 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCM-DiffRAG: Personalized Syndrome Differentiation Reasoning Method for Traditional Chinese Medicine based on Knowledge Graph and Chain of Thought
Feb 26, 2026Background: Retrieval augmented generation (RAG) technology can empower large language models (LLMs) to generate more accurate, professional, and timely responses without fine tuning. However, due to the complex reasoning processes and substantial individual differences involved in traditional Chinese medicine (TCM) clinical diagnosis and treatment, traditional RAG methods often exhibit poor performance in this domain. Objective: To address the limitations of conventional RAG approaches in TCM applications, this study aims to develop an improved RAG framework tailored to the characteristics of TCM reasoning. Methods: We developed TCM-DiffRAG, an innovative RAG framework that integrates knowledge graphs (KG) with chains of thought (CoT). TCM-DiffRAG was evaluated on three distinctive TCM test datasets. Results: The experimental results demonstrated that TCM-DiffRAG achieved significant performance improvements over native LLMs. For example, the qwen-plus model achieved scores of 0.927, 0.361, and 0.038, which were significantly enhanced to 0.952, 0.788, and 0.356 with TCM-DiffRAG. The improvements were even more pronounced for non-Chinese LLMs. Additionally, TCM-DiffRAG outperformed directly supervised fine-tuned (SFT) LLMs and other benchmark RAG methods. Conclusions: TCM-DiffRAG shows that integrating structured TCM knowledge graphs with Chain of Thought based reasoning substantially improves performance in individualized diagnostic tasks. The joint use of universal and personalized knowledge graphs enables effective alignment between general knowledge and clinical reasoning. These results highlight the potential of reasoning-aware RAG frameworks for advancing LLM applications in traditional Chinese medicine.
LLHA-Net: A Hierarchical Attention Network for Two-View Correspondence Learning
Dec 31, 2025Establishing the correct correspondence of feature points is a fundamental task in computer vision. However, the presence of numerous outliers among the feature points can significantly affect the matching results, reducing the accuracy and robustness of the process. Furthermore, a challenge arises when dealing with a large proportion of outliers: how to ensure the extraction of high-quality information while reducing errors caused by negative samples. To address these issues, in this paper, we propose a novel method called Layer-by-Layer Hierarchical Attention Network, which enhances the precision of feature point matching in computer vision by addressing the issue of outliers. Our method incorporates stage fusion, hierarchical extraction, and an attention mechanism to improve the network's representation capability by emphasizing the rich semantic information of feature points. Specifically, we introduce a layer-by-layer channel fusion module, which preserves the feature semantic information from each stage and achieves overall fusion, thereby enhancing the representation capability of the feature points. Additionally, we design a hierarchical attention module that adaptively captures and fuses global perception and structural semantic information using an attention mechanism. Finally, we propose two architectures to extract and integrate features, thereby improving the adaptability of our network. We conduct experiments on two public datasets, namely YFCC100M and SUN3D, and the results demonstrate that our proposed method outperforms several state-of-the-art techniques in both outlier removal and camera pose estimation. Source code is available at http://www.linshuyuan.com.
SC-Net: Robust Correspondence Learning via Spatial and Cross-Channel Context
Dec 29, 2025Recent research has focused on using convolutional neural networks (CNNs) as the backbones in two-view correspondence learning, demonstrating significant superiority over methods based on multilayer perceptrons. However, CNN backbones that are not tailored to specific tasks may fail to effectively aggregate global context and oversmooth dense motion fields in scenes with large disparity. To address these problems, we propose a novel network named SC-Net, which effectively integrates bilateral context from both spatial and channel perspectives. Specifically, we design an adaptive focused regularization module (AFR) to enhance the model's position-awareness and robustness against spurious motion samples, thereby facilitating the generation of a more accurate motion field. We then propose a bilateral field adjustment module (BFA) to refine the motion field by simultaneously modeling long-range relationships and facilitating interaction across spatial and channel dimensions. Finally, we recover the motion vectors from the refined field using a position-aware recovery module (PAR) that ensures consistency and precision. Extensive experiments demonstrate that SC-Net outperforms state-of-the-art methods in relative pose estimation and outlier removal tasks on YFCC100M and SUN3D datasets. Source code is available at http://www.linshuyuan.com.
MCI-Net: A Robust Multi-Domain Context Integration Network for Point Cloud Registration
Dec 29, 2025Robust and discriminative feature learning is critical for high-quality point cloud registration. However, existing deep learning-based methods typically rely on Euclidean neighborhood-based strategies for feature extraction, which struggle to effectively capture the implicit semantics and structural consistency in point clouds. To address these issues, we propose a multi-domain context integration network (MCI-Net) that improves feature representation and registration performance by aggregating contextual cues from diverse domains. Specifically, we propose a graph neighborhood aggregation module, which constructs a global graph to capture the overall structural relationships within point clouds. We then propose a progressive context interaction module to enhance feature discriminability by performing intra-domain feature decoupling and inter-domain context interaction. Finally, we design a dynamic inlier selection method that optimizes inlier weights using residual information from multiple iterations of pose estimation, thereby improving the accuracy and robustness of registration. Extensive experiments on indoor RGB-D and outdoor LiDAR datasets show that the proposed MCI-Net significantly outperforms existing state-of-the-art methods, achieving the highest registration recall of 96.4\% on 3DMatch. Source code is available at http://www.linshuyuan.com.
MGCA-Net: Multi-Graph Contextual Attention Network for Two-View Correspondence Learning
Dec 29, 2025Two-view correspondence learning is a key task in computer vision, which aims to establish reliable matching relationships for applications such as camera pose estimation and 3D reconstruction. However, existing methods have limitations in local geometric modeling and cross-stage information optimization, which make it difficult to accurately capture the geometric constraints of matched pairs and thus reduce the robustness of the model. To address these challenges, we propose a Multi-Graph Contextual Attention Network (MGCA-Net), which consists of a Contextual Geometric Attention (CGA) module and a Cross-Stage Multi-Graph Consensus (CSMGC) module. Specifically, CGA dynamically integrates spatial position and feature information via an adaptive attention mechanism and enhances the capability to capture both local and global geometric relationships. Meanwhile, CSMGC establishes geometric consensus via a cross-stage sparse graph network, ensuring the consistency of geometric information across different stages. Experimental results on two representative YFCC100M and SUN3D datasets show that MGCA-Net significantly outperforms existing SOTA methods in the outlier rejection and camera pose estimation tasks. Source code is available at http://www.linshuyuan.com.
Harnessing RLHF for Robust Unanswerability Recognition and Trustworthy Response Generation in LLMs
Jul 22, 2025Conversational Information Retrieval (CIR) systems, while offering intuitive access to information, face a significant challenge: reliably handling unanswerable questions to prevent the generation of misleading or hallucinated content. Traditional approaches often rely on external classifiers, which can introduce inconsistencies with the core generative Large Language Models (LLMs). This paper introduces Self-Aware LLM for Unanswerability (SALU), a novel approach that deeply integrates unanswerability detection directly within the LLM's generative process. SALU is trained using a multi-task learning framework for both standard Question Answering (QA) and explicit abstention generation for unanswerable queries. Crucially, it incorporates a confidence-score-guided reinforcement learning with human feedback (RLHF) phase, which explicitly penalizes hallucinated responses and rewards appropriate abstentions, fostering intrinsic self-awareness of knowledge boundaries. Through extensive experiments on our custom-built C-IR_Answerability dataset, SALU consistently outperforms strong baselines, including hybrid LLM-classifier systems, in overall accuracy for correctly answering or abstaining from questions. Human evaluation further confirms SALU's superior reliability, achieving high scores in factuality, appropriate abstention, and, most importantly, a dramatic reduction in hallucination, demonstrating its ability to robustly "know when to say 'I don't know'."
Improving TCM Question Answering through Tree-Organized Self-Reflective Retrieval with LLMs
Feb 13, 2025



Objectives: Large language models (LLMs) can harness medical knowledge for intelligent question answering (Q&A), promising support for auxiliary diagnosis and medical talent cultivation. However, there is a deficiency of highly efficient retrieval-augmented generation (RAG) frameworks within the domain of Traditional Chinese Medicine (TCM). Our purpose is to observe the effect of the Tree-Organized Self-Reflective Retrieval (TOSRR) framework on LLMs in TCM Q&A tasks. Materials and Methods: We introduce the novel approach of knowledge organization, constructing a tree structure knowledge base with hierarchy. At inference time, our self-reflection framework retrieves from this knowledge base, integrating information across chapters. Questions from the TCM Medical Licensing Examination (MLE) and the college Classics Course Exam (CCE) were randomly selected as benchmark datasets. Results: By coupling with GPT-4, the framework can improve the best performance on the TCM MLE benchmark by 19.85% in absolute accuracy, and improve recall accuracy from 27% to 38% on CCE datasets. In manual evaluation, the framework improves a total of 18.52 points across dimensions of safety, consistency, explainability, compliance, and coherence. Conclusion: The TOSRR framework can effectively improve LLM's capability in Q&A tasks of TCM.
Twin Trigger Generative Networks for Backdoor Attacks against Object Detection
Nov 23, 2024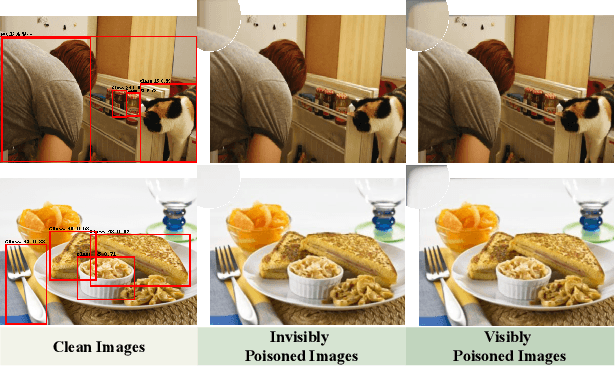
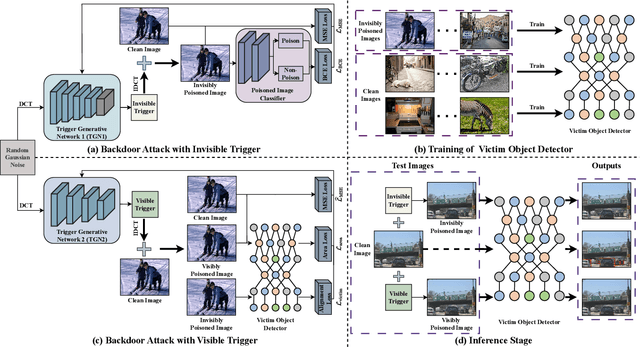
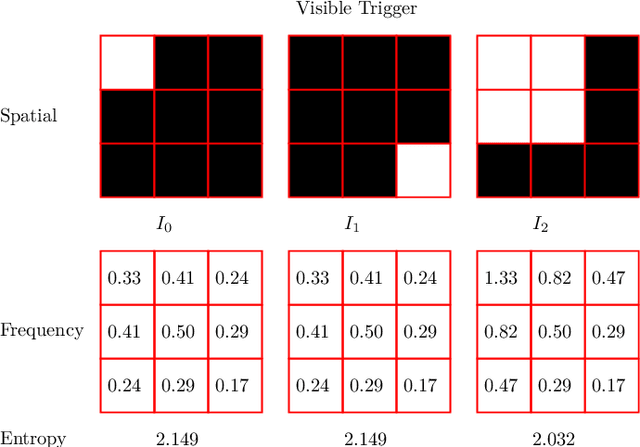
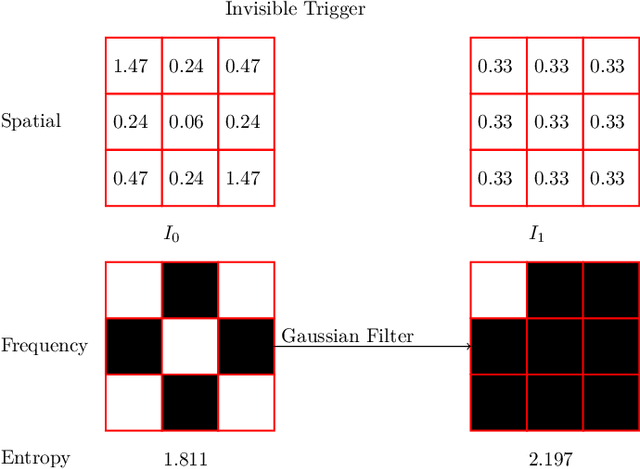
Object detectors, which are widely used in real-world applications, are vulnerable to backdoor attacks. This vulnerability arises because many users rely on datasets or pre-trained models provided by third parties due to constraints on data and resources. However, most research on backdoor attacks has focused on image classification, with limited investigation into object detection. Furthermore, the triggers for most existing backdoor attacks on object detection are manually generated, requiring prior knowledge and consistent patterns between the training and inference stages. This approach makes the attacks either easy to detect or difficult to adapt to various scenarios. To address these limitations, we propose novel twin trigger generative networks in the frequency domain to generate invisible triggers for implanting stealthy backdoors into models during training, and visible triggers for steady activation during inference, making the attack process difficult to trace. Specifically, for the invisible trigger generative network, we deploy a Gaussian smoothing layer and a high-frequency artifact classifier to enhance the stealthiness of backdoor implantation in object detectors. For the visible trigger generative network, we design a novel alignment loss to optimize the visible triggers so that they differ from the original patterns but still align with the malicious activation behavior of the invisible triggers. Extensive experimental results and analyses prove the possibility of using different triggers in the training stage and the inference stage, and demonstrate the attack effectiveness of our proposed visible trigger and invisible trigger generative networks, significantly reducing the mAP_0.5 of the object detectors by 70.0% and 84.5%, including YOLOv5 and YOLOv7 with different settings, respectively.
Event Data Association via Robust Model Fitting for Event-based Object Tracking
Oct 25, 2021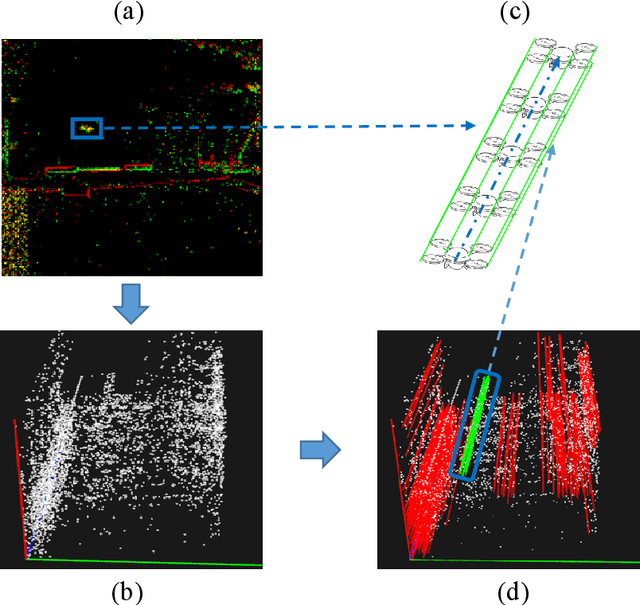
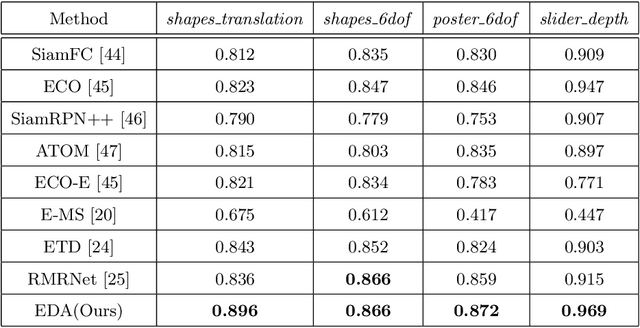
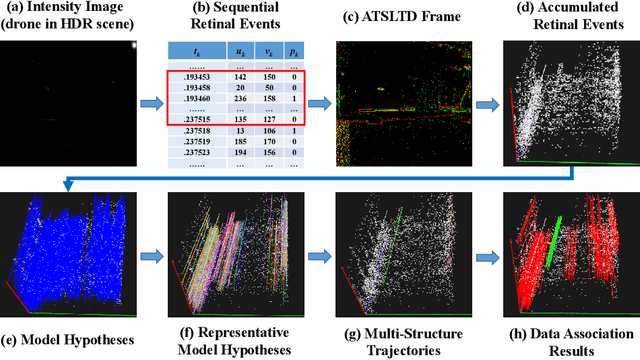
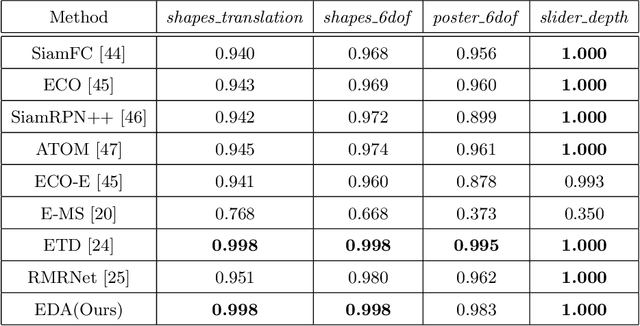
Event-based approaches, which are based on bio-inspired asynchronous event cameras, have achieved promising performance on various computer vision tasks. However, the study of the fundamental event data association problem is still in its infancy. In this paper, we propose a novel Event Data Association approach (called EDA) to explicitly address the data association problem. The proposed EDA seeks for event trajectories that best fit the event data, in order to perform unifying data association. In EDA, we first asynchronously gather the event data, based on its information entropy. Then, we introduce a deterministic model hypothesis generation strategy, which effectively generates model hypotheses from the gathered events, to represent the corresponding event trajectories. After that, we present a two-stage weighting algorithm, which robustly weighs and selects true models from the generated model hypotheses, through multi-structural geometric model fitting. Meanwhile, we also propose an adaptive model selection strategy to automatically determine the number of the true models. Finally, we use the selected true models to associate the event data, without being affected by sensor noise and irrelevant structures. We evaluate the performance of the proposed EDA on the object tracking task. The experimental results show the effectiveness of EDA under challenging scenarios, such as high speed, motion blur, and high dynamic range conditions.
Hierarchical Representation via Message Propagation for Robust Model Fitting
Dec 29, 2020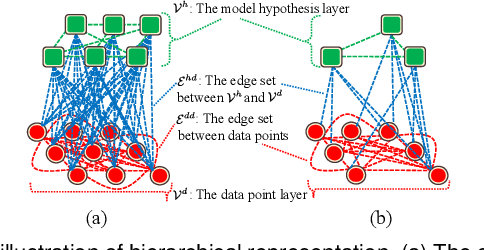


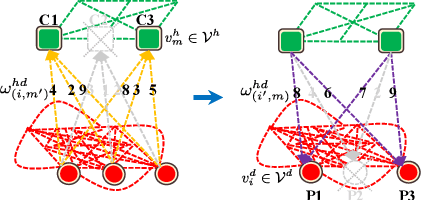
In this paper, we propose a novel hierarchical representation via message propagation (HRMP) method for robust model fitting, which simultaneously takes advantages of both the consensus analysis and the preference analysis to estimate the parameters of multiple model instances from data corrupted by outliers, for robust model fitting. Instead of analyzing the information of each data point or each model hypothesis independently, we formulate the consensus information and the preference information as a hierarchical representation to alleviate the sensitivity to gross outliers. Specifically, we firstly construct a hierarchical representation, which consists of a model hypothesis layer and a data point layer. The model hypothesis layer is used to remove insignificant model hypotheses and the data point layer is used to remove gross outliers. Then, based on the hierarchical representation, we propose an effective hierarchical message propagation (HMP) algorithm and an improved affinity propagation (IAP) algorithm to prune insignificant vertices and cluster the remaining data points, respectively. The proposed HRMP can not only accurately estimate the number and parameters of multiple model instances, but also handle multi-structural data contaminated with a large number of outliers. Experimental results on both synthetic data and real images show that the proposed HRMP significantly outperforms several state-of-the-art model fitting methods in terms of fitting accuracy and speed.