 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing RLHF for Robust Unanswerability Recognition and Trustworthy Response Generation in LLMs
Jul 22, 2025Conversational Information Retrieval (CIR) systems, while offering intuitive access to information, face a significant challenge: reliably handling unanswerable questions to prevent the generation of misleading or hallucinated content. Traditional approaches often rely on external classifiers, which can introduce inconsistencies with the core generative Large Language Models (LLMs). This paper introduces Self-Aware LLM for Unanswerability (SALU), a novel approach that deeply integrates unanswerability detection directly within the LLM's generative process. SALU is trained using a multi-task learning framework for both standard Question Answering (QA) and explicit abstention generation for unanswerable queries. Crucially, it incorporates a confidence-score-guided reinforcement learning with human feedback (RLHF) phase, which explicitly penalizes hallucinated responses and rewards appropriate abstentions, fostering intrinsic self-awareness of knowledge boundaries. Through extensive experiments on our custom-built C-IR_Answerability dataset, SALU consistently outperforms strong baselines, including hybrid LLM-classifier systems, in overall accuracy for correctly answering or abstaining from questions. Human evaluation further confirms SALU's superior reliability, achieving high scores in factuality, appropriate abstention, and, most importantly, a dramatic reduction in hallucination, demonstrating its ability to robustly "know when to say 'I don't know'."
DynMoLE: Boosting Mixture of LoRA Experts Fine-Tuning with a Hybrid Routing Mechanism
Apr 01, 2025Instruction-based fine-tuning of large language models (LLMs) has achieved remarkable success in various natural language processing (NLP) tasks. Parameter-efficient fine-tuning (PEFT) methods, such as Mixture of LoRA Experts (MoLE), combine the efficiency of Low-Rank Adaptation (LoRA) with the versatility of Mixture of Experts (MoE) models, demonstrating significant potential for handling multiple downstream tasks. However, the existing routing mechanisms for MoLE often involve a trade-off between computational efficiency and predictive accuracy, and they fail to fully address the diverse expert selection demands across different transformer layers. In this work, we propose DynMoLE, a hybrid routing strategy that dynamically adjusts expert selection based on the Tsallis entropy of the router's probability distribution. This approach mitigates router uncertainty, enhances stability, and promotes more equitable expert participation, leading to faster convergence and improved model performance. Additionally, we introduce an auxiliary loss based on Tsallis entropy to further guide the model toward convergence with reduced uncertainty, thereby improving training stability and performance. Our extensive experiments on commonsense reasoning benchmarks demonstrate that DynMoLE achieves substantial performance improvements, outperforming LoRA by 9.6% and surpassing the state-of-the-art MoLE method, MoLA, by 2.3%. We also conduct a comprehensive ablation study to evaluate the contributions of DynMoLE's key components.
Deep Causal Inference for Point-referenced Spatial Data with Continuous Treatments
Dec 05, 2024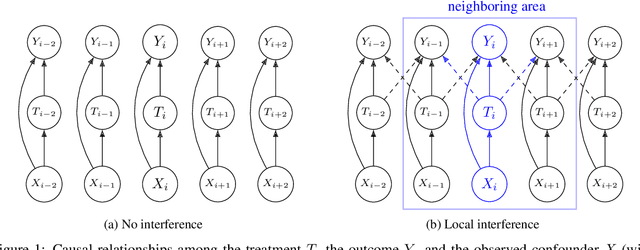


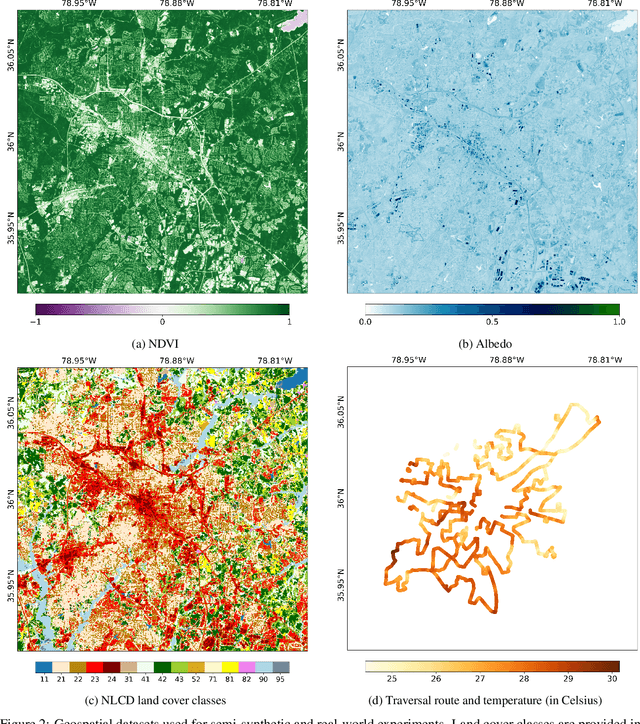
Causal reasoning is often challenging with spatial data, particularly when handling high-dimensional inputs. To address this, we propose a neural network (NN) based framework integrated with an approximate Gaussian process to manage spatial interference and unobserved confounding. Additionally, we adopt a generalized propensity-score-based approach to address partially observed outcomes when estimating causal effects with continuous treatments. We evaluate our framework using synthetic, semi-synthetic, and real-world data inferred from satellite imagery. Our results demonstrate that NN-based models significantly outperform linear spatial regression models in estimating causal effects. Furthermore, in real-world case studies, NN-based models offer more reasonable predictions of causal effects, facilitating decision-making in relevant applications.
Fast Asymmetric Factorization for Large Scale Multiple Kernel Clustering
May 26, 2024Kernel methods are extensively employed for nonlinear data clustering, yet their effectiveness heavily relies on selecting suitable kernels and associated parameters, posing challenges in advance determination. In response, Multiple Kernel Clustering (MKC) has emerged as a solution, allowing the fusion of information from multiple base kernels for clustering. However, both early fusion and late fusion methods for large-scale MKC encounter challenges in memory and time constraints, necessitating simultaneous optimization of both aspects. To address this issue, we propose Efficient Multiple Kernel Concept Factorization (EMKCF), which constructs a new sparse kernel matrix inspired by local regression to achieve memory efficiency. EMKCF learns consensus and individual representations by extending orthogonal concept factorization to handle multiple kernels for time efficiency. Experimental results demonstrate the efficiency and effectiveness of EMKCF on benchmark datasets compared to state-of-the-art methods. The proposed method offers a straightforward, scalable, and effective solution for large-scale MKC tasks.
MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA based Mixture of Experts
Apr 22, 2024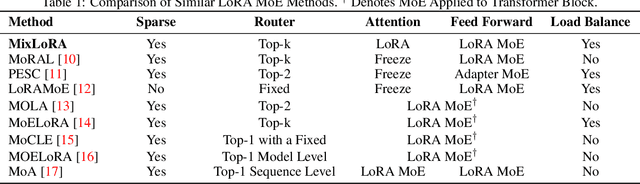
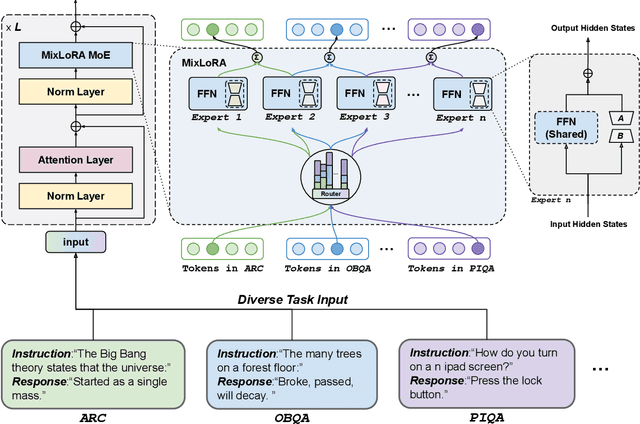


Large Language Models (LLMs) have showcased exceptional performance across a wide array of Natural Language Processing (NLP) tasks. Fine-tuning techniques are commonly utilized to tailor pre-trained models to specific applications. While methods like LoRA have effectively tackled GPU memory constraints during fine-tuning, their applicability is often restricted to limited performance, especially on multi-task. On the other hand, Mix-of-Expert (MoE) models, such as Mixtral 8x7B, demonstrate remarkable performance across multiple NLP tasks while maintaining a reduced parameter count. However, the resource requirements of these MoEs still challenging, particularly for consumer-grade GPUs only have limited VRAM. To address these challenge, we propose MixLoRA, an innovative approach aimed at constructing a resource-efficient sparse MoE model based on LoRA. MixLoRA inserts multiple LoRA-based experts within the feed-forward network block of a frozen pre-trained dense model through fine-tuning, employing a commonly used top-k router. Unlike other LoRA based MoE methods, MixLoRA enhances model performance by utilizing independently configurable attention-layer LoRA adapters, supporting the use of LoRA and its variants for the construction of experts, and applying auxiliary load balance loss to address the imbalance problem of the router. In experiments, MixLoRA achieves commendable performance across all evaluation metrics in both single-task and multi-task learning scenarios. Implemented within the m-LoRA framework, MixLoRA enables parallel fine-tuning of multiple mixture-of-experts models on a single 24GB consumer-grade GPU without quantization, thereby reducing GPU memory consumption by 41\% and latency during the training process by 17\%.
Augmenting Ground-Level PM2.5 Prediction via Kriging-Based Pseudo-Label Generation
Jan 16, 2024Fusing abundant satellite data with sparse ground measurements constitutes a major challenge in climate modeling. To address this, we propose a strategy to augment the training dataset by introducing unlabeled satellite images paired with pseudo-labels generated through a spatial interpolation technique known as ordinary kriging, thereby making full use of the available satellite data resources. We show that the proposed data augmentation strategy helps enhance the performance of the state-of-the-art convolutional neural network-random forest (CNN-RF) model by a reasonable amount, resulting in a noteworthy improvement in spatial correlation and a reduction in prediction error.
ASPEN: High-Throughput LoRA Fine-Tuning of Large Language Models with a Single GPU
Dec 05, 2023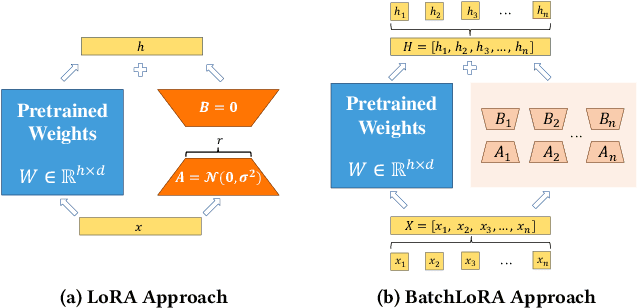
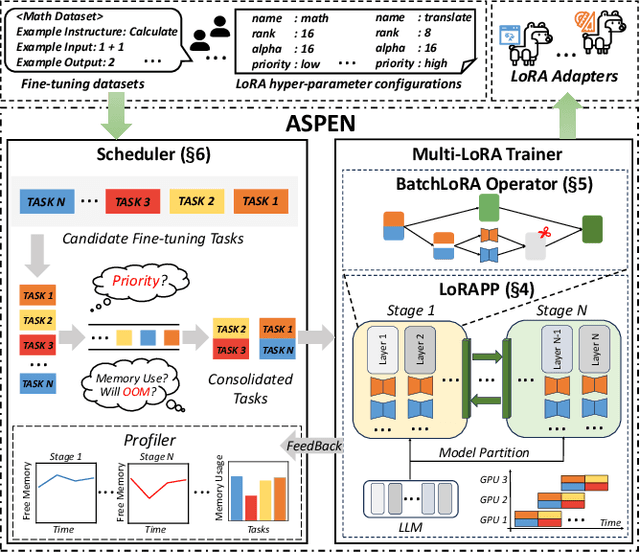
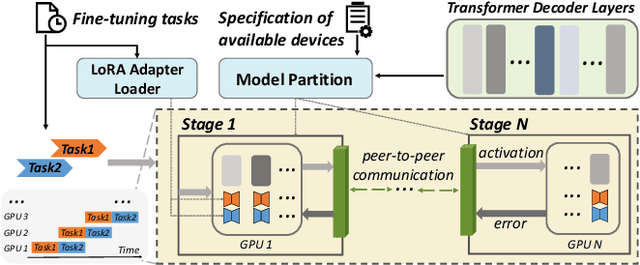
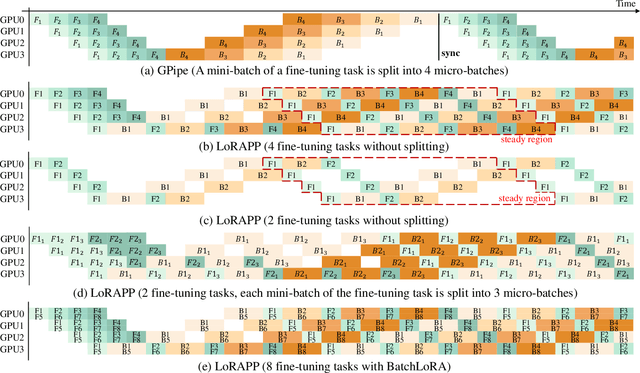
Transformer-based large language models (LLMs) have demonstrated outstanding performance across diverse domains, particularly when fine-turned for specific domains. Recent studies suggest that the resources required for fine-tuning LLMs can be economized through parameter-efficient methods such as Low-Rank Adaptation (LoRA). While LoRA effectively reduces computational burdens and resource demands, it currently supports only a single-job fine-tuning setup. In this paper, we present ASPEN, a high-throughput framework for fine-tuning LLMs. ASPEN efficiently trains multiple jobs on a single GPU using the LoRA method, leveraging shared pre-trained model and adaptive scheduling. ASPEN is compatible with transformer-based language models like LLaMA and ChatGLM, etc. Experiments show that ASPEN saves 53% of GPU memory when training multiple LLaMA-7B models on NVIDIA A100 80GB GPU and boosts training throughput by about 17% compared to existing methods when training with various pre-trained models on different GPUs. The adaptive scheduling algorithm reduces turnaround time by 24%, end-to-end training latency by 12%, prioritizing jobs and preventing out-of-memory issues.
Towards Highly Accurate and Stable Face Alignment for High-Resolution Videos
Nov 01, 2018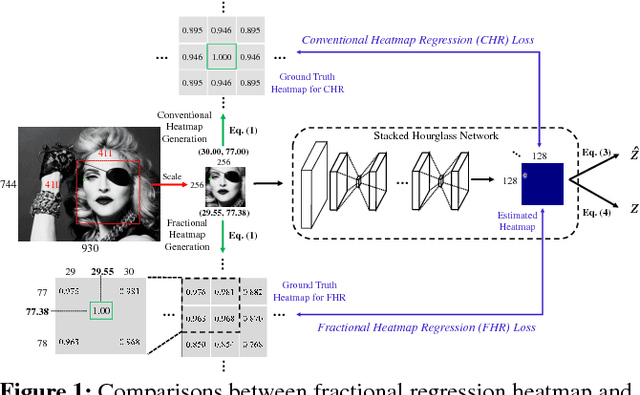

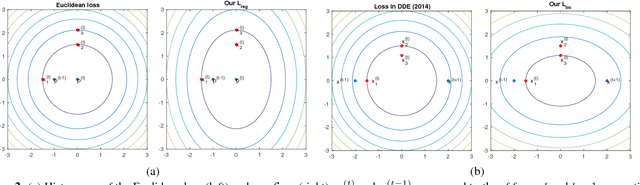
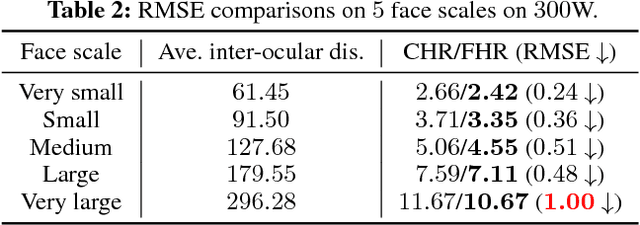
In recent years, heatmap regression based models have shown their effectiveness in face alignment and pose estimation. However, Conventional Heatmap Regression (CHR) is not accurate nor stable when dealing with high-resolution facial videos, since it finds the maximum activated location in heatmaps which are generated from rounding coordinates, and thus leads to quantization errors when scaling back to the original high-resolution space. In this paper, we propose a Fractional Heatmap Regression (FHR) for high-resolution video-based face alignment. The proposed FHR can accurately estimate the fractional part according to the 2D Gaussian function by sampling three points in heatmaps. To further stabilize the landmarks among continuous video frames while maintaining the precise at the same time, we propose a novel stabilization loss that contains two terms to address time delay and non-smooth issues, respectively. Experiments on 300W, 300-VW and Talking Face datasets clearly demonstrate that the proposed method is more accurate and stable than the state-of-the-art models.
Probabilistic Event Categorization
Oct 31, 1997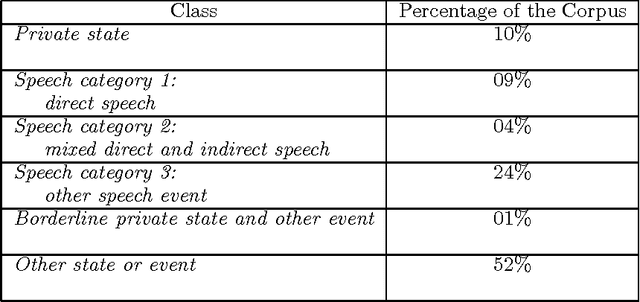
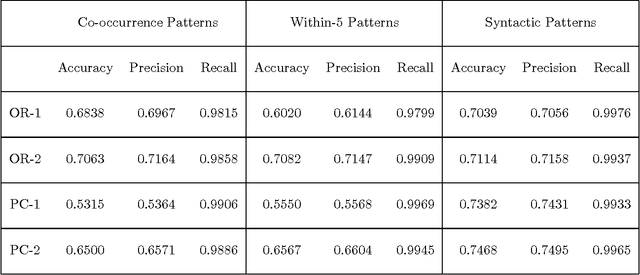
This paper describes the automation of a new text categorization task. The categories assigned in this task are more syntactically, semantically, and contextually complex than those typically assigned by fully automatic systems that process unseen test data. Our system for assigning these categories is a probabilistic classifier, developed with a recent method for formulating a probabilistic model from a predefined set of potential features. This paper focuses on feature selection. It presents a number of fully automatic features. It identifies and evaluates various approaches to organizing collocational properties into features, and presents the results of experiments covarying type of organization and type of property. We find that one organization is not best for all kinds of properties, so this is an experimental parameter worth investigating in NLP systems. In addition, the results suggest a way to take advantage of properties that are low frequency but strongly indicative of a class. The problems of recognizing and organizing the various kinds of contextual information required to perform a linguistically complex categorization task have rarely been systematically investigated in NLP.