 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuDDIE: A Business Document Dataset for Multi-task Information Extraction
Apr 05, 2024The field of visually rich document understanding (VRDU) aims to solve a multitude of well-researched NLP tasks in a multi-modal domain. Several datasets exist for research on specific tasks of VRDU such as document classification (DC), key entity extraction (KEE), entity linking, visual question answering (VQA), inter alia. These datasets cover documents like invoices and receipts with sparse annotations such that they support one or two co-related tasks (e.g., entity extraction and entity linking). Unfortunately, only focusing on a single specific of documents or task is not representative of how documents often need to be processed in the wild - where variety in style and requirements is expected. In this paper, we introduce BuDDIE (Business Document Dataset for Information Extraction), the first multi-task dataset of 1,665 real-world business documents that contains rich and dense annotations for DC, KEE, and VQA. Our dataset consists of publicly available business entity documents from US state government websites. The documents are structured and vary in their style and layout across states and types (e.g., forms, certificates, reports, etc.). We provide data variety and quality metrics for BuDDIE as well as a series of baselines for each task. Our baselines cover traditional textual, multi-modal, and large language model approaches to VRDU.
Neural Transition-based Parsing of Library Deprecations
Dec 23, 2022
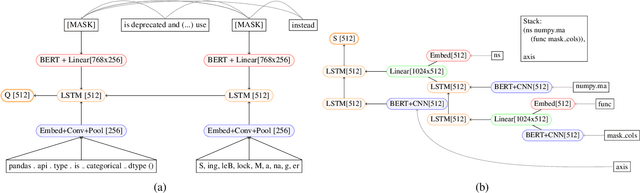


This paper tackles the challenging problem of automating code updates to fix deprecated API usages of open source libraries by analyzing their release notes. Our system employs a three-tier architecture: first, a web crawler service retrieves deprecation documentation from the web; then a specially built parser processes those text documents into tree-structured representations; finally, a client IDE plugin locates and fixes identified deprecated usages of libraries in a given codebase. The focus of this paper in particular is the parsing component. We introduce a novel transition-based parser in two variants: based on a classical feature engineered classifier and a neural tree encoder. To confirm the effectiveness of our method, we gathered and labeled a set of 426 API deprecations from 7 well-known Python data science libraries, and demonstrated our approach decisively outperforms a non-trivial neural machine translation baseline.
Data Stream Classification using Random Feature Functions and Novel Method Combinations
Nov 03, 2015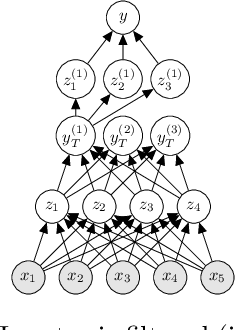
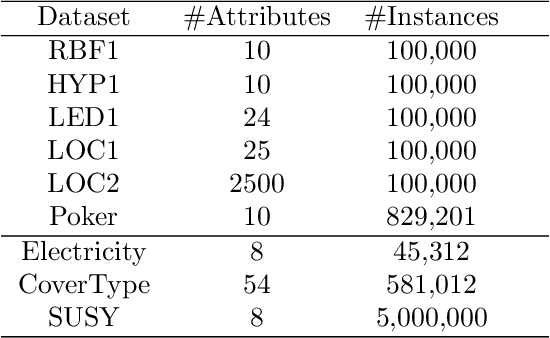
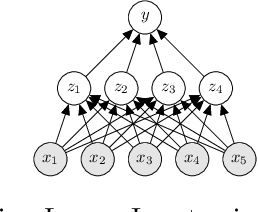
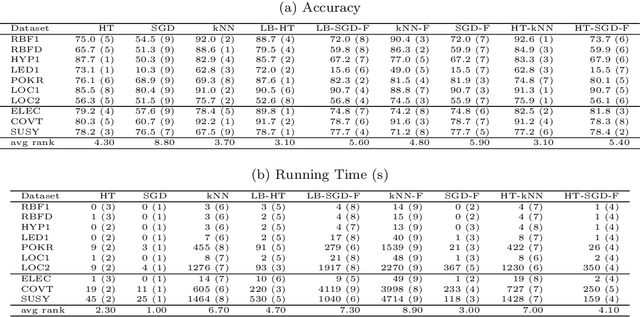
Big Data streams are being generated in a faster, bigger, and more commonplace. In this scenario, Hoeffding Trees are an established method for classification. Several extensions exist, including high-performing ensemble setups such as online and leveraging bagging. Also, $k$-nearest neighbors is a popular choice, with most extensions dealing with the inherent performance limitations over a potentially-infinite stream. At the same time, gradient descent methods are becoming increasingly popular, owing in part to the successes of deep learning. Although deep neural networks can learn incrementally, they have so far proved too sensitive to hyper-parameter options and initial conditions to be considered an effective `off-the-shelf' data-streams solution. In this work, we look at combinations of Hoeffding-trees, nearest neighbour, and gradient descent methods with a streaming preprocessing approach in the form of a random feature functions filter for additional predictive power. We further extend the investigation to implementing methods on GPUs, which we test on some large real-world datasets, and show the benefits of using GPUs for data-stream learning due to their high scalability. Our empirical evaluation yields positive results for the novel approaches that we experiment with, highlighting important issues, and shed light on promising future directions in approaches to data-stream classification.