 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
EDiT: A Local-SGD-Based Efficient Distributed Training Method for Large Language Models
Dec 10, 2024



Distributed training methods are crucial for large language models (LLMs). However, existing distributed training methods often suffer from communication bottlenecks, stragglers, and limited elasticity. Local SGD methods have been proposed to address these issues, but their effectiveness remains limited to small-scale training due to additional memory overhead and lack of concerns on efficiency and stability. To tackle these issues, we propose EDiT, an innovative Efficient Distributed Training method that combines a tailored Local SGD approach with model sharding techniques to enhance large-scale training efficiency. EDiT performs layer-wise parameter synchronization during forward pass, reducing communication and memory overhead and enabling the overlap of computation and communication. Besides, EDiT employs a pseudo gradient penalty strategy to suppress loss spikes, which ensures training stability and improve performance. Additionally, we introduce A-EDiT, a fully asynchronous variant of EDiT that accommodates heterogeneous clusters. Building on EDiT/A-EDiT, we conduct a series of experiments to validate large-scale asynchronous training for LLMs, accompanied by comprehensive analyses. Experimental results demonstrate the superior performance of EDiT/A-EDiT, establishing them as robust solutions for distributed LLM training in diverse computational ecosystems.
Couler: Unified Machine Learning Workflow Optimization in Cloud
Mar 12, 2024Machine Learning (ML) has become ubiquitous, fueling data-driven applications across various organizations. Contrary to the traditional perception of ML in research, ML workflows can be complex, resource-intensive, and time-consuming. Expanding an ML workflow to encompass a wider range of data infrastructure and data types may lead to larger workloads and increased deployment costs. Currently, numerous workflow engines are available (with over ten being widely recognized). This variety poses a challenge for end-users in terms of mastering different engine APIs. While efforts have primarily focused on optimizing ML Operations (MLOps) for a specific workflow engine, current methods largely overlook workflow optimization across different engines. In this work, we design and implement Couler, a system designed for unified ML workflow optimization in the cloud. Our main insight lies in the ability to generate an ML workflow using natural language (NL) descriptions. We integrate Large Language Models (LLMs) into workflow generation, and provide a unified programming interface for various workflow engines. This approach alleviates the need to understand various workflow engines' APIs. Moreover, Couler enhances workflow computation efficiency by introducing automated caching at multiple stages, enabling large workflow auto-parallelization and automatic hyperparameters tuning. These enhancements minimize redundant computational costs and improve fault tolerance during deep learning workflow training. Couler is extensively deployed in real-world production scenarios at Ant Group, handling approximately 22k workflows daily, and has successfully improved the CPU/Memory utilization by more than 15% and the workflow completion rate by around 17%.
ASPEN: High-Throughput LoRA Fine-Tuning of Large Language Models with a Single GPU
Dec 05, 2023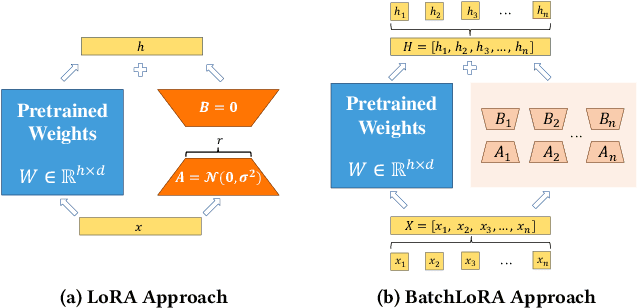
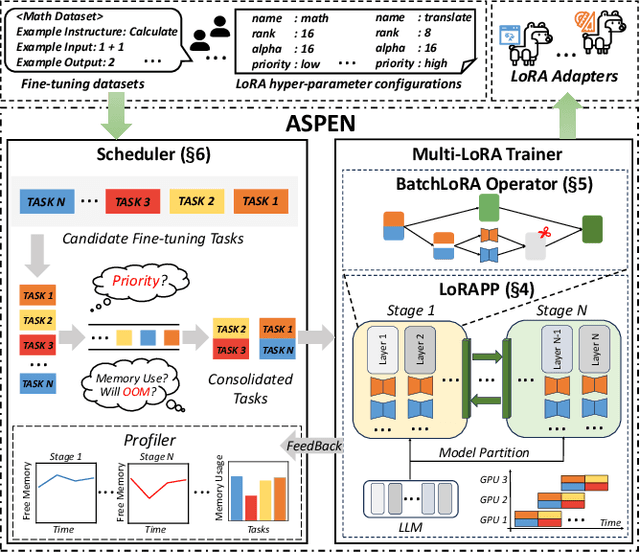
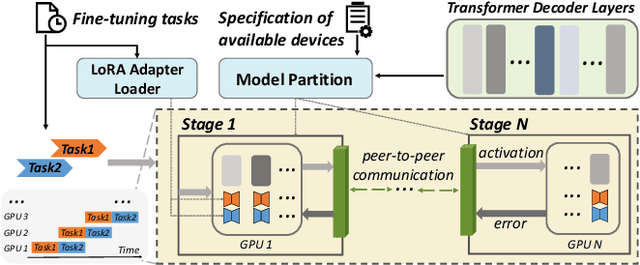
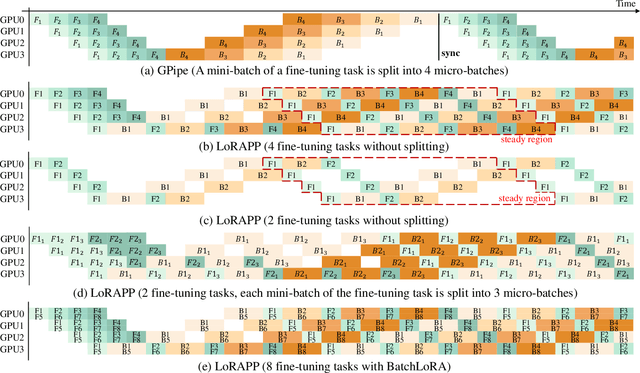
Transformer-based large language models (LLMs) have demonstrated outstanding performance across diverse domains, particularly when fine-turned for specific domains. Recent studies suggest that the resources required for fine-tuning LLMs can be economized through parameter-efficient methods such as Low-Rank Adaptation (LoRA). While LoRA effectively reduces computational burdens and resource demands, it currently supports only a single-job fine-tuning setup. In this paper, we present ASPEN, a high-throughput framework for fine-tuning LLMs. ASPEN efficiently trains multiple jobs on a single GPU using the LoRA method, leveraging shared pre-trained model and adaptive scheduling. ASPEN is compatible with transformer-based language models like LLaMA and ChatGLM, etc. Experiments show that ASPEN saves 53% of GPU memory when training multiple LLaMA-7B models on NVIDIA A100 80GB GPU and boosts training throughput by about 17% compared to existing methods when training with various pre-trained models on different GPUs. The adaptive scheduling algorithm reduces turnaround time by 24%, end-to-end training latency by 12%, prioritizing jobs and preventing out-of-memory issues.