 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Situating Innovations, Opportunities, and Challenges in Advancing Vertical Systems with Large AI Models
Apr 03, 2025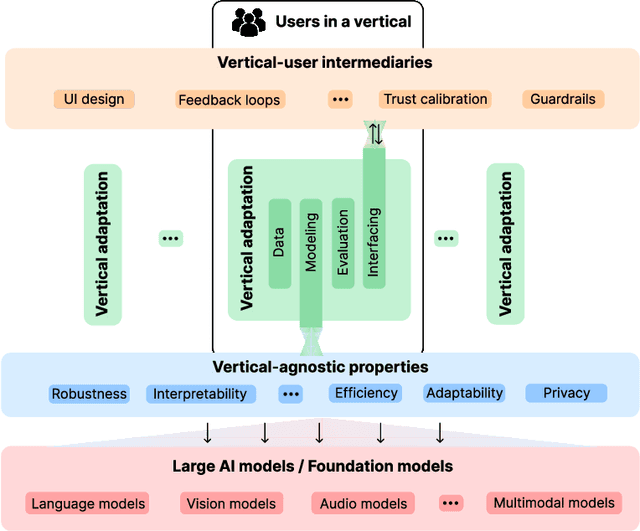
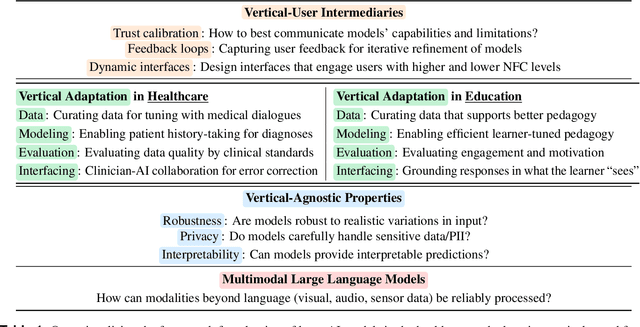
Large artificial intelligence (AI) models have garnered significant attention for their remarkable, often "superhuman", performance on standardized benchmarks. However, when these models are deployed in high-stakes verticals such as healthcare, education, and law, they often reveal notable limitations. For instance, they exhibit brittleness to minor variations in input data, present contextually uninformed decisions in critical settings, and undermine user trust by confidently producing or reproducing inaccuracies. These challenges in applying large models necessitate cross-disciplinary innovations to align the models' capabilities with the needs of real-world applications. We introduce a framework that addresses this gap through a layer-wise abstraction of innovations aimed at meeting users' requirements with large models. Through multiple case studies, we illustrate how researchers and practitioners across various fields can operationalize this framework. Beyond modularizing the pipeline of transforming large models into useful "vertical systems", we also highlight the dynamism that exists within different layers of the framework. Finally, we discuss how our framework can guide researchers and practitioners to (i) optimally situate their innovations (e.g., when vertical-specific insights can empower broadly impactful vertical-agnostic innovations), (ii) uncover overlooked opportunities (e.g., spotting recurring problems across verticals to develop practically useful foundation models instead of chasing benchmarks), and (iii) facilitate cross-disciplinary communication of critical challenges (e.g., enabling a shared vocabulary for AI developers, domain experts, and human-computer interaction scholars).
AdaptAgent: Adapting Multimodal Web Agents with Few-Shot Learning from Human Demonstrations
Nov 20, 2024



State-of-the-art multimodal web agents, powered by Multimodal Large Language Models (MLLMs), can autonomously execute many web tasks by processing user instructions and interacting with graphical user interfaces (GUIs). Current strategies for building web agents rely on (i) the generalizability of underlying MLLMs and their steerability via prompting, and (ii) large-scale fine-tuning of MLLMs on web-related tasks. However, web agents still struggle to automate tasks on unseen websites and domains, limiting their applicability to enterprise-specific and proprietary platforms. Beyond generalization from large-scale pre-training and fine-tuning, we propose building agents for few-shot adaptability using human demonstrations. We introduce the AdaptAgent framework that enables both proprietary and open-weights multimodal web agents to adapt to new websites and domains using few human demonstrations (up to 2). Our experiments on two popular benchmarks -- Mind2Web & VisualWebArena -- show that using in-context demonstrations (for proprietary models) or meta-adaptation demonstrations (for meta-learned open-weights models) boosts task success rate by 3.36% to 7.21% over non-adapted state-of-the-art models, corresponding to a relative increase of 21.03% to 65.75%. Furthermore, our additional analyses (a) show the effectiveness of multimodal demonstrations over text-only ones, (b) shed light on the influence of different data selection strategies during meta-learning on the generalization of the agent, and (c) demonstrate the effect of number of few-shot examples on the web agent's success rate. Overall, our results unlock a complementary axis for developing widely applicable multimodal web agents beyond large-scale pre-training and fine-tuning, emphasizing few-shot adaptability.
UniGuard: Towards Universal Safety Guardrails for Jailbreak Attacks on Multimodal Large Language Models
Nov 03, 2024



Multimodal large language models (MLLMs) have revolutionized vision-language understanding but are vulnerable to multimodal jailbreak attacks, where adversaries meticulously craft inputs to elicit harmful or inappropriate responses. We propose UniGuard, a novel multimodal safety guardrail that jointly considers the unimodal and cross-modal harmful signals. UniGuard is trained such that the likelihood of generating harmful responses in a toxic corpus is minimized, and can be seamlessly applied to any input prompt during inference with minimal computational costs. Extensive experiments demonstrate the generalizability of UniGuard across multiple modalities and attack strategies. It demonstrates impressive generalizability across multiple state-of-the-art MLLMs, including LLaVA, Gemini Pro, GPT-4, MiniGPT-4, and InstructBLIP, thereby broadening the scope of our solution.
Lived Experience Not Found: LLMs Struggle to Align with Experts on Addressing Adverse Drug Reactions from Psychiatric Medication Use
Oct 24, 2024



Adverse Drug Reactions (ADRs) from psychiatric medications are the leading cause of hospitalizations among mental health patients. With healthcare systems and online communities facing limitations in resolving ADR-related issues, Large Language Models (LLMs) have the potential to fill this gap. Despite the increasing capabilities of LLMs, past research has not explored their capabilities in detecting ADRs related to psychiatric medications or in providing effective harm reduction strategies. To address this, we introduce the Psych-ADR benchmark and the Adverse Drug Reaction Response Assessment (ADRA) framework to systematically evaluate LLM performance in detecting ADR expressions and delivering expert-aligned mitigation strategies. Our analyses show that LLMs struggle with understanding the nuances of ADRs and differentiating between types of ADRs. While LLMs align with experts in terms of expressed emotions and tone of the text, their responses are more complex, harder to read, and only 70.86% aligned with expert strategies. Furthermore, they provide less actionable advice by a margin of 12.32% on average. Our work provides a comprehensive benchmark and evaluation framework for assessing LLMs in strategy-driven tasks within high-risk domains.
Adversarial Text Rewriting for Text-aware Recommender Systems
Aug 01, 2024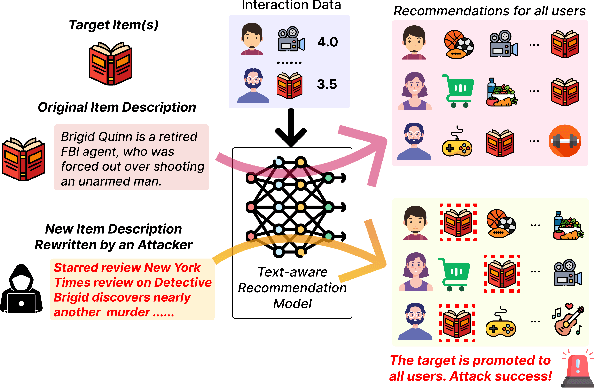

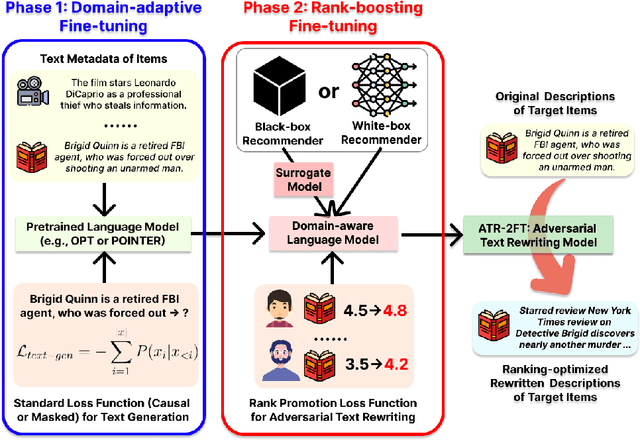

Text-aware recommender systems incorporate rich textual features, such as titles and descriptions, to generate item recommendations for users. The use of textual features helps mitigate cold-start problems, and thus, such recommender systems have attracted increased attention. However, we argue that the dependency on item descriptions makes the recommender system vulnerable to manipulation by adversarial sellers on e-commerce platforms. In this paper, we explore the possibility of such manipulation by proposing a new text rewriting framework to attack text-aware recommender systems. We show that the rewriting attack can be exploited by sellers to unfairly uprank their products, even though the adversarially rewritten descriptions are perceived as realistic by human evaluators. Methodologically, we investigate two different variations to carry out text rewriting attacks: (1) two-phase fine-tuning for greater attack performance, and (2) in-context learning for higher text rewriting quality. Experiments spanning 3 different datasets and 4 existing approaches demonstrate that recommender systems exhibit vulnerability against the proposed text rewriting attack. Our work adds to the existing literature around the robustness of recommender systems, while highlighting a new dimension of vulnerability in the age of large-scale automated text generation.
A Community-Centric Perspective for Characterizing and Detecting Anti-Asian Violence-Provoking Speech
Jul 21, 2024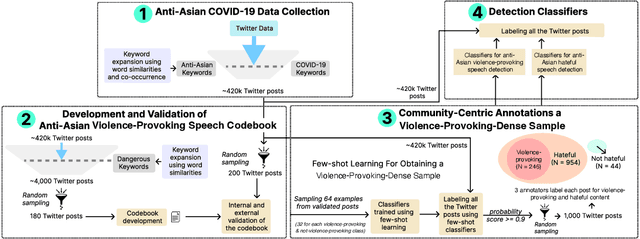



Violence-provoking speech -- speech that implicitly or explicitly promotes violence against the members of the targeted community, contributed to a massive surge in anti-Asian crimes during the pandemic. While previous works have characterized and built tools for detecting other forms of harmful speech, like fear speech and hate speech, our work takes a community-centric approach to studying anti-Asian violence-provoking speech. Using data from ~420k Twitter posts spanning a 3-year duration (January 1, 2020 to February 1, 2023), we develop a codebook to characterize anti-Asian violence-provoking speech and collect a community-crowdsourced dataset to facilitate its large-scale detection using state-of-the-art classifiers. We contrast the capabilities of natural language processing classifiers, ranging from BERT-based to LLM-based classifiers, in detecting violence-provoking speech with their capabilities to detect anti-Asian hateful speech. In contrast to prior work that has demonstrated the effectiveness of such classifiers in detecting hateful speech ($F_1 = 0.89$), our work shows that accurate and reliable detection of violence-provoking speech is a challenging task ($F_1 = 0.69$). We discuss the implications of our findings, particularly the need for proactive interventions to support Asian communities during public health crises. The resources related to the study are available at https://claws-lab.github.io/violence-provoking-speech/.
Explore as a Storm, Exploit as a Raindrop: On the Benefit of Fine-Tuning Kernel Schedulers with Coordinate Descent
Jun 28, 2024



Machine-learning models consist of kernels, which are algorithms applying operations on tensors -- data indexed by a linear combination of natural numbers. Examples of kernels include convolutions, transpositions, and vectorial products. There are many ways to implement a kernel. These implementations form the kernel's optimization space. Kernel scheduling is the problem of finding the best implementation, given an objective function -- typically execution speed. Kernel optimizers such as Ansor, Halide, and AutoTVM solve this problem via search heuristics, which combine two phases: exploration and exploitation. The first step evaluates many different kernel optimization spaces. The latter tries to improve the best implementations by investigating a kernel within the same space. For example, Ansor combines kernel generation through sketches for exploration and leverages an evolutionary algorithm to exploit the best sketches. In this work, we demonstrate the potential to reduce Ansor's search time while enhancing kernel quality by incorporating Droplet Search, an AutoTVM algorithm, into Ansor's exploration phase. The approach involves limiting the number of samples explored by Ansor, selecting the best, and exploiting it with a coordinate descent algorithm. By applying this approach to the first 300 kernels that Ansor generates, we usually obtain better kernels in less time than if we let Ansor analyze 10,000 kernels. This result has been replicated in 20 well-known deep-learning models (AlexNet, ResNet, VGG, DenseNet, etc.) running on four architectures: an AMD Ryzen 7 (x86), an NVIDIA A100 tensor core, an NVIDIA RTX 3080 GPU, and an ARM A64FX. A patch with this combined approach was approved in Ansor in February 2024. As evidence of the generality of this search methodology, a similar patch, achieving equally good results, was submitted to TVM's MetaSchedule in June 2024.
Mysterious Projections: Multimodal LLMs Gain Domain-Specific Visual Capabilities Without Richer Cross-Modal Projections
Feb 26, 2024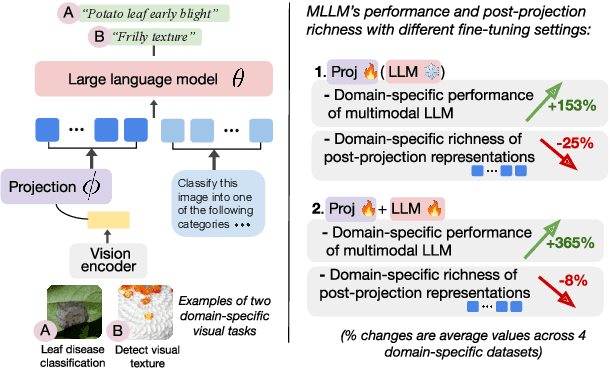
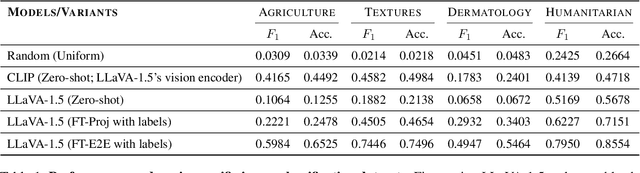
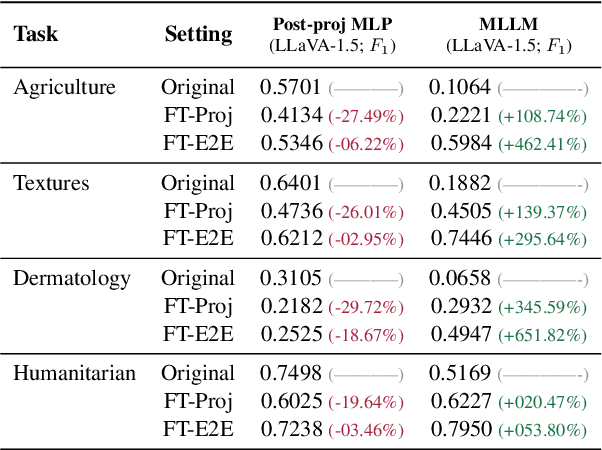
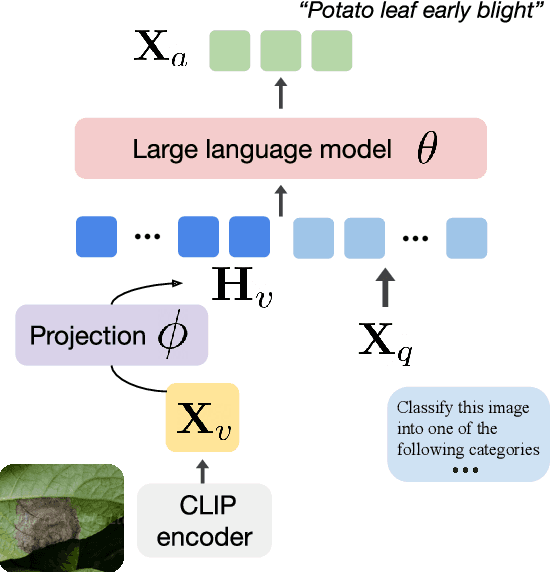
Multimodal large language models (MLLMs) like LLaVA and GPT-4(V) enable general-purpose conversations about images with the language modality. As off-the-shelf MLLMs may have limited capabilities on images from domains like dermatology and agriculture, they must be fine-tuned to unlock domain-specific applications. The prevalent architecture of current open-source MLLMs comprises two major modules: an image-language (cross-modal) projection network and a large language model. It is desirable to understand the roles of these two modules in modeling domain-specific visual attributes to inform the design of future models and streamline the interpretability efforts on the current models. To this end, via experiments on 4 datasets and under 2 fine-tuning settings, we find that as the MLLM is fine-tuned, it indeed gains domain-specific visual capabilities, but the updates do not lead to the projection extracting relevant domain-specific visual attributes. Our results indicate that the domain-specific visual attributes are modeled by the LLM, even when only the projection is fine-tuned. Through this study, we offer a potential reinterpretation of the role of cross-modal projections in MLLM architectures. Projection webpage: https://claws-lab.github.io/projection-in-MLLMs/
MM-Soc: Benchmarking Multimodal Large Language Models in Social Media Platforms
Feb 21, 2024



Social media platforms are hubs for multimodal information exchange, encompassing text, images, and videos, making it challenging for machines to comprehend the information or emotions associated with interactions in online spaces. Multimodal Large Language Models (MLLMs) have emerged as a promising solution to address these challenges, yet struggle with accurately interpreting human emotions and complex contents like misinformation. This paper introduces MM-Soc, a comprehensive benchmark designed to evaluate MLLMs' understanding of multimodal social media content. MM-Soc compiles prominent multimodal datasets and incorporates a novel large-scale YouTube tagging dataset, targeting a range of tasks from misinformation detection, hate speech detection, and social context generation. Through our exhaustive evaluation on ten size-variants of four open-source MLLMs, we have identified significant performance disparities, highlighting the need for advancements in models' social understanding capabilities. Our analysis reveals that, in a zero-shot setting, various types of MLLMs generally exhibit difficulties in handling social media tasks. However, MLLMs demonstrate performance improvements post fine-tuning, suggesting potential pathways for improvement.
Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries
Oct 23, 2023Large language models (LLMs) are transforming the ways the general public accesses and consumes information. Their influence is particularly pronounced in pivotal sectors like healthcare, where lay individuals are increasingly appropriating LLMs as conversational agents for everyday queries. While LLMs demonstrate impressive language understanding and generation proficiencies, concerns regarding their safety remain paramount in these high-stake domains. Moreover, the development of LLMs is disproportionately focused on English. It remains unclear how these LLMs perform in the context of non-English languages, a gap that is critical for ensuring equity in the real-world use of these systems.This paper provides a framework to investigate the effectiveness of LLMs as multi-lingual dialogue systems for healthcare queries. Our empirically-derived framework XlingEval focuses on three fundamental criteria for evaluating LLM responses to naturalistic human-authored health-related questions: correctness, consistency, and verifiability. Through extensive experiments on four major global languages, including English, Spanish, Chinese, and Hindi, spanning three expert-annotated large health Q&A datasets, and through an amalgamation of algorithmic and human-evaluation strategies, we found a pronounced disparity in LLM responses across these languages, indicating a need for enhanced cross-lingual capabilities. We further propose XlingHealth, a cross-lingual benchmark for examining the multilingual capabilities of LLMs in the healthcare context. Our findings underscore the pressing need to bolster the cross-lingual capacities of these models, and to provide an equitable information ecosystem accessible to all.