanding to address these limitations. Our approach incorporates character extraction, dialogue analysis, and narrative summarization through multimodal large language models, enabling a holistic understanding of the video content. To further enhance coherence, we apply scene-level segmentation and decompose the editing process into three subtasks: highlight detection, opening/ending selection, and pruning of irrelevant content. To facilitate research in this area, we introduce DramaAD, a novel benchmark dataset comprising over 800 short drama episodes and 500 professionally edited advertisement clips. Experimental results demonstrate that our framework consistently outperforms existing baselines across both general and advertisement-oriented editing tasks, significantly narrowing the quality gap between automatic and human-edited videos.
Shapley-Coop: Credit Assignment for Emergent Cooperation in Self-Interested LLM Agents
Jun 09, 2025
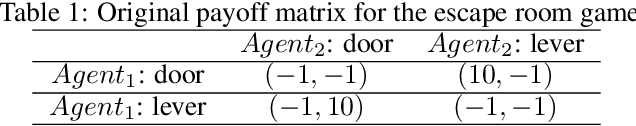

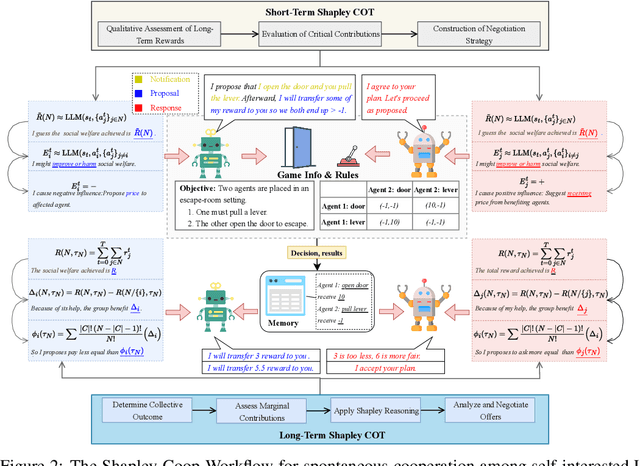
Large Language Models (LLMs) show strong collaborative performance in multi-agent systems with predefined roles and workflows. However, in open-ended environments lacking coordination rules, agents tend to act in self-interested ways. The central challenge in achieving coordination lies in credit assignment -- fairly evaluating each agent's contribution and designing pricing mechanisms that align their heterogeneous goals. This problem is critical as LLMs increasingly participate in complex human-AI collaborations, where fair compensation and accountability rely on effective pricing mechanisms. Inspired by how human societies address similar coordination challenges (e.g., through temporary collaborations such as employment or subcontracting), we propose a cooperative workflow, Shapley-Coop. Shapley-Coop integrates Shapley Chain-of-Thought -- leveraging marginal contributions as a principled basis for pricing -- with structured negotiation protocols for effective price matching, enabling LLM agents to coordinate through rational task-time pricing and post-task reward redistribution. This approach aligns agent incentives, fosters cooperation, and maintains autonomy. We evaluate Shapley-Coop across two multi-agent games and a software engineering simulation, demonstrating that it consistently enhances LLM agent collaboration and facilitates equitable credit assignment. These results highlight the effectiveness of Shapley-Coop's pricing mechanisms in accurately reflecting individual contributions during task execution.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
TextAtari: 100K Frames Game Playing with Language Agents
Jun 04, 2025We present TextAtari, a benchmark for evaluating language agents on very long-horizon decision-making tasks spanning up to 100,000 steps. By translating the visual state representations of classic Atari games into rich textual descriptions, TextAtari creates a challenging test bed that bridges sequential decision-making with natural language processing. The benchmark includes nearly 100 distinct tasks with varying complexity, action spaces, and planning horizons, all rendered as text through an unsupervised representation learning framework (AtariARI). We evaluate three open-source large language models (Qwen2.5-7B, Gemma-7B, and Llama3.1-8B) across three agent frameworks (zero-shot, few-shot chain-of-thought, and reflection reasoning) to assess how different forms of prior knowledge affect performance on these long-horizon challenges. Four scenarios-Basic, Obscured, Manual Augmentation, and Reference-based-investigate the impact of semantic understanding, instruction comprehension, and expert demonstrations on agent decision-making. Our results reveal significant performance gaps between language agents and human players in extensive planning tasks, highlighting challenges in sequential reasoning, state tracking, and strategic planning across tens of thousands of steps. TextAtari provides standardized evaluation protocols, baseline implementations, and a framework for advancing research at the intersection of language models and planning.
Where Paths Collide: A Comprehensive Survey of Classic and Learning-Based Multi-Agent Pathfinding
May 25, 2025Multi-Agent Path Finding (MAPF) is a fundamental problem in artificial intelligence and robotics, requiring the computation of collision-free paths for multiple agents navigating from their start locations to designated goals. As autonomous systems become increasingly prevalent in warehouses, urban transportation, and other complex environments, MAPF has evolved from a theoretical challenge to a critical enabler of real-world multi-robot coordination. This comprehensive survey bridges the long-standing divide between classical algorithmic approaches and emerging learning-based methods in MAPF research. We present a unified framework that encompasses search-based methods (including Conflict-Based Search, Priority-Based Search, and Large Neighborhood Search), compilation-based approaches (SAT, SMT, CSP, ASP, and MIP formulations), and data-driven techniques (reinforcement learning, supervised learning, and hybrid strategies). Through systematic analysis of experimental practices across 200+ papers, we uncover significant disparities in evaluation methodologies, with classical methods typically tested on larger-scale instances (up to 200 by 200 grids with 1000+ agents) compared to learning-based approaches (predominantly 10-100 agents). We provide a comprehensive taxonomy of evaluation metrics, environment types, and baseline selections, highlighting the need for standardized benchmarking protocols. Finally, we outline promising future directions including mixed-motive MAPF with game-theoretic considerations, language-grounded planning with large language models, and neural solver architectures that combine the rigor of classical methods with the flexibility of deep learning. This survey serves as both a comprehensive reference for researchers and a practical guide for deploying MAPF solutions in increasingly complex real-world applications.
Optimization Problem Solving Can Transition to Evolutionary Agentic Workflows
May 07, 2025This position paper argues that optimization problem solving can transition from expert-dependent to evolutionary agentic workflows. Traditional optimization practices rely on human specialists for problem formulation, algorithm selection, and hyperparameter tuning, creating bottlenecks that impede industrial adoption of cutting-edge methods. We contend that an evolutionary agentic workflow, powered by foundation models and evolutionary search, can autonomously navigate the optimization space, comprising problem, formulation, algorithm, and hyperparameter spaces. Through case studies in cloud resource scheduling and ADMM parameter adaptation, we demonstrate how this approach can bridge the gap between academic innovation and industrial implementation. Our position challenges the status quo of human-centric optimization workflows and advocates for a more scalable, adaptive approach to solving real-world optimization problems.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Generative Multi-Agent Collaboration in Embodied AI: A Systematic Review
Feb 17, 2025Embodied multi-agent systems (EMAS) have attracted growing attention for their potential to address complex, real-world challenges in areas such as logistics and robotics. Recent advances in foundation models pave the way for generative agents capable of richer communication and adaptive problem-solving. This survey provides a systematic examination of how EMAS can benefit from these generative capabilities. We propose a taxonomy that categorizes EMAS by system architectures and embodiment modalities, emphasizing how collaboration spans both physical and virtual contexts. Central building blocks, perception, planning, communication, and feedback, are then analyzed to illustrate how generative techniques bolster system robustness and flexibility. Through concrete examples, we demonstrate the transformative effects of integrating foundation models into embodied, multi-agent frameworks. Finally, we discuss challenges and future directions, underlining the significant promise of EMAS to reshape the landscape of AI-driven collaboration.