 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturb Your Data: Paraphrase-Guided Training Data Watermarking
Dec 18, 2025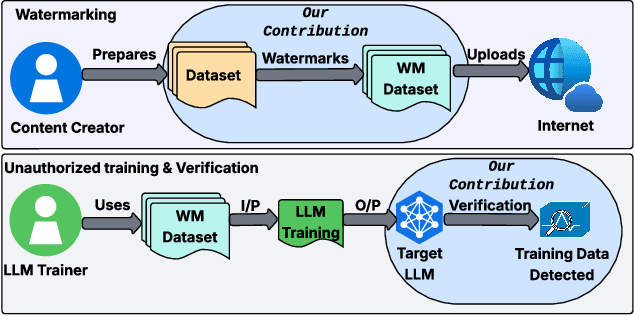
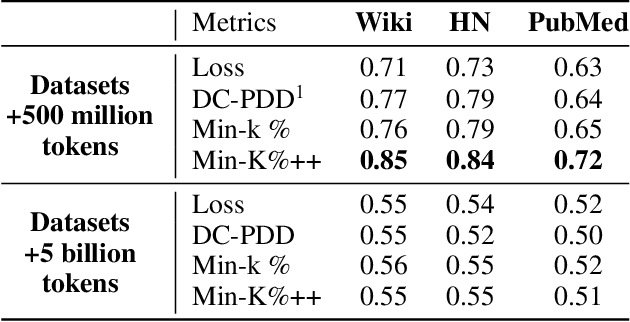
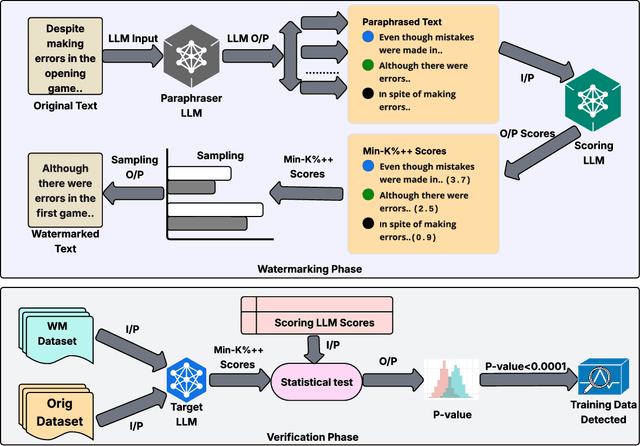
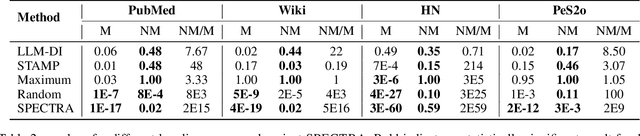
Training data detection is critical for enforcing copyright and data licensing, as Large Language Models (LLM) are trained on massive text corpora scraped from the internet. We present SPECTRA, a watermarking approach that makes training data reliably detectable even when it comprises less than 0.001% of the training corpus. SPECTRA works by paraphrasing text using an LLM and assigning a score based on how likely each paraphrase is, according to a separate scoring model. A paraphrase is chosen so that its score closely matches that of the original text, to avoid introducing any distribution shifts. To test whether a suspect model has been trained on the watermarked data, we compare its token probabilities against those of the scoring model. We demonstrate that SPECTRA achieves a consistent p-value gap of over nine orders of magnitude when detecting data used for training versus data not used for training, which is greater than all baselines tested. SPECTRA equips data owners with a scalable, deploy-before-release watermark that survives even large-scale LLM training.
CoCoLex: Confidence-guided Copy-based Decoding for Grounded Legal Text Generation
Aug 07, 2025Due to their ability to process long and complex contexts, LLMs can offer key benefits to the Legal domain, but their adoption has been hindered by their tendency to generate unfaithful, ungrounded, or hallucinatory outputs. While Retrieval-Augmented Generation offers a promising solution by grounding generations in external knowledge, it offers no guarantee that the provided context will be effectively integrated. To address this, context-aware decoding strategies have been proposed to amplify the influence of relevant context, but they usually do not explicitly enforce faithfulness to the context. In this work, we introduce Confidence-guided Copy-based Decoding for Legal Text Generation (CoCoLex)-a decoding strategy that dynamically interpolates the model produced vocabulary distribution with a distribution derived based on copying from the context. CoCoLex encourages direct copying based on the model's confidence, ensuring greater fidelity to the source. Experimental results on five legal benchmarks demonstrate that CoCoLex outperforms existing context-aware decoding methods, particularly in long-form generation tasks.
Entropy-Aware Branching for Improved Mathematical Reasoning
Mar 27, 2025While Large Language Models (LLMs) are effectively aligned through extensive pre-training and fine-tuning, they still struggle with varying levels of uncertainty during token generation. In our investigation of mathematical reasoning, we observe that errors are more likely to arise at tokens exhibiting high entropy and variance of entropy in the model's output distribution. Based on the observation, we propose a novel approach that dynamically branches the generation process on demand instead of defaulting to the single most probable token. By exploring in parallel multiple branches stemming from high probability tokens of critical decision points, the model can discover diverse reasoning paths that might otherwise be missed. We further harness external feedback from larger models to rank and select the most coherent and accurate reasoning branch. Our experimental results on mathematical word problems and calculation questions show that this branching strategy boosts the reasoning capabilities of small LLMs up to 4.6% compared to conventional argmax decoding.
"What is the value of {templates}?" Rethinking Document Information Extraction Datasets for LLMs
Oct 20, 2024
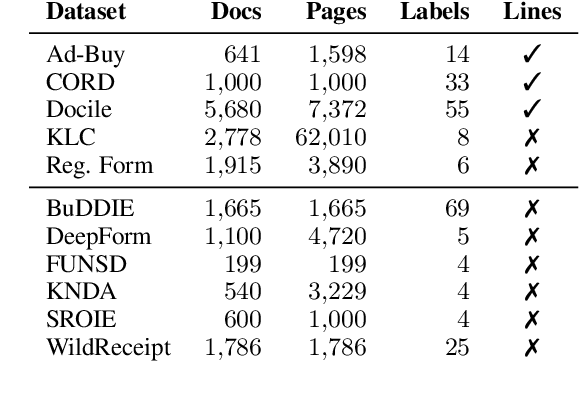

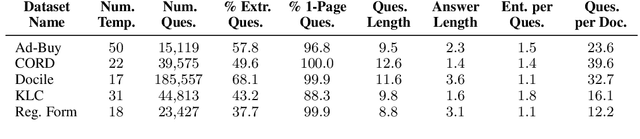
The rise of large language models (LLMs) for visually rich document understanding (VRDU) has kindled a need for prompt-response, document-based datasets. As annotating new datasets from scratch is labor-intensive, the existing literature has generated prompt-response datasets from available resources using simple templates. For the case of key information extraction (KIE), one of the most common VRDU tasks, past work has typically employed the template "What is the value for the {key}?". However, given the variety of questions encountered in the wild, simple and uniform templates are insufficient for creating robust models in research and industrial contexts. In this work, we present K2Q, a diverse collection of five datasets converted from KIE to a prompt-response format using a plethora of bespoke templates. The questions in K2Q can span multiple entities and be extractive or boolean. We empirically compare the performance of seven baseline generative models on K2Q with zero-shot prompting. We further compare three of these models when training on K2Q versus training on simpler templates to motivate the need of our work. We find that creating diverse and intricate KIE questions enhances the performance and robustness of VRDU models. We hope this work encourages future studies on data quality for generative model training.
Fine-Tuning Language Models with Differential Privacy through Adaptive Noise Allocation
Oct 03, 2024
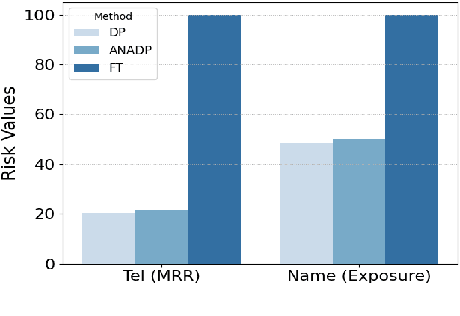

Language models are capable of memorizing detailed patterns and information, leading to a double-edged effect: they achieve impressive modeling performance on downstream tasks with the stored knowledge but also raise significant privacy concerns. Traditional differential privacy based training approaches offer robust safeguards by employing a uniform noise distribution across all parameters. However, this overlooks the distinct sensitivities and contributions of individual parameters in privacy protection and often results in suboptimal models. To address these limitations, we propose ANADP, a novel algorithm that adaptively allocates additive noise based on the importance of model parameters. We demonstrate that ANADP narrows the performance gap between regular fine-tuning and traditional DP fine-tuning on a series of datasets while maintaining the required privacy constraints.
BuDDIE: A Business Document Dataset for Multi-task Information Extraction
Apr 05, 2024The field of visually rich document understanding (VRDU) aims to solve a multitude of well-researched NLP tasks in a multi-modal domain. Several datasets exist for research on specific tasks of VRDU such as document classification (DC), key entity extraction (KEE), entity linking, visual question answering (VQA), inter alia. These datasets cover documents like invoices and receipts with sparse annotations such that they support one or two co-related tasks (e.g., entity extraction and entity linking). Unfortunately, only focusing on a single specific of documents or task is not representative of how documents often need to be processed in the wild - where variety in style and requirements is expected. In this paper, we introduce BuDDIE (Business Document Dataset for Information Extraction), the first multi-task dataset of 1,665 real-world business documents that contains rich and dense annotations for DC, KEE, and VQA. Our dataset consists of publicly available business entity documents from US state government websites. The documents are structured and vary in their style and layout across states and types (e.g., forms, certificates, reports, etc.). We provide data variety and quality metrics for BuDDIE as well as a series of baselines for each task. Our baselines cover traditional textual, multi-modal, and large language model approaches to VRDU.
TreeForm: End-to-end Annotation and Evaluation for Form Document Parsing
Feb 07, 2024Visually Rich Form Understanding (VRFU) poses a complex research problem due to the documents' highly structured nature and yet highly variable style and content. Current annotation schemes decompose form understanding and omit key hierarchical structure, making development and evaluation of end-to-end models difficult. In this paper, we propose a novel F1 metric to evaluate form parsers and describe a new content-agnostic, tree-based annotation scheme for VRFU: TreeForm. We provide methods to convert previous annotation schemes into TreeForm structures and evaluate TreeForm predictions using a modified version of the normalized tree-edit distance. We present initial baselines for our end-to-end performance metric and the TreeForm edit distance, averaged over the FUNSD and XFUND datasets, of 61.5 and 26.4 respectively. We hope that TreeForm encourages deeper research in annotating, modeling, and evaluating the complexities of form-like documents.
DocGraphLM: Documental Graph Language Model for Information Extraction
Jan 05, 2024



Advances in Visually Rich Document Understanding (VrDU) have enabled information extraction and question answering over documents with complex layouts. Two tropes of architectures have emerged -- transformer-based models inspired by LLMs, and Graph Neural Networks. In this paper, we introduce DocGraphLM, a novel framework that combines pre-trained language models with graph semantics. To achieve this, we propose 1) a joint encoder architecture to represent documents, and 2) a novel link prediction approach to reconstruct document graphs. DocGraphLM predicts both directions and distances between nodes using a convergent joint loss function that prioritizes neighborhood restoration and downweighs distant node detection. Our experiments on three SotA datasets show consistent improvement on IE and QA tasks with the adoption of graph features. Moreover, we report that adopting the graph features accelerates convergence in the learning process during training, despite being solely constructed through link prediction.
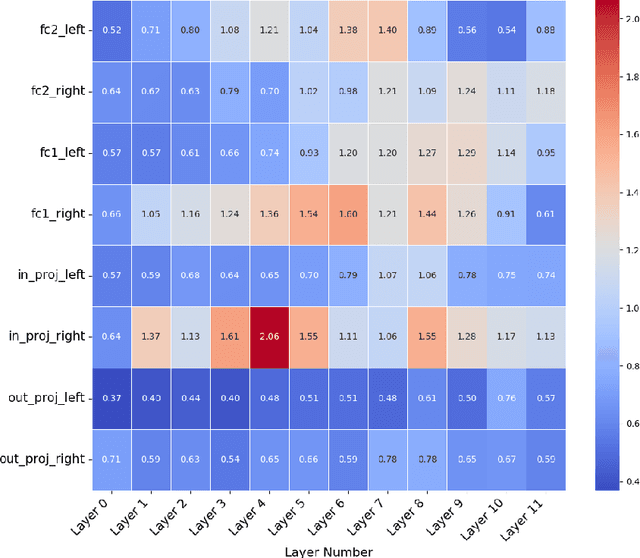
DocLLM: A layout-aware generative language model for multimodal document understanding
Dec 31, 2023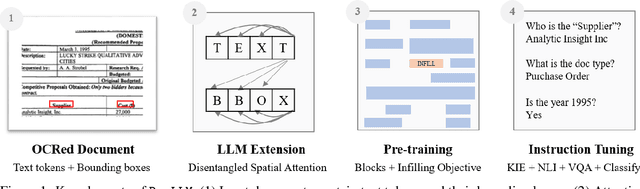

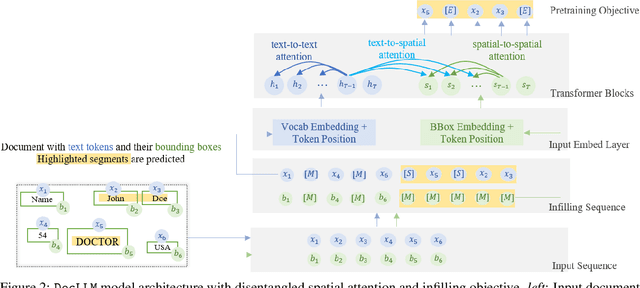
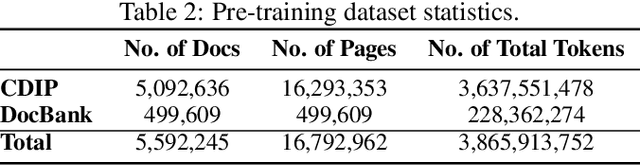
Enterprise documents such as forms, invoices, receipts, reports, contracts, and other similar records, often carry rich semantics at the intersection of textual and spatial modalities. The visual cues offered by their complex layouts play a crucial role in comprehending these documents effectively. In this paper, we present DocLLM, a lightweight extension to traditional large language models (LLMs) for reasoning over visual documents, taking into account both textual semantics and spatial layout. Our model differs from existing multimodal LLMs by avoiding expensive image encoders and focuses exclusively on bounding box information to incorporate the spatial layout structure. Specifically, the cross-alignment between text and spatial modalities is captured by decomposing the attention mechanism in classical transformers to a set of disentangled matrices. Furthermore, we devise a pre-training objective that learns to infill text segments. This approach allows us to address irregular layouts and heterogeneous content frequently encountered in visual documents. The pre-trained model is fine-tuned using a large-scale instruction dataset, covering four core document intelligence tasks. We demonstrate that our solution outperforms SotA LLMs on 14 out of 16 datasets across all tasks, and generalizes well to 4 out of 5 previously unseen datasets.
Learning from Imperfect Demonstrations through Dynamics Evaluation
Dec 18, 2023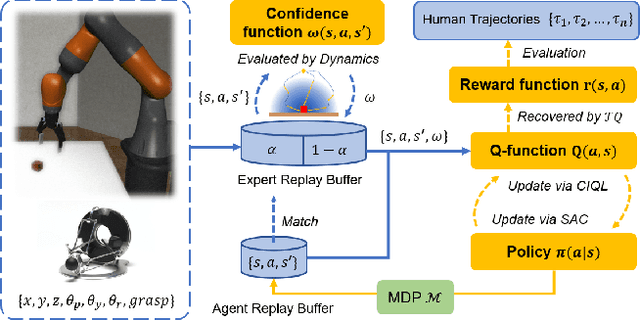
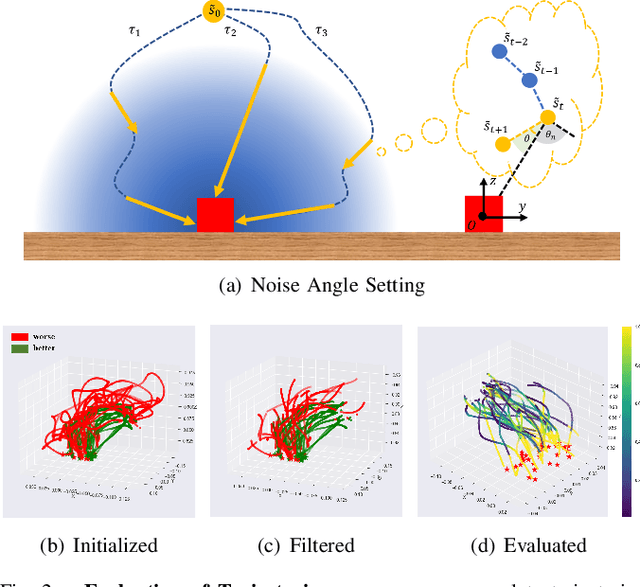

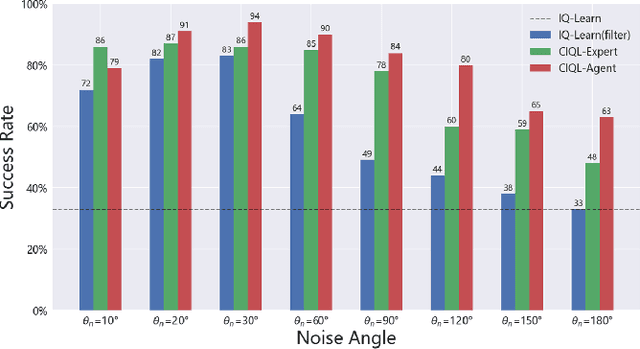
Standard imitation learning usually assumes that demonstrations are drawn from an optimal policy distribution. However, in real-world scenarios, every human demonstration may exhibit nearly random behavior and collecting high-quality human datasets can be quite costly. This requires imitation learning can learn from imperfect demonstrations to obtain robotic policies that align human intent. Prior work uses confidence scores to extract useful information from imperfect demonstrations, which relies on access to ground truth rewards or active human supervision. In this paper, we propose a dynamics-based method to evaluate the data confidence scores without above efforts. We develop a generalized confidence-based imitation learning framework called Confidence-based Inverse soft-Q Learning (CIQL), which can employ different optimal policy matching methods by simply changing object functions. Experimental results show that our confidence evaluation method can increase the success rate by $40.3\%$ over the original algorithm and $13.5\%$ over the simple noise filtering.