 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualLeakBench: Auditing the Fragility of Large Vision-Language Models against PII Leakage and Social Engineering
Mar 11, 2026As Large Vision-Language Models (LVLMs) are increasingly deployed in agent-integrated workflows and other deployment-relevant settings, their robustness against semantic visual attacks remains under-evaluated -- alignment is typically tested on explicit harmful content rather than privacy-critical multimodal scenarios. We introduce VisualLeakBench, an evaluation suite to audit LVLMs against OCR Injection and Contextual PII Leakage using 1,000 synthetically generated adversarial images with 8 PII types, validated on 50 in-the-wild (IRL) real-world screenshots spanning diverse visual contexts. We evaluate four frontier systems (GPT-5.2, Claude~4, Gemini-3 Flash, Grok-4) with Wilson 95% confidence intervals. Claude~4 achieves the lowest OCR ASR (14.2%) but the highest PII ASR (74.4%), exhibiting a comply-then-warn pattern -- where verbatim data disclosure precedes any safety-oriented language. Grok-4 achieves the lowest PII ASR (20.4%). A defensive system prompt eliminates PII leakage for two models, reduces Claude~4's leakage from 74.4% to 2.2%, but has no effect on Gemini-3 Flash on synthetic data. Strikingly, IRL validation reveals Gemini-3 Flash does respond to mitigation on real-world images (50% to 0%), indicating that mitigation robustness is template-sensitive rather than uniformly absent. We release our dataset and code for reproducible robustness and safety evaluation of deployment-relevant vision-language systems.
Automated Robotic Needle Puncture for Percutaneous Dilatational Tracheostomy
Feb 26, 2026Percutaneous dilatational tracheostomy (PDT) is frequently performed on patients in intensive care units for prolonged mechanical ventilation. The needle puncture, as the most critical step of PDT, could lead to adverse consequences such as major bleeding and posterior tracheal wall perforation if performed inaccurately. Current practices of PDT puncture are all performed manually with no navigation assistance, which leads to large position and angular errors (5 mm and 30 degree). To improve the accuracy and reduce the difficulty of the PDT procedure, we propose a system that automates the needle insertion using a velocity-controlled robotic manipulator. Guided using pose data from two electromagnetic sensors, one at the needle tip and the other inside the trachea, the robotic system uses an adaptive constrained controller to adapt the uncertain kinematic parameters online and avoid collisions with the patient's body and tissues near the target. Simulations were performed to validate the controller's implementation, and then four hundred PDT punctures were performed on a mannequin to evaluate the position and angular accuracy. The absolute median puncture position error was 1.7 mm (IQR: 1.9 mm) and midline deviation was 4.13 degree (IQR: 4.55 degree), measured by the sensor inside the trachea. The small deviations from the nominal puncture in a simulated experimental setup and formal guarantees of collision-free insertions suggest the feasibility of the robotic PDT puncture.
SASep: Saliency-Aware Structured Separation of Geometry and Feature for Open Set Learning on Point Clouds
Jun 16, 2025Recent advancements in deep learning have greatly enhanced 3D object recognition, but most models are limited to closed-set scenarios, unable to handle unknown samples in real-world applications. Open-set recognition (OSR) addresses this limitation by enabling models to both classify known classes and identify novel classes. However, current OSR methods rely on global features to differentiate known and unknown classes, treating the entire object uniformly and overlooking the varying semantic importance of its different parts. To address this gap, we propose Salience-Aware Structured Separation (SASep), which includes (i) a tunable semantic decomposition (TSD) module to semantically decompose objects into important and unimportant parts, (ii) a geometric synthesis strategy (GSS) to generate pseudo-unknown objects by combining these unimportant parts, and (iii) a synth-aided margin separation (SMS) module to enhance feature-level separation by expanding the feature distributions between classes. Together, these components improve both geometric and feature representations, enhancing the model's ability to effectively distinguish known and unknown classes. Experimental results show that SASep achieves superior performance in 3D OSR, outperforming existing state-of-the-art methods.
A No-Reference Medical Image Quality Assessment Method Based on Automated Distortion Recognition Technology: Application to Preprocessing in MRI-guided Radiotherapy
Dec 10, 2024



Objective:To develop a no-reference image quality assessment method using automated distortion recognition to boost MRI-guided radiotherapy precision.Methods:We analyzed 106,000 MR images from 10 patients with liver metastasis,captured with the Elekta Unity MR-LINAC.Our No-Reference Quality Assessment Model includes:1)image preprocessing to enhance visibility of key diagnostic features;2)feature extraction and directional analysis using MSCN coefficients across four directions to capture textural attributes and gradients,vital for identifying image features and potential distortions;3)integrative Quality Index(QI)calculation,which integrates features via AGGD parameter estimation and K-means clustering.The QI,based on a weighted MAD computation of directional scores,provides a comprehensive image quality measure,robust against outliers.LOO-CV assessed model generalizability and performance.Tumor tracking algorithm performance was compared with and without preprocessing to verify tracking accuracy enhancements.Results:Preprocessing significantly improved image quality,with the QI showing substantial positive changes and surpassing other metrics.After normalization,the QI's average value was 79.6 times higher than CNR,indicating improved image definition and contrast.It also showed higher sensitivity in detail recognition with average values 6.5 times and 1.7 times higher than Tenengrad gradient and entropy.The tumor tracking algorithm confirmed significant tracking accuracy improvements with preprocessed images,validating preprocessing effectiveness.Conclusions:This study introduces a novel no-reference image quality evaluation method based on automated distortion recognition,offering a new quality control tool for MRIgRT tumor tracking.It enhances clinical application accuracy and facilitates medical image quality assessment standardization, with significant clinical and research value.
Fancy123: One Image to High-Quality 3D Mesh Generation via Plug-and-Play Deformation
Nov 25, 2024



Generating 3D meshes from a single image is an important but ill-posed task. Existing methods mainly adopt 2D multiview diffusion models to generate intermediate multiview images, and use the Large Reconstruction Model (LRM) to create the final meshes. However, the multiview images exhibit local inconsistencies, and the meshes often lack fidelity to the input image or look blurry. We propose Fancy123, featuring two enhancement modules and an unprojection operation to address the above three issues, respectively. The appearance enhancement module deforms the 2D multiview images to realign misaligned pixels for better multiview consistency. The fidelity enhancement module deforms the 3D mesh to match the input image. The unprojection of the input image and deformed multiview images onto LRM's generated mesh ensures high clarity, discarding LRM's predicted blurry-looking mesh colors. Extensive qualitative and quantitative experiments verify Fancy123's SoTA performance with significant improvement. Also, the two enhancement modules are plug-and-play and work at inference time, allowing seamless integration into various existing single-image-to-3D methods.
A Novel Automatic Real-time Motion Tracking Method for Magnetic Resonance Imaging-guided Radiotherapy: Leveraging the Enhanced Tracking-Learning-Detection Framework with Automatic Segmentation
Nov 12, 2024



Objective: Ensuring the precision in motion tracking for MRI-guided Radiotherapy (MRIgRT) is crucial for the delivery of effective treatments. This study refined the motion tracking accuracy in MRIgRT through the innovation of an automatic real-time tracking method, leveraging an enhanced Tracking-Learning-Detection (ETLD) framework coupled with automatic segmentation. Methods: We developed a novel MRIgRT motion tracking method by integrating two primary methods: the ETLD framework and an improved Chan-Vese model (ICV), named ETLD+ICV. The TLD framework was upgraded to suit real-time cine MRI, including advanced image preprocessing, no-reference image quality assessment, an enhanced median-flow tracker, and a refined detector with dynamic search region adjustments. Additionally, ICV was combined for precise coverage of the target volume, which refined the segmented region frame by frame using tracking results, with key parameters optimized. Tested on 3.5D MRI scans from 10 patients with liver metastases, our method ensures precise tracking and accurate segmentation vital for MRIgRT. Results: An evaluation of 106,000 frames across 77 treatment fractions revealed sub-millimeter tracking errors of less than 0.8mm, with over 99% precision and 98% recall for all subjects, underscoring the robustness and efficacy of the ETLD. Moreover, the ETLD+ICV yielded a dice global score of more than 82% for all subjects, demonstrating the proposed method's extensibility and precise target volume coverage. Conclusions: This study successfully developed an automatic real-time motion tracking method for MRIgRT that markedly surpasses current methods. The novel method not only delivers exceptional precision in tracking and segmentation but also demonstrates enhanced adaptability to clinical demands, positioning it as an indispensable asset in the quest to augment the efficacy of radiotherapy treatments.
More Text, Less Point: Towards 3D Data-Efficient Point-Language Understanding
Aug 28, 2024
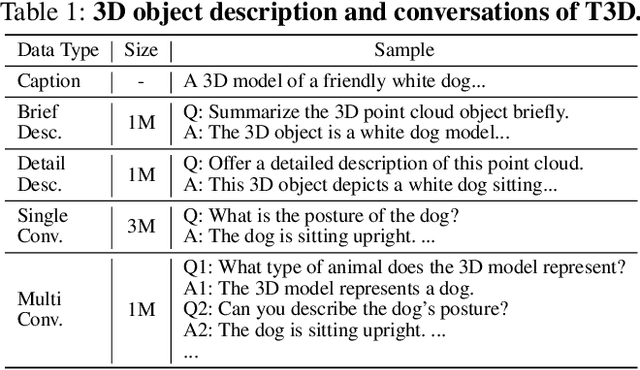
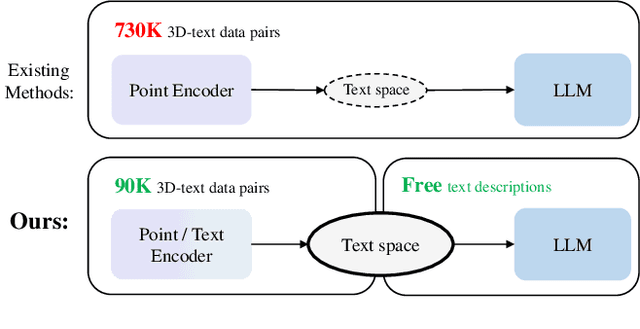
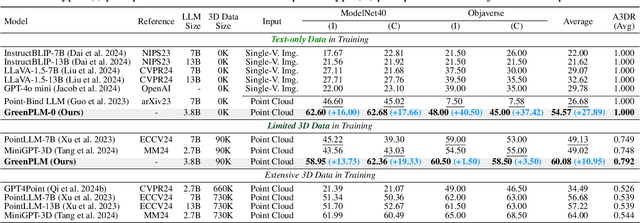
Enabling Large Language Models (LLMs) to comprehend the 3D physical world remains a significant challenge. Due to the lack of large-scale 3D-text pair datasets, the success of LLMs has yet to be replicated in 3D understanding. In this paper, we rethink this issue and propose a new task: 3D Data-Efficient Point-Language Understanding. The goal is to enable LLMs to achieve robust 3D object understanding with minimal 3D point cloud and text data pairs. To address this task, we introduce GreenPLM, which leverages more text data to compensate for the lack of 3D data. First, inspired by using CLIP to align images and text, we utilize a pre-trained point cloud-text encoder to map the 3D point cloud space to the text space. This mapping leaves us to seamlessly connect the text space with LLMs. Once the point-text-LLM connection is established, we further enhance text-LLM alignment by expanding the intermediate text space, thereby reducing the reliance on 3D point cloud data. Specifically, we generate 6M free-text descriptions of 3D objects, and design a three-stage training strategy to help LLMs better explore the intrinsic connections between different modalities. To achieve efficient modality alignment, we design a zero-parameter cross-attention module for token pooling. Extensive experimental results show that GreenPLM requires only 12% of the 3D training data used by existing state-of-the-art models to achieve superior 3D understanding. Remarkably, GreenPLM also achieves competitive performance using text-only data. The code and weights are available at: https://github.com/TangYuan96/GreenPLM.
PointDreamer: Zero-shot 3D Textured Mesh Reconstruction from Colored Point Cloud by 2D Inpainting
Jun 22, 2024Reconstructing textured meshes from colored point clouds is an important but challenging task in 3D graphics and vision. Most existing methods predict colors as implicit functions in 3D or UV space, suffering from blurry textures or the lack of generalization capability. Addressing this, we propose PointDreamer, a novel framework for textured mesh reconstruction from colored point cloud. It produces meshes with enhanced fidelity and clarity by 2D image inpainting, taking advantage of the mature techniques and massive data of 2D vision. Specifically, we first project the input point cloud into 2D space to generate sparse multi-view images, and then inpaint empty pixels utilizing a pre-trained 2D diffusion model. Next, we design a novel Non-Border-First strategy to unproject the colors of the inpainted dense images back to 3D space, thus obtaining the final textured mesh. In this way, our PointDreamer works in a zero-shot manner, requiring no extra training. Extensive qualitative and quantitative experiments on various synthetic and real-scanned datasets show the SoTA performance of PointDreamer, by significantly outperforming baseline methods with 30\% improvement in LPIPS score (from 0.118 to 0.068). Code at: https://github.com/YuQiao0303/PointDreamer.
MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors
May 02, 2024



Large 2D vision-language models (2D-LLMs) have gained significant attention by bridging Large Language Models (LLMs) with images using a simple projector. Inspired by their success, large 3D point cloud-language models (3D-LLMs) also integrate point clouds into LLMs. However, directly aligning point clouds with LLM requires expensive training costs, typically in hundreds of GPU-hours on A100, which hinders the development of 3D-LLMs. In this paper, we introduce MiniGPT-3D, an efficient and powerful 3D-LLM that achieves multiple SOTA results while training for only 27 hours on one RTX 3090. Specifically, we propose to align 3D point clouds with LLMs using 2D priors from 2D-LLMs, which can leverage the similarity between 2D and 3D visual information. We introduce a novel four-stage training strategy for modality alignment in a cascaded way, and a mixture of query experts module to adaptively aggregate features with high efficiency. Moreover, we utilize parameter-efficient fine-tuning methods LoRA and Norm fine-tuning, resulting in only 47.8M learnable parameters, which is up to 260x fewer than existing methods. Extensive experiments show that MiniGPT-3D achieves SOTA on 3D object classification and captioning tasks, with significantly cheaper training costs. Notably, MiniGPT-3D gains an 8.12 increase on GPT-4 evaluation score for the challenging object captioning task compared to ShapeLLM-13B, while the latter costs 160 total GPU-hours on 8 A800. We are the first to explore the efficient 3D-LLM, offering new insights to the community. Code and weights are available at https://github.com/TangYuan96/MiniGPT-3D.
Mamba3D: Enhancing Local Features for 3D Point Cloud Analysis via State Space Model
Apr 23, 2024



Existing Transformer-based models for point cloud analysis suffer from quadratic complexity, leading to compromised point cloud resolution and information loss. In contrast, the newly proposed Mamba model, based on state space models (SSM), outperforms Transformer in multiple areas with only linear complexity. However, the straightforward adoption of Mamba does not achieve satisfactory performance on point cloud tasks. In this work, we present Mamba3D, a state space model tailored for point cloud learning to enhance local feature extraction, achieving superior performance, high efficiency, and scalability potential. Specifically, we propose a simple yet effective Local Norm Pooling (LNP) block to extract local geometric features. Additionally, to obtain better global features, we introduce a bidirectional SSM (bi-SSM) with both a token forward SSM and a novel backward SSM that operates on the feature channel. Extensive experimental results show that Mamba3D surpasses Transformer-based counterparts and concurrent works in multiple tasks, with or without pre-training. Notably, Mamba3D achieves multiple SoTA, including an overall accuracy of 92.6% (train from scratch) on the ScanObjectNN and 95.1% (with single-modal pre-training) on the ModelNet40 classification task, with only linear complexity.