 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient RWKV-based Representation Learning for 3D Point Clouds
Jun 09, 2026The recent receptance weighted key value (RWKV) model combines RNN-style recurrence, offering a linear-complexity alternative to Transformers' quadratic self-attention for modeling global dependencies. However, when directly applied to point clouds, RWKV, originally developed for sequential text, struggles to capture local geometric structures and model spatial dependencies effectively. To address this, we propose the \textbf{P-RWKV} block, which bridges the gap between sequence modeling and irregular 3D geometry while preserving the efficiency advantages of RWKV. It consists of a Local Perception Expansion (LPE) component to expand contextual perception along the spatio-temporal sequence and a Spatial Context Enhancement (SCE) component to strengthen spatial awareness. To validate the effectiveness of P-RWKV for point cloud understanding, we construct PointER, a single-modality self-supervised representation learning framework whose encoder is composed of stacked P-RWKV blocks. Furthermore, we extend P-RWKV to a cross-modality setting and integrate the proposed core sub-modules into multiple architectures, demonstrating strong plug-and-play flexibility and architectural generality. Extensive experiments show that the P-RWKV block and its key sub-modules achieve competitive performance across various tasks with lower computational cost and inference latency. Code will be released upon acceptance.
Towards Pixel-Wise Anomaly Location for High-Resolution PCBA via Self-Supervised Image Reconstruction
Dec 22, 2025Automated defect inspection of assembled Printed Circuit Board Assemblies (PCBA) is quite challenging due to the insufficient labeled data, micro-defects with just a few pixels in visually-complex and high-resolution images. To address these challenges, we present HiSIR-Net, a High resolution, Self-supervised Reconstruction framework for pixel-wise PCBA localization. Our design combines two lightweight modules that make this practical on real 4K-resolution boards: (i) a Selective Input-Reconstruction Gate (SIR-Gate) that lets the model decide where to trust reconstruction versus the original input, thereby reducing irrelevant reconstruction artifacts and false alarms; and (ii) a Region-level Optimized Patch Selection (ROPS) scheme with positional cues to select overlapping patch reconstructions coherently across arbitrary resolutions. Organically integrating these mechanisms yields clean, high-resolution anomaly maps with low false positive (FP) rate. To bridge the gap in high-resolution PCBA datasets, we further contribute a self-collected dataset named SIPCBA-500 of 500 images. We conduct extensive experiments on our SIPCBA-500 as well as public benchmarks, demonstrating the superior localization performance of our method while running at practical speed. Full code and dataset will be made available upon acceptance.
SASep: Saliency-Aware Structured Separation of Geometry and Feature for Open Set Learning on Point Clouds
Jun 16, 2025Recent advancements in deep learning have greatly enhanced 3D object recognition, but most models are limited to closed-set scenarios, unable to handle unknown samples in real-world applications. Open-set recognition (OSR) addresses this limitation by enabling models to both classify known classes and identify novel classes. However, current OSR methods rely on global features to differentiate known and unknown classes, treating the entire object uniformly and overlooking the varying semantic importance of its different parts. To address this gap, we propose Salience-Aware Structured Separation (SASep), which includes (i) a tunable semantic decomposition (TSD) module to semantically decompose objects into important and unimportant parts, (ii) a geometric synthesis strategy (GSS) to generate pseudo-unknown objects by combining these unimportant parts, and (iii) a synth-aided margin separation (SMS) module to enhance feature-level separation by expanding the feature distributions between classes. Together, these components improve both geometric and feature representations, enhancing the model's ability to effectively distinguish known and unknown classes. Experimental results show that SASep achieves superior performance in 3D OSR, outperforming existing state-of-the-art methods.
Towards Robust Dialogue Breakdown Detection: Addressing Disruptors in Large Language Models with Self-Guided Reasoning
Apr 26, 2025


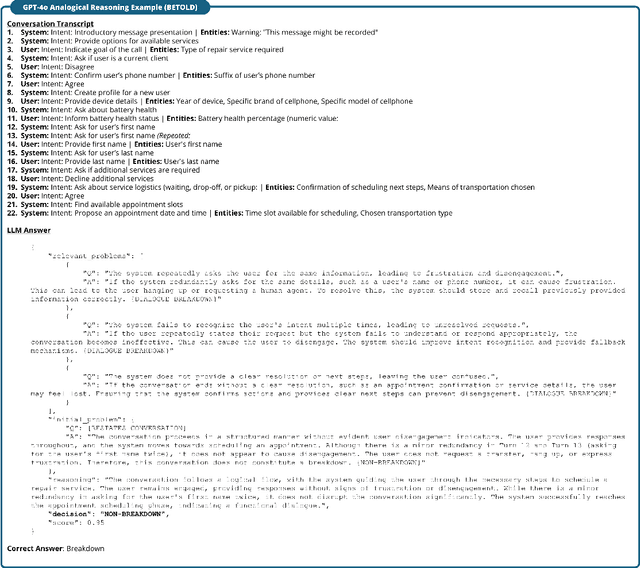
Large language models (LLMs) are rapidly changing various domains. However, their capabilities in handling conversational breakdowns still require an in-depth exploration. This paper addresses the challenge of detecting and mitigating dialogue breakdowns within LLM-driven conversational systems. While powerful models from OpenAI and Anthropic excel in many dialogue tasks, they can still produce incoherent or contradictory responses, commonly referred to as breakdowns, which undermine user trust. To tackle this, we propose an approach that combines specialized fine-tuning with advanced prompting strategies, including few-shot learning, chain-of-thought reasoning, and analogical prompting. In particular, we fine-tune a small 8B model and demonstrate its robust classification and calibration capabilities in English and Japanese dialogue. We also validate its generalization on the BETOLD dataset, achieving a 7\% accuracy improvement over its base model. Furthermore, we introduce a real-time deployment architecture that selectively escalates suspicious responses to more resource-intensive frontier models only when breakdowns are detected, significantly cutting operational expenses and energy consumption. Experimental results show our method surpasses prior state-of-the-art specialized classifiers while also narrowing performance gaps between smaller open-source models and large proprietary ones. Our approach offers a scalable solution for robust conversational AI in high-impact domains by combining efficiency, interpretability, and reliability.
Entropy-Aware Branching for Improved Mathematical Reasoning
Mar 27, 2025While Large Language Models (LLMs) are effectively aligned through extensive pre-training and fine-tuning, they still struggle with varying levels of uncertainty during token generation. In our investigation of mathematical reasoning, we observe that errors are more likely to arise at tokens exhibiting high entropy and variance of entropy in the model's output distribution. Based on the observation, we propose a novel approach that dynamically branches the generation process on demand instead of defaulting to the single most probable token. By exploring in parallel multiple branches stemming from high probability tokens of critical decision points, the model can discover diverse reasoning paths that might otherwise be missed. We further harness external feedback from larger models to rank and select the most coherent and accurate reasoning branch. Our experimental results on mathematical word problems and calculation questions show that this branching strategy boosts the reasoning capabilities of small LLMs up to 4.6% compared to conventional argmax decoding.
Fancy123: One Image to High-Quality 3D Mesh Generation via Plug-and-Play Deformation
Nov 25, 2024



Generating 3D meshes from a single image is an important but ill-posed task. Existing methods mainly adopt 2D multiview diffusion models to generate intermediate multiview images, and use the Large Reconstruction Model (LRM) to create the final meshes. However, the multiview images exhibit local inconsistencies, and the meshes often lack fidelity to the input image or look blurry. We propose Fancy123, featuring two enhancement modules and an unprojection operation to address the above three issues, respectively. The appearance enhancement module deforms the 2D multiview images to realign misaligned pixels for better multiview consistency. The fidelity enhancement module deforms the 3D mesh to match the input image. The unprojection of the input image and deformed multiview images onto LRM's generated mesh ensures high clarity, discarding LRM's predicted blurry-looking mesh colors. Extensive qualitative and quantitative experiments verify Fancy123's SoTA performance with significant improvement. Also, the two enhancement modules are plug-and-play and work at inference time, allowing seamless integration into various existing single-image-to-3D methods.
Fine-Tuning Language Models with Differential Privacy through Adaptive Noise Allocation
Oct 03, 2024
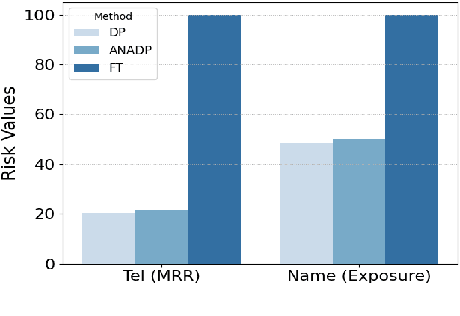
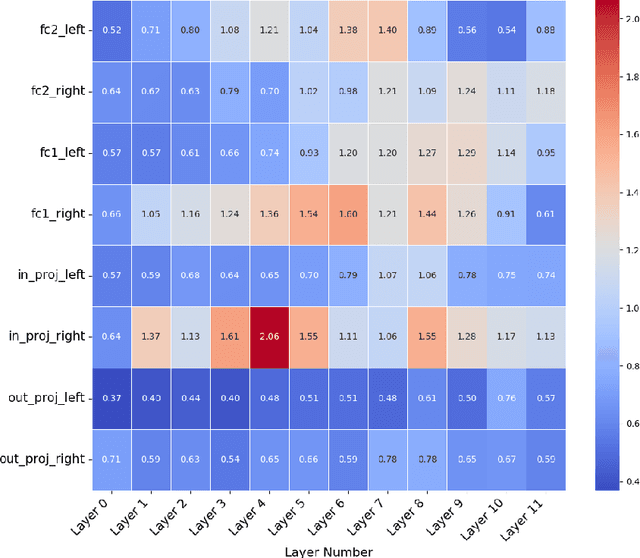

Language models are capable of memorizing detailed patterns and information, leading to a double-edged effect: they achieve impressive modeling performance on downstream tasks with the stored knowledge but also raise significant privacy concerns. Traditional differential privacy based training approaches offer robust safeguards by employing a uniform noise distribution across all parameters. However, this overlooks the distinct sensitivities and contributions of individual parameters in privacy protection and often results in suboptimal models. To address these limitations, we propose ANADP, a novel algorithm that adaptively allocates additive noise based on the importance of model parameters. We demonstrate that ANADP narrows the performance gap between regular fine-tuning and traditional DP fine-tuning on a series of datasets while maintaining the required privacy constraints.
RIDE: Boosting 3D Object Detection for LiDAR Point Clouds via Rotation-Invariant Analysis
Aug 29, 2024



The rotation robustness property has drawn much attention to point cloud analysis, whereas it still poses a critical challenge in 3D object detection. When subjected to arbitrary rotation, most existing detectors fail to produce expected outputs due to the poor rotation robustness. In this paper, we present RIDE, a pioneering exploration of Rotation-Invariance for the 3D LiDAR-point-based object DEtector, with the key idea of designing rotation-invariant features from LiDAR scenes and then effectively incorporating them into existing 3D detectors. Specifically, we design a bi-feature extractor that extracts (i) object-aware features though sensitive to rotation but preserve geometry well, and (ii) rotation-invariant features, which lose geometric information to a certain extent but are robust to rotation. These two kinds of features complement each other to decode 3D proposals that are robust to arbitrary rotations. Particularly, our RIDE is compatible and easy to plug into the existing one-stage and two-stage 3D detectors, and boosts both detection performance and rotation robustness. Extensive experiments on the standard benchmarks showcase that the mean average precision (mAP) and rotation robustness can be significantly boosted by integrating with our RIDE, with +5.6% mAP and 53% rotation robustness improvement on KITTI, +5.1% and 28% improvement correspondingly on nuScenes. The code will be available soon.
More Text, Less Point: Towards 3D Data-Efficient Point-Language Understanding
Aug 28, 2024
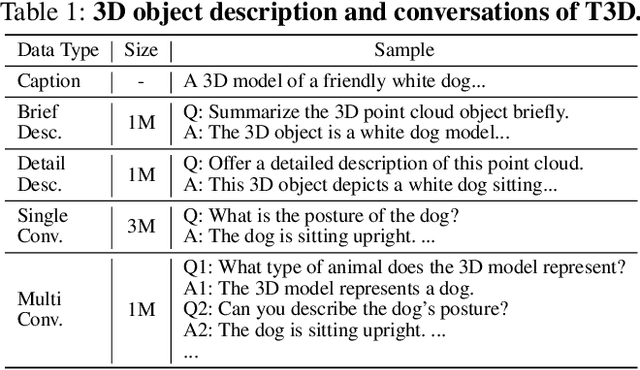
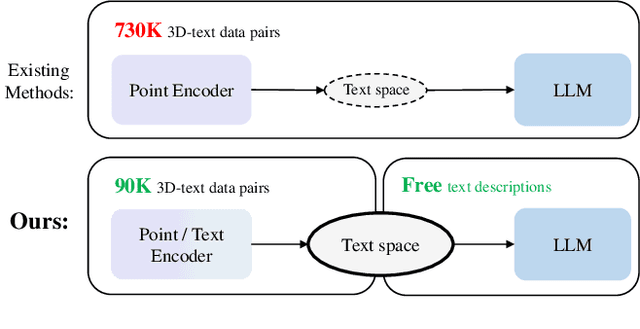
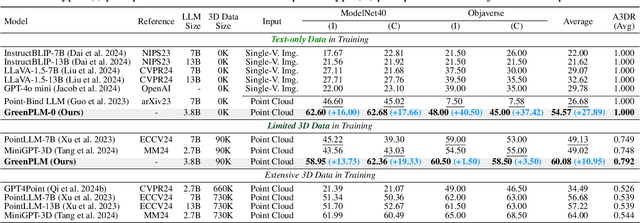
Enabling Large Language Models (LLMs) to comprehend the 3D physical world remains a significant challenge. Due to the lack of large-scale 3D-text pair datasets, the success of LLMs has yet to be replicated in 3D understanding. In this paper, we rethink this issue and propose a new task: 3D Data-Efficient Point-Language Understanding. The goal is to enable LLMs to achieve robust 3D object understanding with minimal 3D point cloud and text data pairs. To address this task, we introduce GreenPLM, which leverages more text data to compensate for the lack of 3D data. First, inspired by using CLIP to align images and text, we utilize a pre-trained point cloud-text encoder to map the 3D point cloud space to the text space. This mapping leaves us to seamlessly connect the text space with LLMs. Once the point-text-LLM connection is established, we further enhance text-LLM alignment by expanding the intermediate text space, thereby reducing the reliance on 3D point cloud data. Specifically, we generate 6M free-text descriptions of 3D objects, and design a three-stage training strategy to help LLMs better explore the intrinsic connections between different modalities. To achieve efficient modality alignment, we design a zero-parameter cross-attention module for token pooling. Extensive experimental results show that GreenPLM requires only 12% of the 3D training data used by existing state-of-the-art models to achieve superior 3D understanding. Remarkably, GreenPLM also achieves competitive performance using text-only data. The code and weights are available at: https://github.com/TangYuan96/GreenPLM.
PointDreamer: Zero-shot 3D Textured Mesh Reconstruction from Colored Point Cloud by 2D Inpainting
Jun 22, 2024Reconstructing textured meshes from colored point clouds is an important but challenging task in 3D graphics and vision. Most existing methods predict colors as implicit functions in 3D or UV space, suffering from blurry textures or the lack of generalization capability. Addressing this, we propose PointDreamer, a novel framework for textured mesh reconstruction from colored point cloud. It produces meshes with enhanced fidelity and clarity by 2D image inpainting, taking advantage of the mature techniques and massive data of 2D vision. Specifically, we first project the input point cloud into 2D space to generate sparse multi-view images, and then inpaint empty pixels utilizing a pre-trained 2D diffusion model. Next, we design a novel Non-Border-First strategy to unproject the colors of the inpainted dense images back to 3D space, thus obtaining the final textured mesh. In this way, our PointDreamer works in a zero-shot manner, requiring no extra training. Extensive qualitative and quantitative experiments on various synthetic and real-scanned datasets show the SoTA performance of PointDreamer, by significantly outperforming baseline methods with 30\% improvement in LPIPS score (from 0.118 to 0.068). Code at: https://github.com/YuQiao0303/PointDreamer.