 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGCA-Net: Multi-Graph Contextual Attention Network for Two-View Correspondence Learning
Dec 29, 2025Two-view correspondence learning is a key task in computer vision, which aims to establish reliable matching relationships for applications such as camera pose estimation and 3D reconstruction. However, existing methods have limitations in local geometric modeling and cross-stage information optimization, which make it difficult to accurately capture the geometric constraints of matched pairs and thus reduce the robustness of the model. To address these challenges, we propose a Multi-Graph Contextual Attention Network (MGCA-Net), which consists of a Contextual Geometric Attention (CGA) module and a Cross-Stage Multi-Graph Consensus (CSMGC) module. Specifically, CGA dynamically integrates spatial position and feature information via an adaptive attention mechanism and enhances the capability to capture both local and global geometric relationships. Meanwhile, CSMGC establishes geometric consensus via a cross-stage sparse graph network, ensuring the consistency of geometric information across different stages. Experimental results on two representative YFCC100M and SUN3D datasets show that MGCA-Net significantly outperforms existing SOTA methods in the outlier rejection and camera pose estimation tasks. Source code is available at http://www.linshuyuan.com.
Shapley-Coop: Credit Assignment for Emergent Cooperation in Self-Interested LLM Agents
Jun 09, 2025

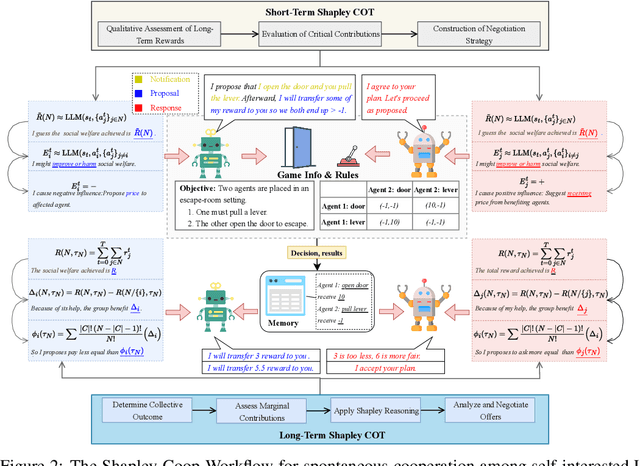
Large Language Models (LLMs) show strong collaborative performance in multi-agent systems with predefined roles and workflows. However, in open-ended environments lacking coordination rules, agents tend to act in self-interested ways. The central challenge in achieving coordination lies in credit assignment -- fairly evaluating each agent's contribution and designing pricing mechanisms that align their heterogeneous goals. This problem is critical as LLMs increasingly participate in complex human-AI collaborations, where fair compensation and accountability rely on effective pricing mechanisms. Inspired by how human societies address similar coordination challenges (e.g., through temporary collaborations such as employment or subcontracting), we propose a cooperative workflow, Shapley-Coop. Shapley-Coop integrates Shapley Chain-of-Thought -- leveraging marginal contributions as a principled basis for pricing -- with structured negotiation protocols for effective price matching, enabling LLM agents to coordinate through rational task-time pricing and post-task reward redistribution. This approach aligns agent incentives, fosters cooperation, and maintains autonomy. We evaluate Shapley-Coop across two multi-agent games and a software engineering simulation, demonstrating that it consistently enhances LLM agent collaboration and facilitates equitable credit assignment. These results highlight the effectiveness of Shapley-Coop's pricing mechanisms in accurately reflecting individual contributions during task execution.
A2Seek: Towards Reasoning-Centric Benchmark for Aerial Anomaly Understanding
May 28, 2025While unmanned aerial vehicles (UAVs) offer wide-area, high-altitude coverage for anomaly detection, they face challenges such as dynamic viewpoints, scale variations, and complex scenes. Existing datasets and methods, mainly designed for fixed ground-level views, struggle to adapt to these conditions, leading to significant performance drops in drone-view scenarios. To bridge this gap, we introduce A2Seek (Aerial Anomaly Seek), a large-scale, reasoning-centric benchmark dataset for aerial anomaly understanding. This dataset covers various scenarios and environmental conditions, providing high-resolution real-world aerial videos with detailed annotations, including anomaly categories, frame-level timestamps, region-level bounding boxes, and natural language explanations for causal reasoning. Building on this dataset, we propose A2Seek-R1, a novel reasoning framework that generalizes R1-style strategies to aerial anomaly understanding, enabling a deeper understanding of "Where" anomalies occur and "Why" they happen in aerial frames. To this end, A2Seek-R1 first employs a graph-of-thought (GoT)-guided supervised fine-tuning approach to activate the model's latent reasoning capabilities on A2Seek. Then, we introduce Aerial Group Relative Policy Optimization (A-GRPO) to design rule-based reward functions tailored to aerial scenarios. Furthermore, we propose a novel "seeking" mechanism that simulates UAV flight behavior by directing the model's attention to informative regions. Extensive experiments demonstrate that A2Seek-R1 achieves up to a 22.04% improvement in AP for prediction accuracy and a 13.9% gain in mIoU for anomaly localization, exhibiting strong generalization across complex environments and out-of-distribution scenarios. Our dataset and code will be released at https://hayneyday.github.io/A2Seek/.
EHGCN: Hierarchical Euclidean-Hyperbolic Fusion via Motion-Aware GCN for Hybrid Event Stream Perception
Apr 23, 2025Event cameras, with microsecond temporal resolution and high dynamic range (HDR) characteristics, emit high-speed event stream for perception tasks. Despite the recent advancement in GNN-based perception methods, they are prone to use straightforward pairwise connectivity mechanisms in the pure Euclidean space where they struggle to capture long-range dependencies and fail to effectively characterize the inherent hierarchical structures of non-uniformly distributed event stream. To this end, in this paper we propose a novel approach named EHGCN, which is a pioneer to perceive event stream in both Euclidean and hyperbolic spaces for event vision. In EHGCN, we introduce an adaptive sampling strategy to dynamically regulate sampling rates, retaining discriminative events while attenuating chaotic noise. Then we present a Markov Vector Field (MVF)-driven motion-aware hyperedge generation method based on motion state transition probabilities, thereby eliminating cross-target spurious associations and providing critically topological priors while capturing long-range dependencies between events. Finally, we propose a Euclidean-Hyperbolic GCN to fuse the information locally aggregated and globally hierarchically modeled in Euclidean and hyperbolic spaces, respectively, to achieve hybrid event perception. Experimental results on event perception tasks such as object detection and recognition validate the effectiveness of our approach.
GraphThought: Graph Combinatorial Optimization with Thought Generation
Feb 17, 2025Large language models (LLMs) have demonstrated remarkable capabilities across various domains, especially in text processing and generative tasks. Recent advancements in the reasoning capabilities of state-of-the-art LLMs, such as OpenAI-o1, have significantly broadened their applicability, particularly in complex problem-solving and logical inference. However, most existing LLMs struggle with notable limitations in handling graph combinatorial optimization (GCO) problems. To bridge this gap, we formally define the Optimal Thoughts Design (OTD) problem, including its state and action thought space. We then introduce a novel framework, GraphThought, designed to generate high-quality thought datasets for GCO problems. Leveraging these datasets, we fine-tune the Llama-3-8B-Instruct model to develop Llama-GT. Notably, despite its compact 8B-parameter architecture, Llama-GT matches the performance of state-of-the-art LLMs on the GraphArena benchmark. Experimental results show that our approach outperforms both proprietary and open-source models, even rivaling specialized models like o1-mini. This work sets a new state-of-the-art benchmark while challenging the prevailing notion that model scale is the primary driver of reasoning capability.
Beyond Euclidean: Dual-Space Representation Learning for Weakly Supervised Video Violence Detection
Sep 28, 2024



While numerous Video Violence Detection (VVD) methods have focused on representation learning in Euclidean space, they struggle to learn sufficiently discriminative features, leading to weaknesses in recognizing normal events that are visually similar to violent events (\emph{i.e.}, ambiguous violence). In contrast, hyperbolic representation learning, renowned for its ability to model hierarchical and complex relationships between events, has the potential to amplify the discrimination between visually similar events. Inspired by these, we develop a novel Dual-Space Representation Learning (DSRL) method for weakly supervised VVD to utilize the strength of both Euclidean and hyperbolic geometries, capturing the visual features of events while also exploring the intrinsic relations between events, thereby enhancing the discriminative capacity of the features. DSRL employs a novel information aggregation strategy to progressively learn event context in hyperbolic spaces, which selects aggregation nodes through layer-sensitive hyperbolic association degrees constrained by hyperbolic Dirichlet energy. Furthermore, DSRL attempts to break the cyber-balkanization of different spaces, utilizing cross-space attention to facilitate information interactions between Euclidean and hyperbolic space to capture better discriminative features for final violence detection. Comprehensive experiments demonstrate the effectiveness of our proposed DSRL.
Event Data Association via Robust Model Fitting for Event-based Object Tracking
Oct 25, 2021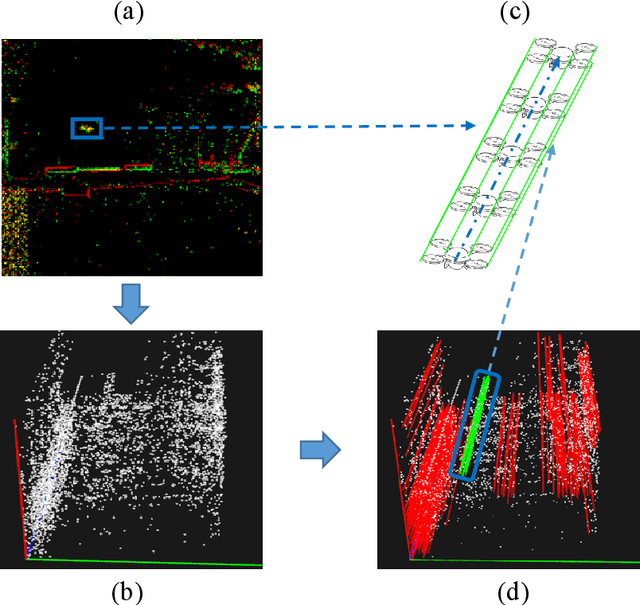
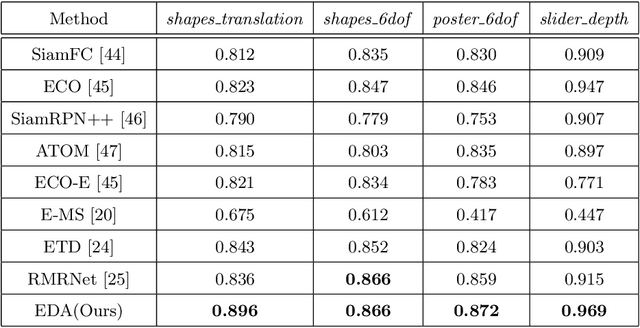
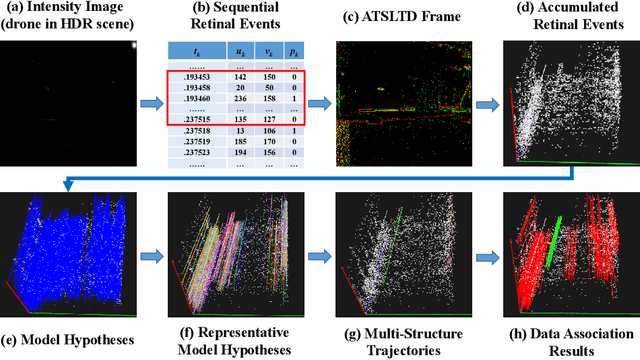
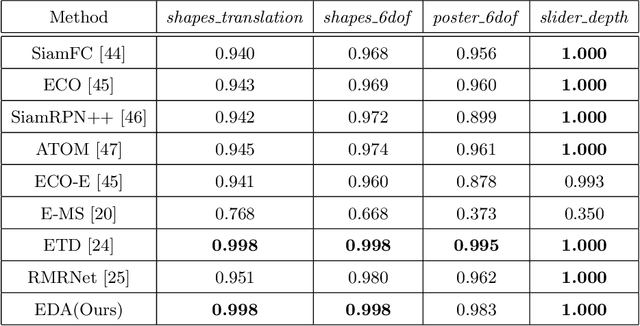
Event-based approaches, which are based on bio-inspired asynchronous event cameras, have achieved promising performance on various computer vision tasks. However, the study of the fundamental event data association problem is still in its infancy. In this paper, we propose a novel Event Data Association approach (called EDA) to explicitly address the data association problem. The proposed EDA seeks for event trajectories that best fit the event data, in order to perform unifying data association. In EDA, we first asynchronously gather the event data, based on its information entropy. Then, we introduce a deterministic model hypothesis generation strategy, which effectively generates model hypotheses from the gathered events, to represent the corresponding event trajectories. After that, we present a two-stage weighting algorithm, which robustly weighs and selects true models from the generated model hypotheses, through multi-structural geometric model fitting. Meanwhile, we also propose an adaptive model selection strategy to automatically determine the number of the true models. Finally, we use the selected true models to associate the event data, without being affected by sensor noise and irrelevant structures. We evaluate the performance of the proposed EDA on the object tracking task. The experimental results show the effectiveness of EDA under challenging scenarios, such as high speed, motion blur, and high dynamic range conditions.
Robust Visual Tracking via Statistical Positive Sample Generation and Gradient Aware Learning
Nov 09, 2020
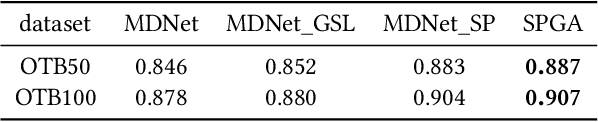
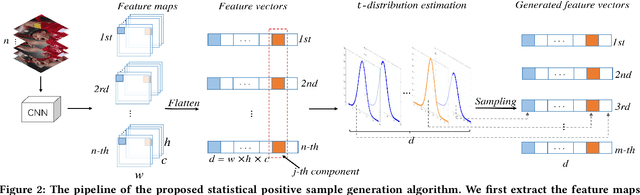
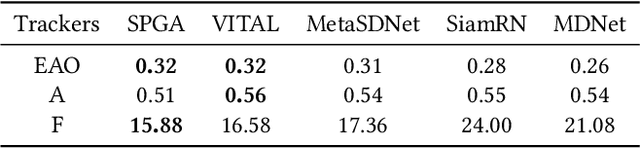
In recent years, Convolutional Neural Network (CNN) based trackers have achieved state-of-the-art performance on multiple benchmark datasets. Most of these trackers train a binary classifier to distinguish the target from its background. However, they suffer from two limitations. Firstly, these trackers cannot effectively handle significant appearance variations due to the limited number of positive samples. Secondly, there exists a significant imbalance of gradient contributions between easy and hard samples, where the easy samples usually dominate the computation of gradient. In this paper, we propose a robust tracking method via Statistical Positive sample generation and Gradient Aware learning (SPGA) to address the above two limitations. To enrich the diversity of positive samples, we present an effective and efficient statistical positive sample generation algorithm to generate positive samples in the feature space. Furthermore, to handle the issue of imbalance between easy and hard samples, we propose a gradient sensitive loss to harmonize the gradient contributions between easy and hard samples. Extensive experiments on three challenging benchmark datasets including OTB50, OTB100 and VOT2016 demonstrate that the proposed SPGA performs favorably against several state-of-the-art trackers.
* 6 pages
Dual Semantic Fusion Network for Video Object Detection
Sep 16, 2020
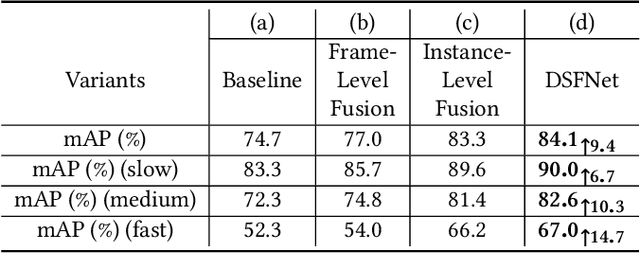
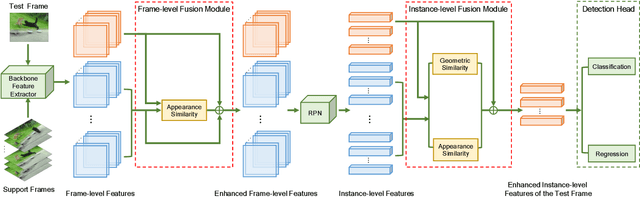
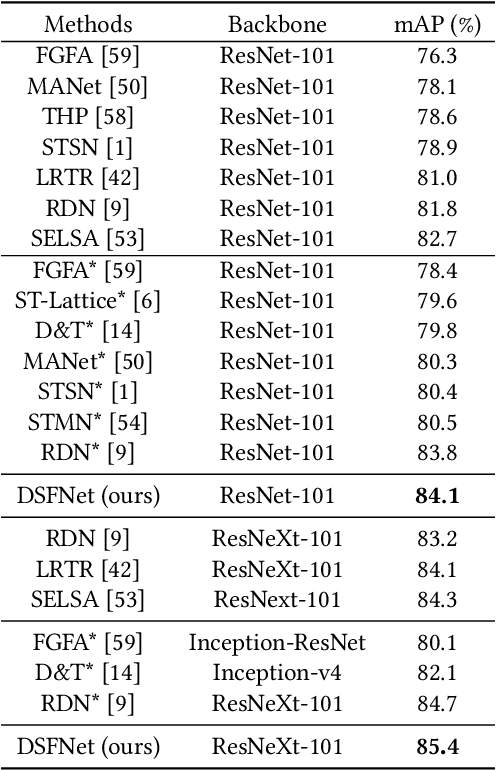
Video object detection is a tough task due to the deteriorated quality of video sequences captured under complex environments. Currently, this area is dominated by a series of feature enhancement based methods, which distill beneficial semantic information from multiple frames and generate enhanced features through fusing the distilled information. However, the distillation and fusion operations are usually performed at either frame level or instance level with external guidance using additional information, such as optical flow and feature memory. In this work, we propose a dual semantic fusion network (abbreviated as DSFNet) to fully exploit both frame-level and instance-level semantics in a unified fusion framework without external guidance. Moreover, we introduce a geometric similarity measure into the fusion process to alleviate the influence of information distortion caused by noise. As a result, the proposed DSFNet can generate more robust features through the multi-granularity fusion and avoid being affected by the instability of external guidance. To evaluate the proposed DSFNet, we conduct extensive experiments on the ImageNet VID dataset. Notably, the proposed dual semantic fusion network achieves, to the best of our knowledge, the best performance of 84.1\% mAP among the current state-of-the-art video object detectors with ResNet-101 and 85.4\% mAP with ResNeXt-101 without using any post-processing steps.
* 9 pages,6 figures
End-to-end Learning of Object Motion Estimation from Retinal Events for Event-based Object Tracking
Feb 14, 2020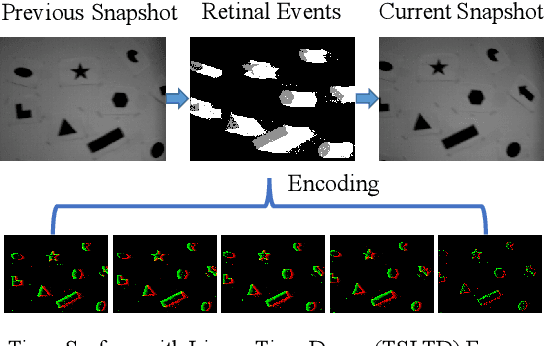

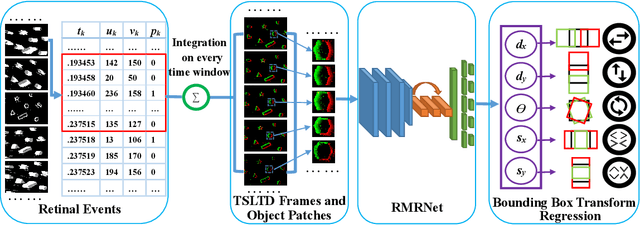
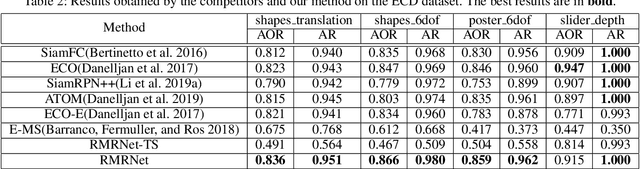
Event cameras, which are asynchronous bio-inspired vision sensors, have shown great potential in computer vision and artificial intelligence. However, the application of event cameras to object-level motion estimation or tracking is still in its infancy. The main idea behind this work is to propose a novel deep neural network to learn and regress a parametric object-level motion/transform model for event-based object tracking. To achieve this goal, we propose a synchronous Time-Surface with Linear Time Decay (TSLTD) representation, which effectively encodes the spatio-temporal information of asynchronous retinal events into TSLTD frames with clear motion patterns. We feed the sequence of TSLTD frames to a novel Retinal Motion Regression Network (RMRNet) to perform an end-to-end 5-DoF object motion regression. Our method is compared with state-of-the-art object tracking methods, that are based on conventional cameras or event cameras. The experimental results show the superiority of our method in handling various challenging environments such as fast motion and low illumination conditions.