 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiQ&A: An Analysis in Measuring Robustness via Automated Crowdsourcing of Question Perturbations and Answers
Feb 06, 2025One critical challenge in the institutional adoption journey of Large Language Models (LLMs) stems from their propensity to hallucinate in generated responses. To address this, we propose MultiQ&A, a systematic approach for evaluating the robustness and consistency of LLM-generated answers. We demonstrate MultiQ&A's ability to crowdsource question perturbations and their respective answers through independent LLM agents at scale. Our experiments culminated in the examination of 1.9 million question perturbations and 2.3 million answers. Furthermore, MultiQ&A shows that ensembled LLMs, such as gpt-3.5-turbo, remain relatively robust and consistent under perturbations. MultiQ&A provides clarity in the response generation space, offering an effective method for inspecting disagreements and variability. Therefore, our system offers a potential framework for institutional LLM adoption with the ability to measure confidence, consistency, and the quantification of hallucinations.
LAW: Legal Agentic Workflows for Custody and Fund Services Contracts
Dec 15, 2024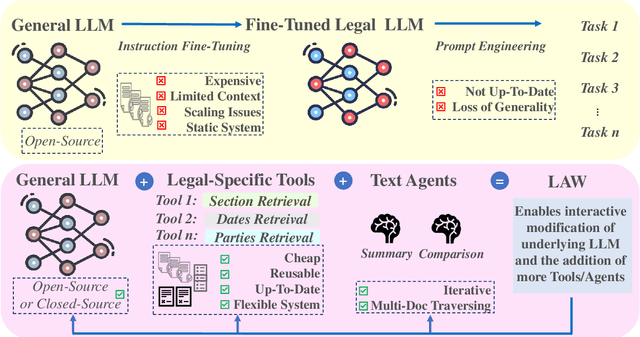
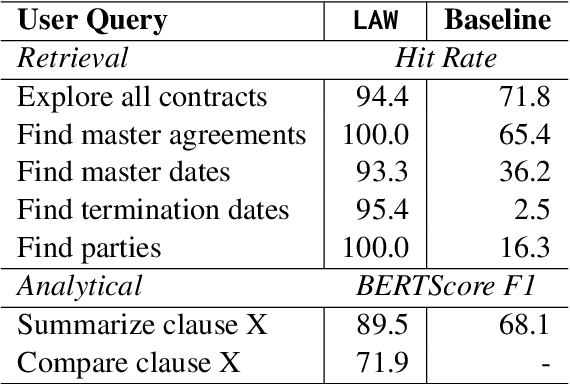
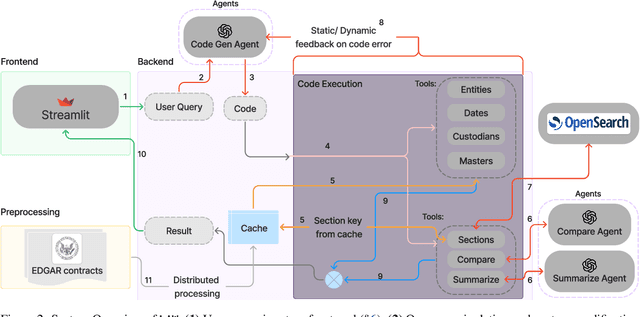

Legal contracts in the custody and fund services domain govern critical aspects such as key provider responsibilities, fee schedules, and indemnification rights. However, it is challenging for an off-the-shelf Large Language Model (LLM) to ingest these contracts due to the lengthy unstructured streams of text, limited LLM context windows, and complex legal jargon. To address these challenges, we introduce LAW (Legal Agentic Workflows for Custody and Fund Services Contracts). LAW features a modular design that responds to user queries by orchestrating a suite of domain-specific tools and text agents. Our experiments demonstrate that LAW, by integrating multiple specialized agents and tools, significantly outperforms the baseline. LAW excels particularly in complex tasks such as calculating a contract's termination date, surpassing the baseline by 92.9% points. Furthermore, LAW offers a cost-effective alternative to traditional fine-tuned legal LLMs by leveraging reusable, domain-specific tools.
FISHNET: Financial Intelligence from Sub-querying, Harmonizing, Neural-Conditioning, Expert Swarms, and Task Planning
Oct 25, 2024Financial intelligence generation from vast data sources has typically relied on traditional methods of knowledge-graph construction or database engineering. Recently, fine-tuned financial domain-specific Large Language Models (LLMs), have emerged. While these advancements are promising, limitations such as high inference costs, hallucinations, and the complexity of concurrently analyzing high-dimensional financial data, emerge. This motivates our invention FISHNET (Financial Intelligence from Sub-querying, Harmonizing, Neural-Conditioning, Expert swarming, and Task planning), an agentic architecture that accomplishes highly complex analytical tasks for more than 98,000 regulatory filings that vary immensely in terms of semantics, data hierarchy, or format. FISHNET shows remarkable performance for financial insight generation (61.8% success rate over 5.0% Routing, 45.6% RAG R-Precision). We conduct rigorous ablations to empirically prove the success of FISHNET, each agent's importance, and the optimized performance of assembling all agents. Our modular architecture can be leveraged for a myriad of use-cases, enabling scalability, flexibility, and data integrity that are critical for financial tasks.
HiddenTables & PyQTax: A Cooperative Game and Dataset For TableQA to Ensure Scale and Data Privacy Across a Myriad of Taxonomies
Jun 16, 2024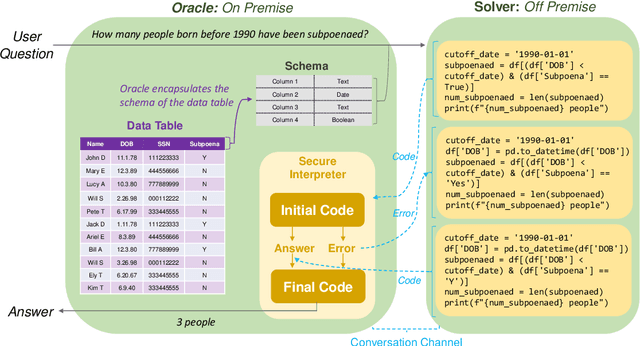
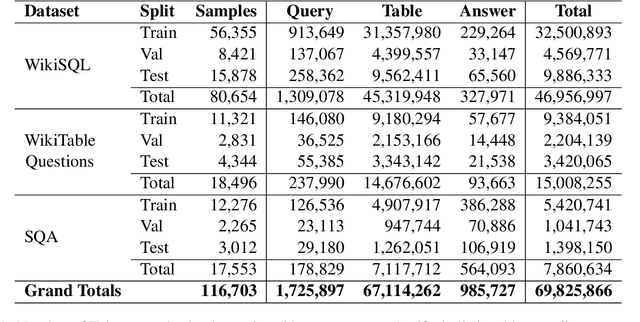

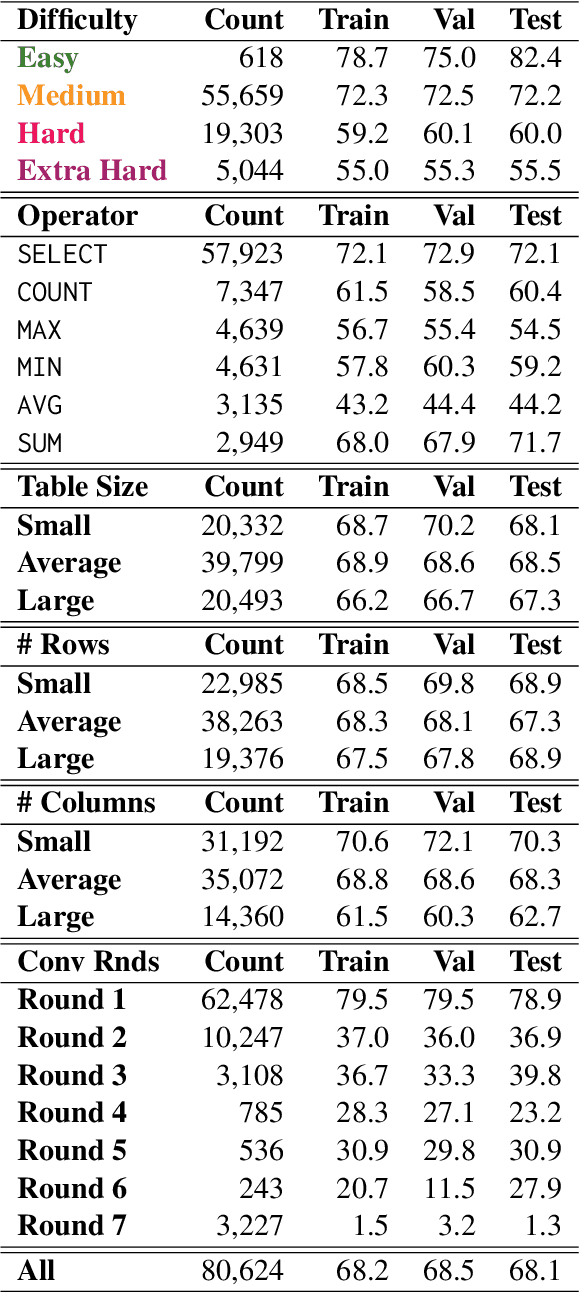
A myriad of different Large Language Models (LLMs) face a common challenge in contextually analyzing table question-answering tasks. These challenges are engendered from (1) finite context windows for large tables, (2) multi-faceted discrepancies amongst tokenization patterns against cell boundaries, and (3) various limitations stemming from data confidentiality in the process of using external models such as gpt-3.5-turbo. We propose a cooperative game dubbed "HiddenTables" as a potential resolution to this challenge. In essence, "HiddenTables" is played between the code-generating LLM "Solver" and the "Oracle" which evaluates the ability of the LLM agents to solve Table QA tasks. This game is based on natural language schemas and importantly, ensures the security of the underlying data. We provide evidential experiments on a diverse set of tables that demonstrate an LLM's collective inability to generalize and perform on complex queries, handle compositional dependencies, and align natural language to programmatic commands when concrete table schemas are provided. Unlike encoder-based models, we have pushed the boundaries of "HiddenTables" to not be limited by the number of rows - therefore we exhibit improved efficiency in prompt and completion tokens. Our infrastructure has spawned a new dataset "PyQTax" that spans across 116,671 question-table-answer triplets and provides additional fine-grained breakdowns & labels for varying question taxonomies. Therefore, in tandem with our academic contributions regarding LLMs' deficiency in TableQA tasks, "HiddenTables" is a tactile manifestation of how LLMs can interact with massive datasets while ensuring data security and minimizing generation costs.
* In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023)
HalluciBot: Is There No Such Thing as a Bad Question?
Apr 18, 2024Hallucination continues to be one of the most critical challenges in the institutional adoption journey of Large Language Models (LLMs). In this context, an overwhelming number of studies have focused on analyzing the post-generation phase - refining outputs via feedback, analyzing logit output values, or deriving clues via the outputs' artifacts. We propose HalluciBot, a model that predicts the probability of hallucination $\textbf{before generation}$, for any query imposed to an LLM. In essence, HalluciBot does not invoke any generation during inference. To derive empirical evidence for HalluciBot, we employ a Multi-Agent Monte Carlo Simulation using a Query Perturbator to craft $n$ variations per query at train time. The construction of our Query Perturbator is motivated by our introduction of a new definition of hallucination - $\textit{truthful hallucination}$. Our training methodology generated 2,219,022 estimates for a training corpus of 369,837 queries, spanning 13 diverse datasets and 3 question-answering scenarios. HalluciBot predicts both binary and multi-class probabilities of hallucination, enabling a means to judge the query's quality with regards to its propensity to hallucinate. Therefore, HalluciBot paves the way to revise or cancel a query before generation and the ensuing computational waste. Moreover, it provides a lucid means to measure user accountability for hallucinatory queries.
BuDDIE: A Business Document Dataset for Multi-task Information Extraction
Apr 05, 2024The field of visually rich document understanding (VRDU) aims to solve a multitude of well-researched NLP tasks in a multi-modal domain. Several datasets exist for research on specific tasks of VRDU such as document classification (DC), key entity extraction (KEE), entity linking, visual question answering (VQA), inter alia. These datasets cover documents like invoices and receipts with sparse annotations such that they support one or two co-related tasks (e.g., entity extraction and entity linking). Unfortunately, only focusing on a single specific of documents or task is not representative of how documents often need to be processed in the wild - where variety in style and requirements is expected. In this paper, we introduce BuDDIE (Business Document Dataset for Information Extraction), the first multi-task dataset of 1,665 real-world business documents that contains rich and dense annotations for DC, KEE, and VQA. Our dataset consists of publicly available business entity documents from US state government websites. The documents are structured and vary in their style and layout across states and types (e.g., forms, certificates, reports, etc.). We provide data variety and quality metrics for BuDDIE as well as a series of baselines for each task. Our baselines cover traditional textual, multi-modal, and large language model approaches to VRDU.
Directed Criteria Citation Recommendation and Ranking Through Link Prediction
Mar 18, 2024We explore link prediction as a proxy for automatically surfacing documents from existing literature that might be topically or contextually relevant to a new document. Our model uses transformer-based graph embeddings to encode the meaning of each document, presented as a node within a citation network. We show that the semantic representations that our model generates can outperform other content-based methods in recommendation and ranking tasks. This provides a holistic approach to exploring citation graphs in domains where it is critical that these documents properly cite each other, so as to minimize the possibility of any inconsistencies