 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Agentic Regulator: Risks for AI in Finance and a Proposed Agent-based Framework for Governance
Dec 12, 2025Generative and agentic artificial intelligence is entering financial markets faster than existing governance can adapt. Current model-risk frameworks assume static, well-specified algorithms and one-time validations; large language models and multi-agent trading systems violate those assumptions by learning continuously, exchanging latent signals, and exhibiting emergent behavior. Drawing on complex adaptive systems theory, we model these technologies as decentralized ensembles whose risks propagate along multiple time-scales. We then propose a modular governance architecture. The framework decomposes oversight into four layers of "regulatory blocks": (i) self-regulation modules embedded beside each model, (ii) firm-level governance blocks that aggregate local telemetry and enforce policy, (iii) regulator-hosted agents that monitor sector-wide indicators for collusive or destabilizing patterns, and (iv) independent audit blocks that supply third-party assurance. Eight design strategies enable the blocks to evolve as fast as the models they police. A case study on emergent spoofing in multi-agent trading shows how the layered controls quarantine harmful behavior in real time while preserving innovation. The architecture remains compatible with today's model-risk rules yet closes critical observability and control gaps, providing a practical path toward resilient, adaptive AI governance in financial systems.
TADACap: Time-series Adaptive Domain-Aware Captioning
Apr 15, 2025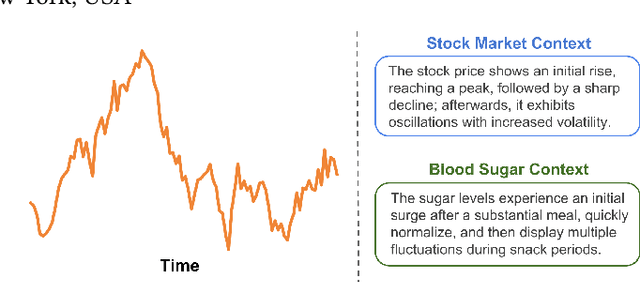



While image captioning has gained significant attention, the potential of captioning time-series images, prevalent in areas like finance and healthcare, remains largely untapped. Existing time-series captioning methods typically offer generic, domain-agnostic descriptions of time-series shapes and struggle to adapt to new domains without substantial retraining. To address these limitations, we introduce TADACap, a retrieval-based framework to generate domain-aware captions for time-series images, capable of adapting to new domains without retraining. Building on TADACap, we propose a novel retrieval strategy that retrieves diverse image-caption pairs from a target domain database, namely TADACap-diverse. We benchmarked TADACap-diverse against state-of-the-art methods and ablation variants. TADACap-diverse demonstrates comparable semantic accuracy while requiring significantly less annotation effort.
LAW: Legal Agentic Workflows for Custody and Fund Services Contracts
Dec 15, 2024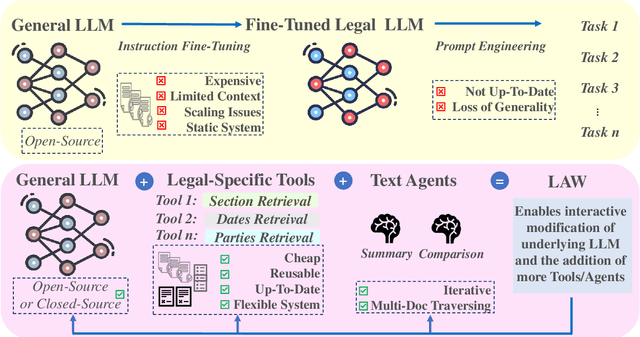
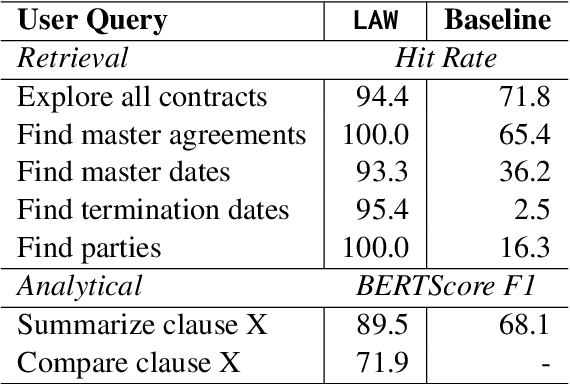
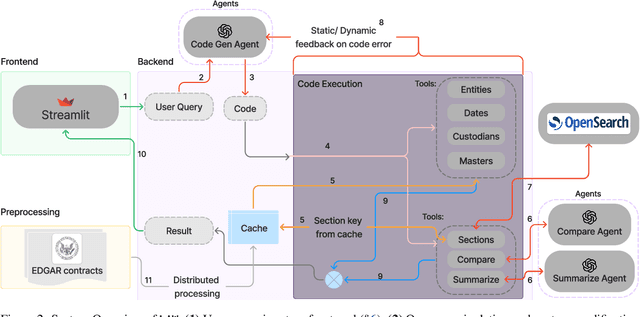

Legal contracts in the custody and fund services domain govern critical aspects such as key provider responsibilities, fee schedules, and indemnification rights. However, it is challenging for an off-the-shelf Large Language Model (LLM) to ingest these contracts due to the lengthy unstructured streams of text, limited LLM context windows, and complex legal jargon. To address these challenges, we introduce LAW (Legal Agentic Workflows for Custody and Fund Services Contracts). LAW features a modular design that responds to user queries by orchestrating a suite of domain-specific tools and text agents. Our experiments demonstrate that LAW, by integrating multiple specialized agents and tools, significantly outperforms the baseline. LAW excels particularly in complex tasks such as calculating a contract's termination date, surpassing the baseline by 92.9% points. Furthermore, LAW offers a cost-effective alternative to traditional fine-tuned legal LLMs by leveraging reusable, domain-specific tools.
AdaptAgent: Adapting Multimodal Web Agents with Few-Shot Learning from Human Demonstrations
Nov 20, 2024



State-of-the-art multimodal web agents, powered by Multimodal Large Language Models (MLLMs), can autonomously execute many web tasks by processing user instructions and interacting with graphical user interfaces (GUIs). Current strategies for building web agents rely on (i) the generalizability of underlying MLLMs and their steerability via prompting, and (ii) large-scale fine-tuning of MLLMs on web-related tasks. However, web agents still struggle to automate tasks on unseen websites and domains, limiting their applicability to enterprise-specific and proprietary platforms. Beyond generalization from large-scale pre-training and fine-tuning, we propose building agents for few-shot adaptability using human demonstrations. We introduce the AdaptAgent framework that enables both proprietary and open-weights multimodal web agents to adapt to new websites and domains using few human demonstrations (up to 2). Our experiments on two popular benchmarks -- Mind2Web & VisualWebArena -- show that using in-context demonstrations (for proprietary models) or meta-adaptation demonstrations (for meta-learned open-weights models) boosts task success rate by 3.36% to 7.21% over non-adapted state-of-the-art models, corresponding to a relative increase of 21.03% to 65.75%. Furthermore, our additional analyses (a) show the effectiveness of multimodal demonstrations over text-only ones, (b) shed light on the influence of different data selection strategies during meta-learning on the generalization of the agent, and (c) demonstrate the effect of number of few-shot examples on the web agent's success rate. Overall, our results unlock a complementary axis for developing widely applicable multimodal web agents beyond large-scale pre-training and fine-tuning, emphasizing few-shot adaptability.
Behavioral Sequence Modeling with Ensemble Learning
Nov 04, 2024



We investigate the use of sequence analysis for behavior modeling, emphasizing that sequential context often outweighs the value of aggregate features in understanding human behavior. We discuss framing common problems in fields like healthcare, finance, and e-commerce as sequence modeling tasks, and address challenges related to constructing coherent sequences from fragmented data and disentangling complex behavior patterns. We present a framework for sequence modeling using Ensembles of Hidden Markov Models, which are lightweight, interpretable, and efficient. Our ensemble-based scoring method enables robust comparison across sequences of different lengths and enhances performance in scenarios with imbalanced or scarce data. The framework scales in real-world scenarios, is compatible with downstream feature-based modeling, and is applicable in both supervised and unsupervised learning settings. We demonstrate the effectiveness of our method with results on a longitudinal human behavior dataset.
Variational Neural Stochastic Differential Equations with Change Points
Nov 01, 2024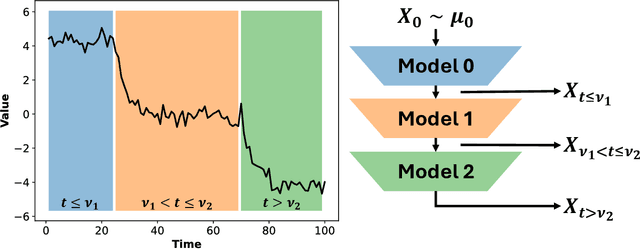


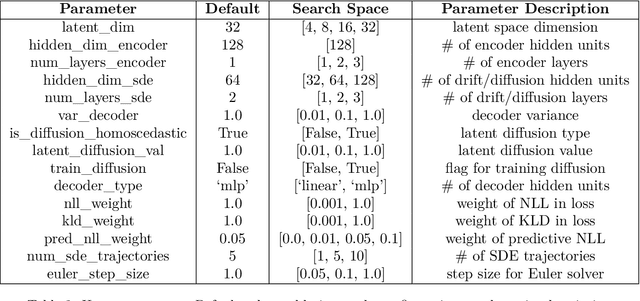
In this work, we explore modeling change points in time-series data using neural stochastic differential equations (neural SDEs). We propose a novel model formulation and training procedure based on the variational autoencoder (VAE) framework for modeling time-series as a neural SDE. Unlike existing algorithms training neural SDEs as VAEs, our proposed algorithm only necessitates a Gaussian prior of the initial state of the latent stochastic process, rather than a Wiener process prior on the entire latent stochastic process. We develop two methodologies for modeling and estimating change points in time-series data with distribution shifts. Our iterative algorithm alternates between updating neural SDE parameters and updating the change points based on either a maximum likelihood-based approach or a change point detection algorithm using the sequential likelihood ratio test. We provide a theoretical analysis of this proposed change point detection scheme. Finally, we present an empirical evaluation that demonstrates the expressive power of our proposed model, showing that it can effectively model both classical parametric SDEs and some real datasets with distribution shifts.
AI in Investment Analysis: LLMs for Equity Stock Ratings
Oct 30, 2024
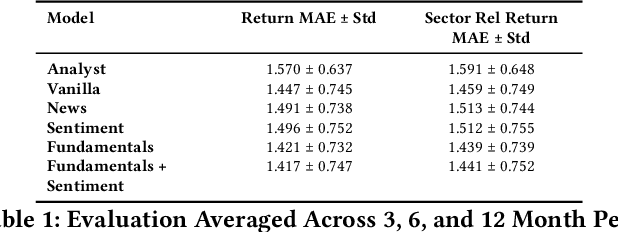
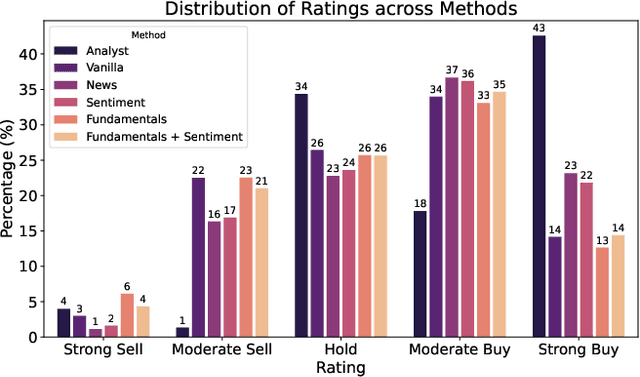
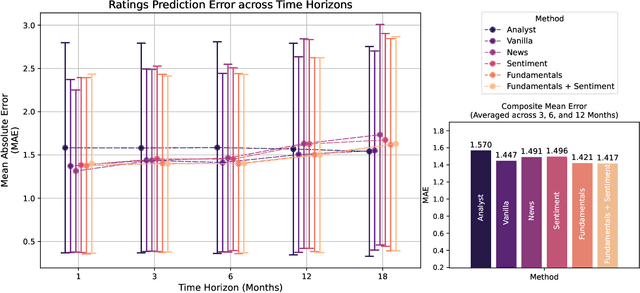
Investment Analysis is a cornerstone of the Financial Services industry. The rapid integration of advanced machine learning techniques, particularly Large Language Models (LLMs), offers opportunities to enhance the equity rating process. This paper explores the application of LLMs to generate multi-horizon stock ratings by ingesting diverse datasets. Traditional stock rating methods rely heavily on the expertise of financial analysts, and face several challenges such as data overload, inconsistencies in filings, and delayed reactions to market events. Our study addresses these issues by leveraging LLMs to improve the accuracy and consistency of stock ratings. Additionally, we assess the efficacy of using different data modalities with LLMs for the financial domain. We utilize varied datasets comprising fundamental financial, market, and news data from January 2022 to June 2024, along with GPT-4-32k (v0613) (with a training cutoff in Sep. 2021 to prevent information leakage). Our results show that our benchmark method outperforms traditional stock rating methods when assessed by forward returns, specially when incorporating financial fundamentals. While integrating news data improves short-term performance, substituting detailed news summaries with sentiment scores reduces token use without loss of performance. In many cases, omitting news data entirely enhances performance by reducing bias. Our research shows that LLMs can be leveraged to effectively utilize large amounts of multimodal financial data, as showcased by their effectiveness at the stock rating prediction task. Our work provides a reproducible and efficient framework for generating accurate stock ratings, serving as a cost-effective alternative to traditional methods. Future work will extend to longer timeframes, incorporate diverse data, and utilize newer models for enhanced insights.
Shining a Light on Hurricane Damage Estimation via Nighttime Light Data: Pre-processing Matters
Oct 29, 2024Amidst escalating climate change, hurricanes are inflicting severe socioeconomic impacts, marked by heightened economic losses and increased displacement. Previous research utilized nighttime light data to predict the impact of hurricanes on economic losses. However, prior work did not provide a thorough analysis of the impact of combining different techniques for pre-processing nighttime light (NTL) data. Addressing this gap, our research explores a variety of NTL pre-processing techniques, including value thresholding, built masking, and quality filtering and imputation, applied to two distinct datasets, VSC-NTL and VNP46A2, at the zip code level. Experiments evaluate the correlation of the denoised NTL data with economic damages of Category 4-5 hurricanes in Florida. They reveal that the quality masking and imputation technique applied to VNP46A2 show a substantial correlation with economic damage data.
Auditing and Enforcing Conditional Fairness via Optimal Transport
Oct 17, 2024

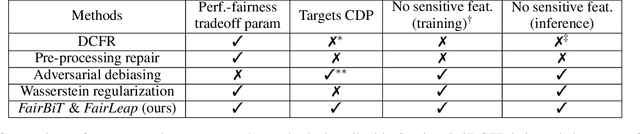

Conditional demographic parity (CDP) is a measure of the demographic parity of a predictive model or decision process when conditioning on an additional feature or set of features. Many algorithmic fairness techniques exist to target demographic parity, but CDP is much harder to achieve, particularly when the conditioning variable has many levels and/or when the model outputs are continuous. The problem of auditing and enforcing CDP is understudied in the literature. In light of this, we propose novel measures of {conditional demographic disparity (CDD)} which rely on statistical distances borrowed from the optimal transport literature. We further design and evaluate regularization-based approaches based on these CDD measures. Our methods, \fairbit{} and \fairlp{}, allow us to target CDP even when the conditioning variable has many levels. When model outputs are continuous, our methods target full equality of the conditional distributions, unlike other methods that only consider first moments or related proxy quantities. We validate the efficacy of our approaches on real-world datasets.
Ensemble Methods for Sequence Classification with Hidden Markov Models
Sep 11, 2024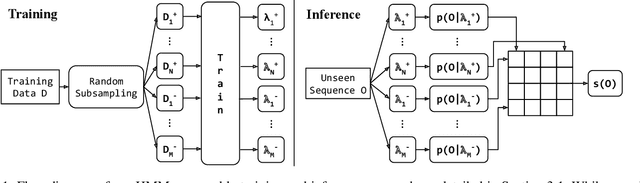


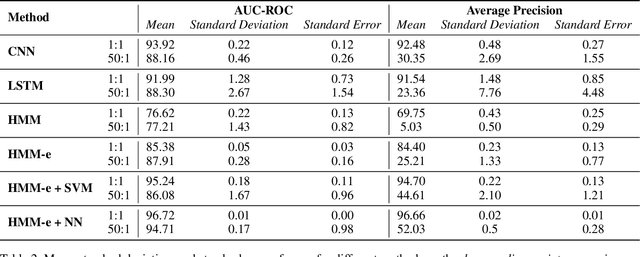
We present a lightweight approach to sequence classification using Ensemble Methods for Hidden Markov Models (HMMs). HMMs offer significant advantages in scenarios with imbalanced or smaller datasets due to their simplicity, interpretability, and efficiency. These models are particularly effective in domains such as finance and biology, where traditional methods struggle with high feature dimensionality and varied sequence lengths. Our ensemble-based scoring method enables the comparison of sequences of any length and improves performance on imbalanced datasets. This study focuses on the binary classification problem, particularly in scenarios with data imbalance, where the negative class is the majority (e.g., normal data) and the positive class is the minority (e.g., anomalous data), often with extreme distribution skews. We propose a novel training approach for HMM Ensembles that generalizes to multi-class problems and supports classification and anomaly detection. Our method fits class-specific groups of diverse models using random data subsets, and compares likelihoods across classes to produce composite scores, achieving high average precisions and AUCs. In addition, we compare our approach with neural network-based methods such as Convolutional Neural Networks (CNNs) and Long Short-Term Memory networks (LSTMs), highlighting the efficiency and robustness of HMMs in data-scarce environments. Motivated by real-world use cases, our method demonstrates robust performance across various benchmarks, offering a flexible framework for diverse applications.