 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCoLex: Confidence-guided Copy-based Decoding for Grounded Legal Text Generation
Aug 07, 2025Due to their ability to process long and complex contexts, LLMs can offer key benefits to the Legal domain, but their adoption has been hindered by their tendency to generate unfaithful, ungrounded, or hallucinatory outputs. While Retrieval-Augmented Generation offers a promising solution by grounding generations in external knowledge, it offers no guarantee that the provided context will be effectively integrated. To address this, context-aware decoding strategies have been proposed to amplify the influence of relevant context, but they usually do not explicitly enforce faithfulness to the context. In this work, we introduce Confidence-guided Copy-based Decoding for Legal Text Generation (CoCoLex)-a decoding strategy that dynamically interpolates the model produced vocabulary distribution with a distribution derived based on copying from the context. CoCoLex encourages direct copying based on the model's confidence, ensuring greater fidelity to the source. Experimental results on five legal benchmarks demonstrate that CoCoLex outperforms existing context-aware decoding methods, particularly in long-form generation tasks.
Where is this coming from? Making groundedness count in the evaluation of Document VQA models
Mar 24, 2025Document Visual Question Answering (VQA) models have evolved at an impressive rate over the past few years, coming close to or matching human performance on some benchmarks. We argue that common evaluation metrics used by popular benchmarks do not account for the semantic and multimodal groundedness of a model's outputs. As a result, hallucinations and major semantic errors are treated the same way as well-grounded outputs, and the evaluation scores do not reflect the reasoning capabilities of the model. In response, we propose a new evaluation methodology that accounts for the groundedness of predictions with regard to the semantic characteristics of the output as well as the multimodal placement of the output within the input document. Our proposed methodology is parameterized in such a way that users can configure the score according to their preferences. We validate our scoring methodology using human judgment and show its potential impact on existing popular leaderboards. Through extensive analyses, we demonstrate that our proposed method produces scores that are a better indicator of a model's robustness and tends to give higher rewards to better-calibrated answers.
"What is the value of {templates}?" Rethinking Document Information Extraction Datasets for LLMs
Oct 20, 2024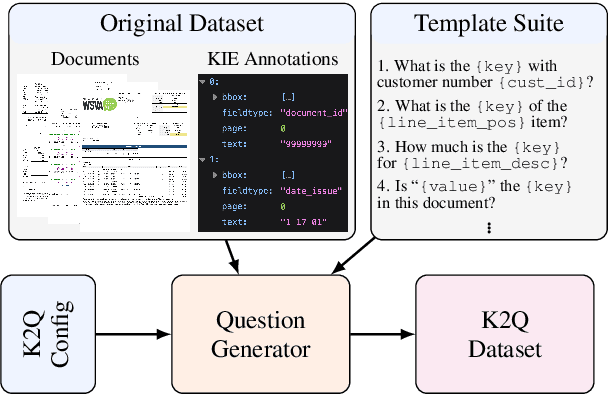
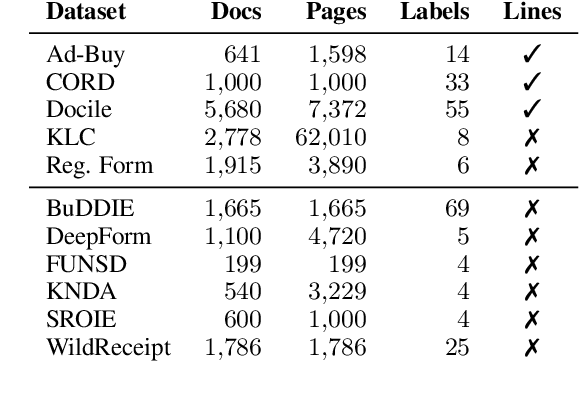

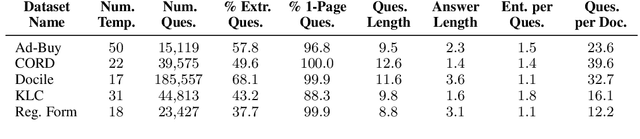
The rise of large language models (LLMs) for visually rich document understanding (VRDU) has kindled a need for prompt-response, document-based datasets. As annotating new datasets from scratch is labor-intensive, the existing literature has generated prompt-response datasets from available resources using simple templates. For the case of key information extraction (KIE), one of the most common VRDU tasks, past work has typically employed the template "What is the value for the {key}?". However, given the variety of questions encountered in the wild, simple and uniform templates are insufficient for creating robust models in research and industrial contexts. In this work, we present K2Q, a diverse collection of five datasets converted from KIE to a prompt-response format using a plethora of bespoke templates. The questions in K2Q can span multiple entities and be extractive or boolean. We empirically compare the performance of seven baseline generative models on K2Q with zero-shot prompting. We further compare three of these models when training on K2Q versus training on simpler templates to motivate the need of our work. We find that creating diverse and intricate KIE questions enhances the performance and robustness of VRDU models. We hope this work encourages future studies on data quality for generative model training.
BuDDIE: A Business Document Dataset for Multi-task Information Extraction
Apr 05, 2024The field of visually rich document understanding (VRDU) aims to solve a multitude of well-researched NLP tasks in a multi-modal domain. Several datasets exist for research on specific tasks of VRDU such as document classification (DC), key entity extraction (KEE), entity linking, visual question answering (VQA), inter alia. These datasets cover documents like invoices and receipts with sparse annotations such that they support one or two co-related tasks (e.g., entity extraction and entity linking). Unfortunately, only focusing on a single specific of documents or task is not representative of how documents often need to be processed in the wild - where variety in style and requirements is expected. In this paper, we introduce BuDDIE (Business Document Dataset for Information Extraction), the first multi-task dataset of 1,665 real-world business documents that contains rich and dense annotations for DC, KEE, and VQA. Our dataset consists of publicly available business entity documents from US state government websites. The documents are structured and vary in their style and layout across states and types (e.g., forms, certificates, reports, etc.). We provide data variety and quality metrics for BuDDIE as well as a series of baselines for each task. Our baselines cover traditional textual, multi-modal, and large language model approaches to VRDU.
TreeForm: End-to-end Annotation and Evaluation for Form Document Parsing
Feb 07, 2024



Visually Rich Form Understanding (VRFU) poses a complex research problem due to the documents' highly structured nature and yet highly variable style and content. Current annotation schemes decompose form understanding and omit key hierarchical structure, making development and evaluation of end-to-end models difficult. In this paper, we propose a novel F1 metric to evaluate form parsers and describe a new content-agnostic, tree-based annotation scheme for VRFU: TreeForm. We provide methods to convert previous annotation schemes into TreeForm structures and evaluate TreeForm predictions using a modified version of the normalized tree-edit distance. We present initial baselines for our end-to-end performance metric and the TreeForm edit distance, averaged over the FUNSD and XFUND datasets, of 61.5 and 26.4 respectively. We hope that TreeForm encourages deeper research in annotating, modeling, and evaluating the complexities of form-like documents.
DocGraphLM: Documental Graph Language Model for Information Extraction
Jan 05, 2024



Advances in Visually Rich Document Understanding (VrDU) have enabled information extraction and question answering over documents with complex layouts. Two tropes of architectures have emerged -- transformer-based models inspired by LLMs, and Graph Neural Networks. In this paper, we introduce DocGraphLM, a novel framework that combines pre-trained language models with graph semantics. To achieve this, we propose 1) a joint encoder architecture to represent documents, and 2) a novel link prediction approach to reconstruct document graphs. DocGraphLM predicts both directions and distances between nodes using a convergent joint loss function that prioritizes neighborhood restoration and downweighs distant node detection. Our experiments on three SotA datasets show consistent improvement on IE and QA tasks with the adoption of graph features. Moreover, we report that adopting the graph features accelerates convergence in the learning process during training, despite being solely constructed through link prediction.
DocLLM: A layout-aware generative language model for multimodal document understanding
Dec 31, 2023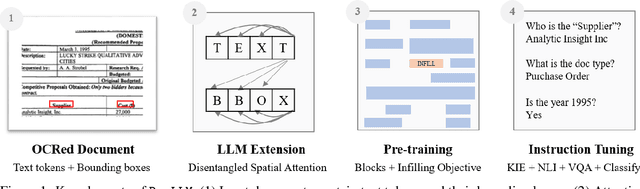

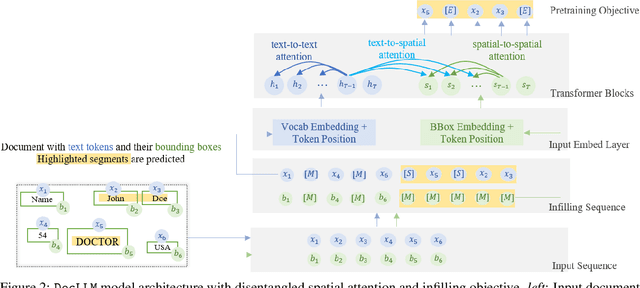
Enterprise documents such as forms, invoices, receipts, reports, contracts, and other similar records, often carry rich semantics at the intersection of textual and spatial modalities. The visual cues offered by their complex layouts play a crucial role in comprehending these documents effectively. In this paper, we present DocLLM, a lightweight extension to traditional large language models (LLMs) for reasoning over visual documents, taking into account both textual semantics and spatial layout. Our model differs from existing multimodal LLMs by avoiding expensive image encoders and focuses exclusively on bounding box information to incorporate the spatial layout structure. Specifically, the cross-alignment between text and spatial modalities is captured by decomposing the attention mechanism in classical transformers to a set of disentangled matrices. Furthermore, we devise a pre-training objective that learns to infill text segments. This approach allows us to address irregular layouts and heterogeneous content frequently encountered in visual documents. The pre-trained model is fine-tuned using a large-scale instruction dataset, covering four core document intelligence tasks. We demonstrate that our solution outperforms SotA LLMs on 14 out of 16 datasets across all tasks, and generalizes well to 4 out of 5 previously unseen datasets.
Parameterized Explanations for Investor / Company Matching
Oct 27, 2021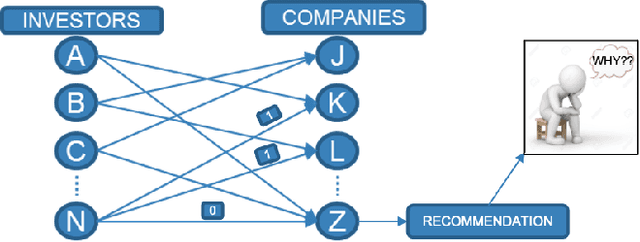
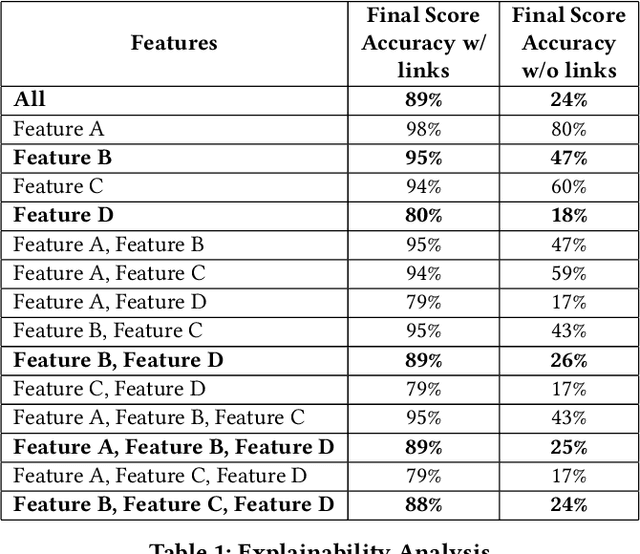
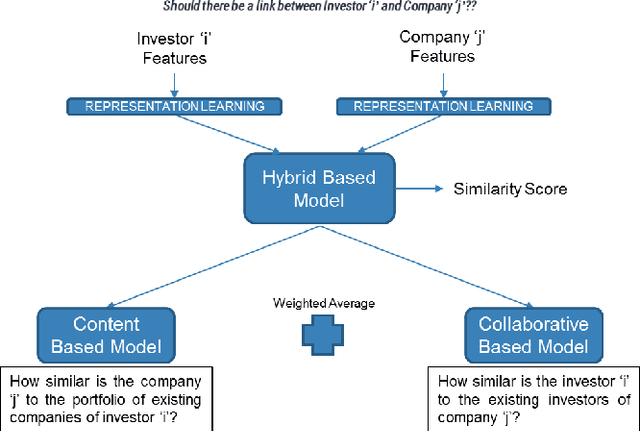
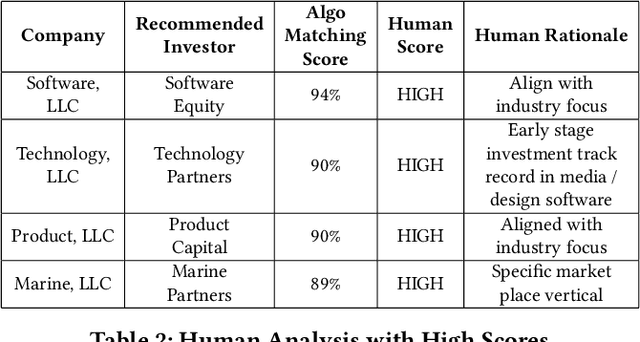
Matching companies and investors is usually considered a highly specialized decision making process. Building an AI agent that can automate such recommendation process can significantly help reduce costs, and eliminate human biases and errors. However, limited sample size of financial data-sets and the need for not only good recommendations, but also explaining why a particular recommendation is being made, makes this a challenging problem. In this work we propose a representation learning based recommendation engine that works extremely well with small datasets and demonstrate how it can be coupled with a parameterized explanation generation engine to build an explainable recommendation system for investor-company matching. We compare the performance of our system with human generated recommendations and demonstrate the ability of our algorithm to perform extremely well on this task. We also highlight how explainability helps with real-life adoption of our system.
A Framework for Institutional Risk Identification using Knowledge Graphs and Automated News Profiling
Sep 19, 2021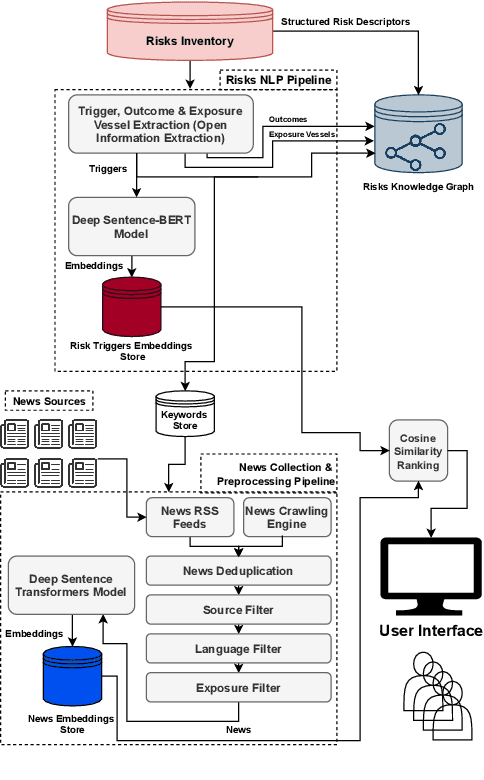


Organizations around the world face an array of risks impacting their operations globally. It is imperative to have a robust risk identification process to detect and evaluate the impact of potential risks before they materialize. Given the nature of the task and the current requirements of deep subject matter expertise, most organizations utilize a heavily manual process. In our work, we develop an automated system that (a) continuously monitors global news, (b) is able to autonomously identify and characterize risks, (c) is able to determine the proximity of reaching triggers to determine the distance from the manifestation of the risk impact and (d) identifies organization's operational areas that may be most impacted by the risk. Other contributions also include: (a) a knowledge graph representation of risks and (b) relevant news matching to risks identified by the organization utilizing a neural embedding model to match the textual description of a given risk with multi-lingual news.
Robust Document Representations using Latent Topics and Metadata
Oct 23, 2020



Task specific fine-tuning of a pre-trained neural language model using a custom softmax output layer is the de facto approach of late when dealing with document classification problems. This technique is not adequate when labeled examples are not available at training time and when the metadata artifacts in a document must be exploited. We address these challenges by generating document representations that capture both text and metadata artifacts in a task agnostic manner. Instead of traditional auto-regressive or auto-encoding based training, our novel self-supervised approach learns a soft-partition of the input space when generating text embeddings. Specifically, we employ a pre-learned topic model distribution as surrogate labels and construct a loss function based on KL divergence. Our solution also incorporates metadata explicitly rather than just augmenting them with text. The generated document embeddings exhibit compositional characteristics and are directly used by downstream classification tasks to create decision boundaries from a small number of labeled examples, thereby eschewing complicated recognition methods. We demonstrate through extensive evaluation that our proposed cross-model fusion solution outperforms several competitive baselines on multiple datasets.