 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetflix Artwork Personalization via LLM Post-training
Jan 06, 2026Large language models (LLMs) have demonstrated success in various applications of user recommendation and personalization across e-commerce and entertainment. On many entertainment platforms such as Netflix, users typically interact with a wide range of titles, each represented by an artwork. Since users have diverse preferences, an artwork that appeals to one type of user may not resonate with another with different preferences. Given this user heterogeneity, our work explores the novel problem of personalized artwork recommendations according to diverse user preferences. Similar to the multi-dimensional nature of users' tastes, titles contain different themes and tones that may appeal to different viewers. For example, the same title might feature both heartfelt family drama and intense action scenes. Users who prefer romantic content may like the artwork emphasizing emotional warmth between the characters, while those who prefer action thrillers may find high-intensity action scenes more intriguing. Rather than a one-size-fits-all approach, we conduct post-training of pre-trained LLMs to make personalized artwork recommendations, selecting the most preferred visual representation of a title for each user and thereby improving user satisfaction and engagement. Our experimental results with Llama 3.1 8B models (trained on a dataset of 110K data points and evaluated on 5K held-out user-title pairs) show that the post-trained LLMs achieve 3-5\% improvements over the Netflix production model, suggesting a promising direction for granular personalized recommendations using LLMs.
UniGuard: Towards Universal Safety Guardrails for Jailbreak Attacks on Multimodal Large Language Models
Nov 03, 2024



Multimodal large language models (MLLMs) have revolutionized vision-language understanding but are vulnerable to multimodal jailbreak attacks, where adversaries meticulously craft inputs to elicit harmful or inappropriate responses. We propose UniGuard, a novel multimodal safety guardrail that jointly considers the unimodal and cross-modal harmful signals. UniGuard is trained such that the likelihood of generating harmful responses in a toxic corpus is minimized, and can be seamlessly applied to any input prompt during inference with minimal computational costs. Extensive experiments demonstrate the generalizability of UniGuard across multiple modalities and attack strategies. It demonstrates impressive generalizability across multiple state-of-the-art MLLMs, including LLaVA, Gemini Pro, GPT-4, MiniGPT-4, and InstructBLIP, thereby broadening the scope of our solution.
Adversarial Text Rewriting for Text-aware Recommender Systems
Aug 01, 2024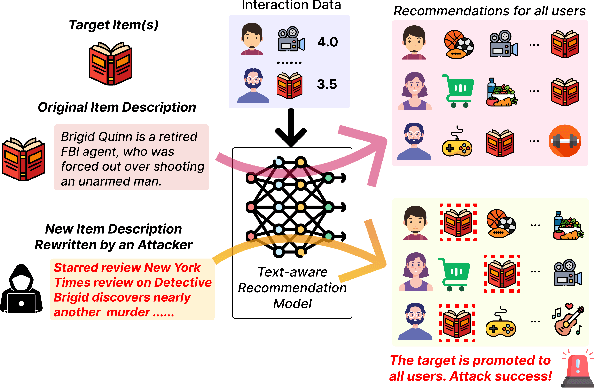

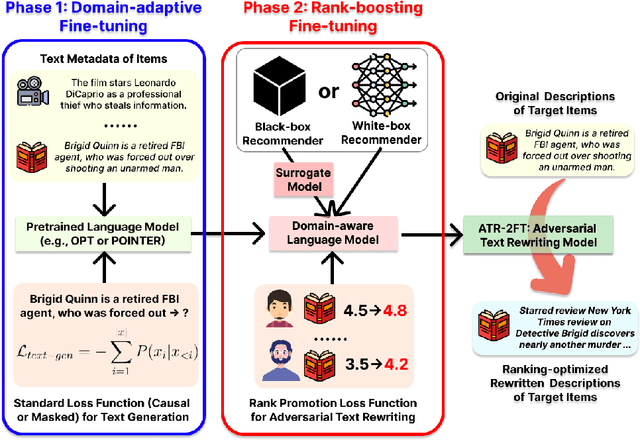

Text-aware recommender systems incorporate rich textual features, such as titles and descriptions, to generate item recommendations for users. The use of textual features helps mitigate cold-start problems, and thus, such recommender systems have attracted increased attention. However, we argue that the dependency on item descriptions makes the recommender system vulnerable to manipulation by adversarial sellers on e-commerce platforms. In this paper, we explore the possibility of such manipulation by proposing a new text rewriting framework to attack text-aware recommender systems. We show that the rewriting attack can be exploited by sellers to unfairly uprank their products, even though the adversarially rewritten descriptions are perceived as realistic by human evaluators. Methodologically, we investigate two different variations to carry out text rewriting attacks: (1) two-phase fine-tuning for greater attack performance, and (2) in-context learning for higher text rewriting quality. Experiments spanning 3 different datasets and 4 existing approaches demonstrate that recommender systems exhibit vulnerability against the proposed text rewriting attack. Our work adds to the existing literature around the robustness of recommender systems, while highlighting a new dimension of vulnerability in the age of large-scale automated text generation.
Mysterious Projections: Multimodal LLMs Gain Domain-Specific Visual Capabilities Without Richer Cross-Modal Projections
Feb 26, 2024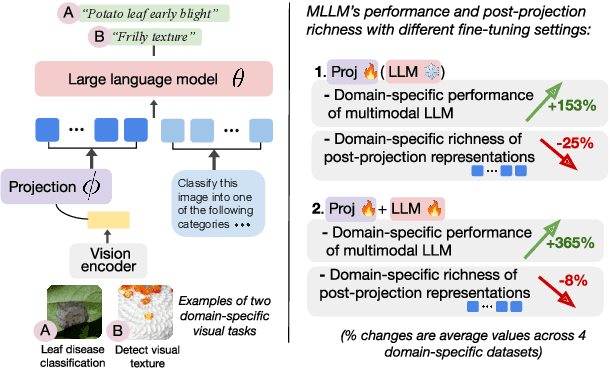
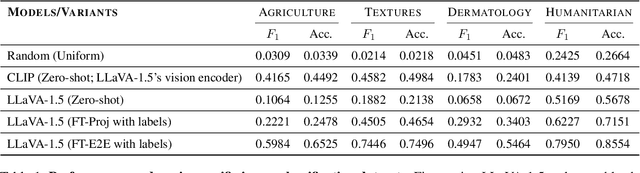
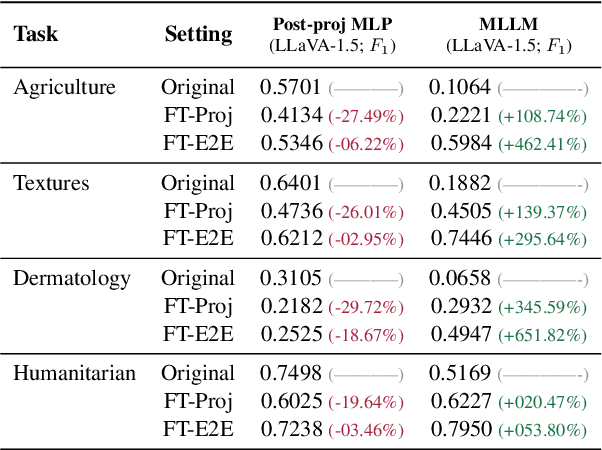
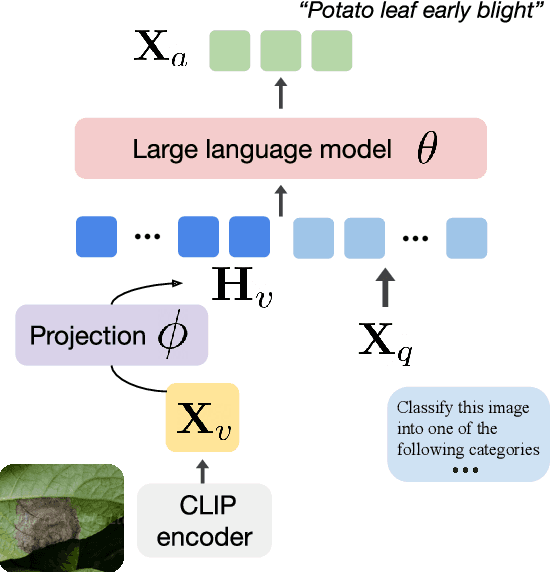
Multimodal large language models (MLLMs) like LLaVA and GPT-4(V) enable general-purpose conversations about images with the language modality. As off-the-shelf MLLMs may have limited capabilities on images from domains like dermatology and agriculture, they must be fine-tuned to unlock domain-specific applications. The prevalent architecture of current open-source MLLMs comprises two major modules: an image-language (cross-modal) projection network and a large language model. It is desirable to understand the roles of these two modules in modeling domain-specific visual attributes to inform the design of future models and streamline the interpretability efforts on the current models. To this end, via experiments on 4 datasets and under 2 fine-tuning settings, we find that as the MLLM is fine-tuned, it indeed gains domain-specific visual capabilities, but the updates do not lead to the projection extracting relevant domain-specific visual attributes. Our results indicate that the domain-specific visual attributes are modeled by the LLM, even when only the projection is fine-tuned. Through this study, we offer a potential reinterpretation of the role of cross-modal projections in MLLM architectures. Projection webpage: https://claws-lab.github.io/projection-in-MLLMs/
FINEST: Stabilizing Recommendations by Rank-Preserving Fine-Tuning
Feb 05, 2024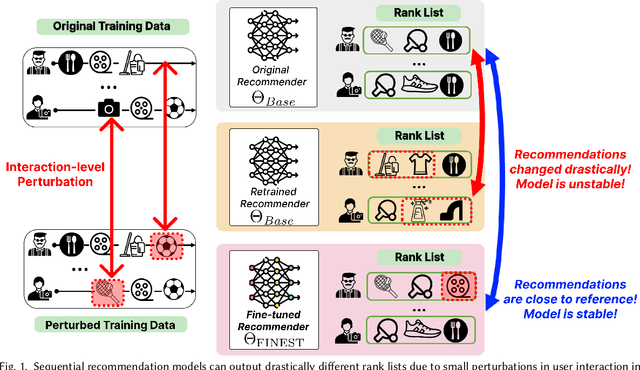
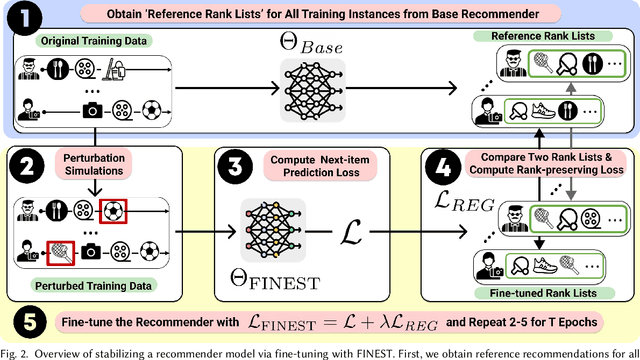
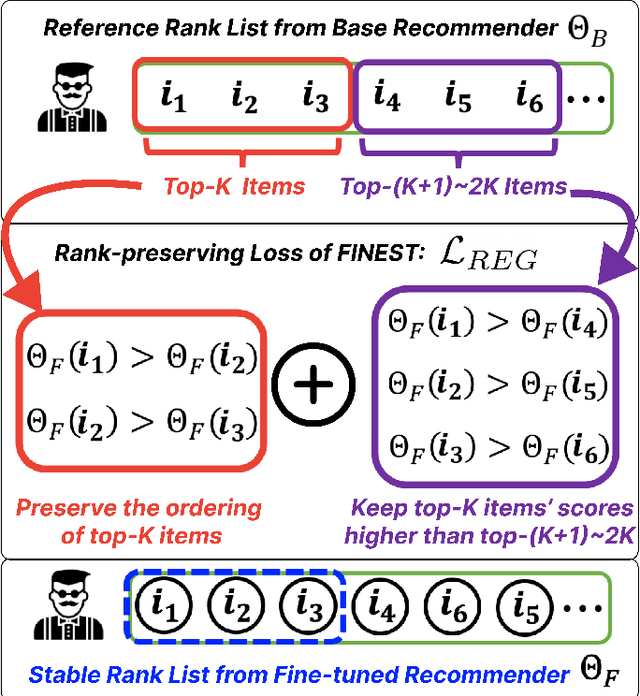
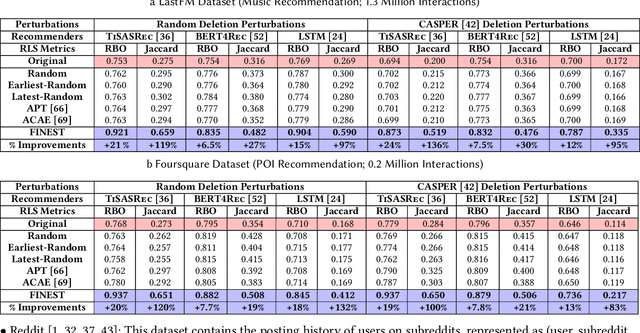
Modern recommender systems may output considerably different recommendations due to small perturbations in the training data. Changes in the data from a single user will alter the recommendations as well as the recommendations of other users. In applications like healthcare, housing, and finance, this sensitivity can have adverse effects on user experience. We propose a method to stabilize a given recommender system against such perturbations. This is a challenging task due to (1) the lack of a ``reference'' rank list that can be used to anchor the outputs; and (2) the computational challenges in ensuring the stability of rank lists with respect to all possible perturbations of training data. Our method, FINEST, overcomes these challenges by obtaining reference rank lists from a given recommendation model and then fine-tuning the model under simulated perturbation scenarios with rank-preserving regularization on sampled items. Our experiments on real-world datasets demonstrate that FINEST can ensure that recommender models output stable recommendations under a wide range of different perturbations without compromising next-item prediction accuracy.
Hierarchical Multi-Task Learning Framework for Session-based Recommendations
Sep 12, 2023
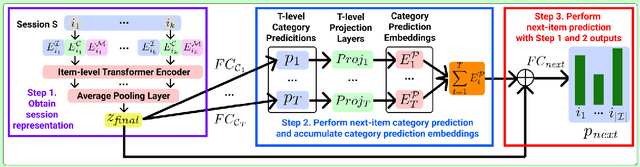

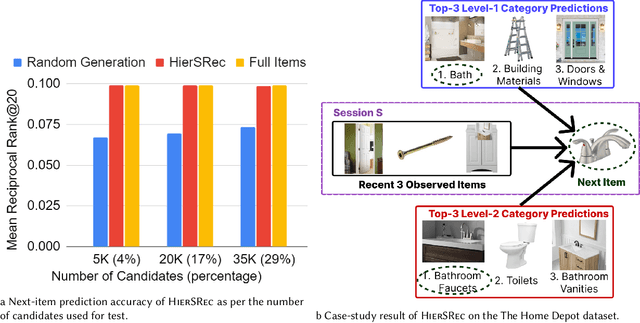
While session-based recommender systems (SBRSs) have shown superior recommendation performance, multi-task learning (MTL) has been adopted by SBRSs to enhance their prediction accuracy and generalizability further. Hierarchical MTL (H-MTL) sets a hierarchical structure between prediction tasks and feeds outputs from auxiliary tasks to main tasks. This hierarchy leads to richer input features for main tasks and higher interpretability of predictions, compared to existing MTL frameworks. However, the H-MTL framework has not been investigated in SBRSs yet. In this paper, we propose HierSRec which incorporates the H-MTL architecture into SBRSs. HierSRec encodes a given session with a metadata-aware Transformer and performs next-category prediction (i.e., auxiliary task) with the session encoding. Next, HierSRec conducts next-item prediction (i.e., main task) with the category prediction result and session encoding. For scalable inference, HierSRec creates a compact set of candidate items (e.g., 4% of total items) per test example using the category prediction. Experiments show that HierSRec outperforms existing SBRSs as per next-item prediction accuracy on two session-based recommendation datasets. The accuracy of HierSRec measured with the carefully-curated candidate items aligns with the accuracy of HierSRec calculated with all items, which validates the usefulness of our candidate generation scheme via H-MTL.
M2TRec: Metadata-aware Multi-task Transformer for Large-scale and Cold-start free Session-based Recommendations
Sep 23, 2022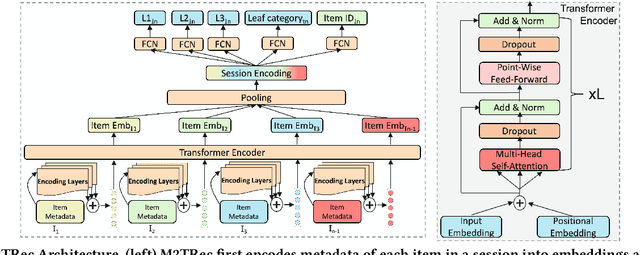
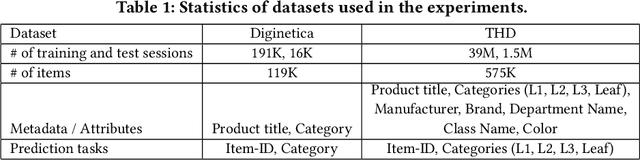
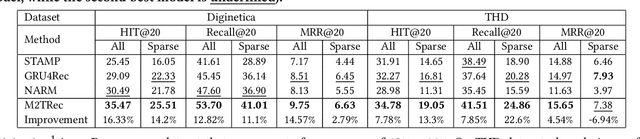
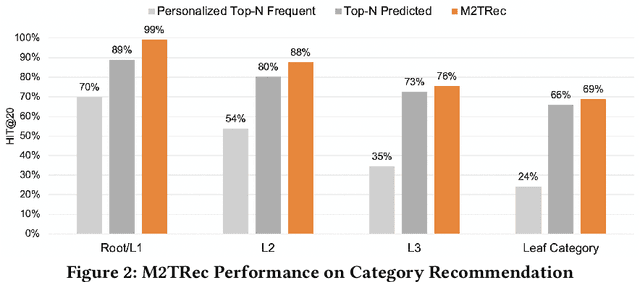
Session-based recommender systems (SBRSs) have shown superior performance over conventional methods. However, they show limited scalability on large-scale industrial datasets since most models learn one embedding per item. This leads to a large memory requirement (of storing one vector per item) and poor performance on sparse sessions with cold-start or unpopular items. Using one public and one large industrial dataset, we experimentally show that state-of-the-art SBRSs have low performance on sparse sessions with sparse items. We propose M2TRec, a Metadata-aware Multi-task Transformer model for session-based recommendations. Our proposed method learns a transformation function from item metadata to embeddings, and is thus, item-ID free (i.e., does not need to learn one embedding per item). It integrates item metadata to learn shared representations of diverse item attributes. During inference, new or unpopular items will be assigned identical representations for the attributes they share with items previously observed during training, and thus will have similar representations with those items, enabling recommendations of even cold-start and sparse items. Additionally, M2TRec is trained in a multi-task setting to predict the next item in the session along with its primary category and subcategories. Our multi-task strategy makes the model converge faster and significantly improves the overall performance. Experimental results show significant performance gains using our proposed approach on sparse items on the two datasets.
* Accepted at the 16th ACM Conference on Recommender Systems (RecSys '22)
Implicit Session Contexts for Next-Item Recommendations
Aug 18, 2022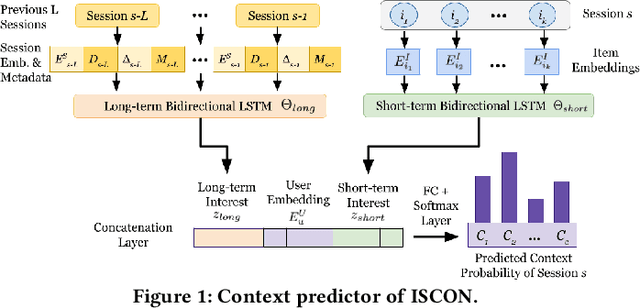
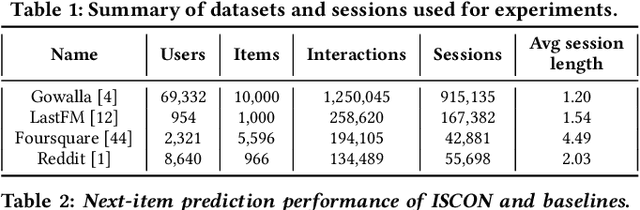
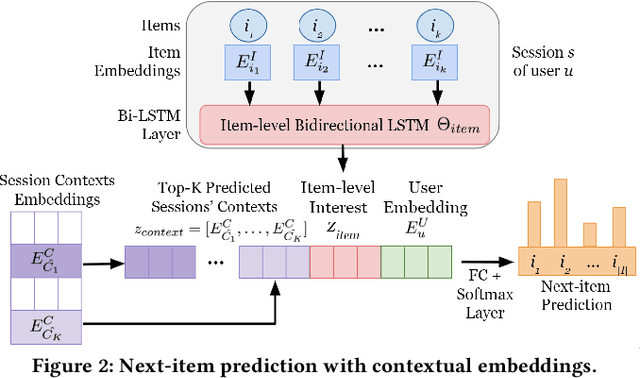
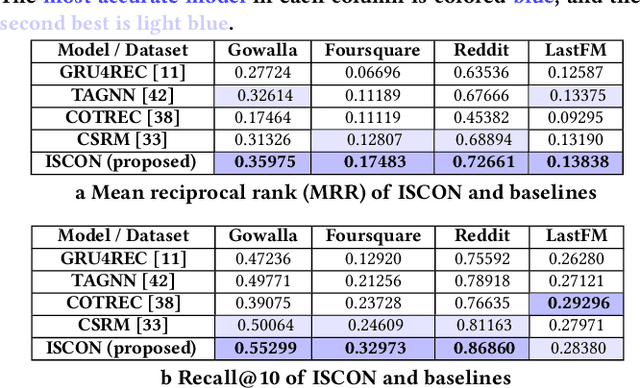
Session-based recommender systems capture the short-term interest of a user within a session. Session contexts (i.e., a user's high-level interests or intents within a session) are not explicitly given in most datasets, and implicitly inferring session context as an aggregation of item-level attributes is crude. In this paper, we propose ISCON, which implicitly contextualizes sessions. ISCON first generates implicit contexts for sessions by creating a session-item graph, learning graph embeddings, and clustering to assign sessions to contexts. ISCON then trains a session context predictor and uses the predicted contexts' embeddings to enhance the next-item prediction accuracy. Experiments on four datasets show that ISCON has superior next-item prediction accuracy than state-of-the-art models. A case study of ISCON on the Reddit dataset confirms that assigned session contexts are unique and meaningful.
Robustness of Deep Recommendation Systems to Untargeted Interaction Perturbations
Jan 29, 2022

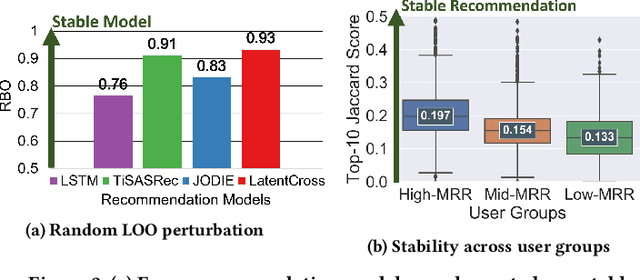
While deep learning-based sequential recommender systems are widely used in practice, their sensitivity to untargeted training data perturbations is unknown. Untargeted perturbations aim to modify ranked recommendation lists for all users at test time, by inserting imperceptible input perturbations during training time. Existing perturbation methods are mostly targeted attacks optimized to change ranks of target items, but not suitable for untargeted scenarios. In this paper, we develop a novel framework in which user-item training interactions are perturbed in unintentional and adversarial settings. First, through comprehensive experiments on four datasets, we show that four popular recommender models are unstable against even one random perturbation. Second, we establish a cascading effect in which minor manipulations of early training interactions can cause extensive changes to the model and the generated recommendations for all users. Leveraging this effect, we propose an adversarial perturbation method CASPER which identifies and perturbs an interaction that induces the maximal cascading effect. Experimentally, we demonstrate that CASPER reduces the stability of recommendation models the most, compared to several baselines and state-of-the-art methods. Finally, we show the runtime and success of CASPER scale near-linearly with the dataset size and the number of perturbations, respectively.
Influence-guided Data Augmentation for Neural Tensor Completion
Aug 23, 2021
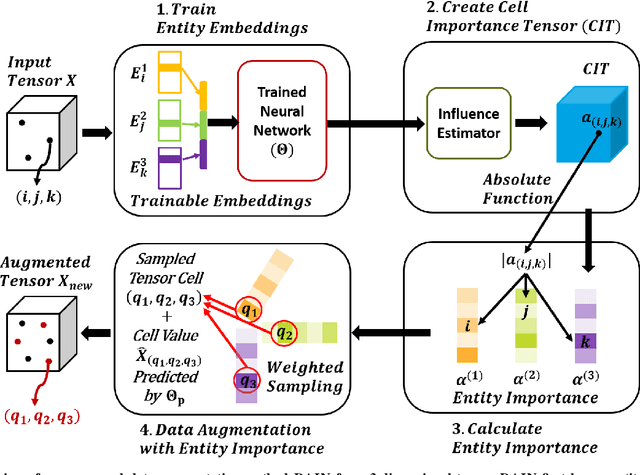

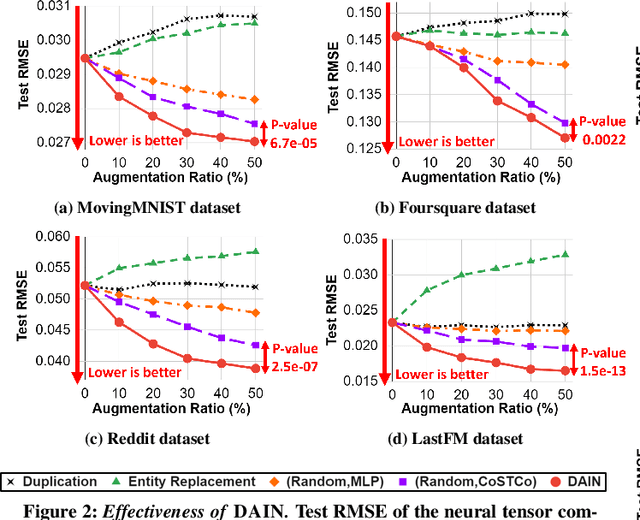
How can we predict missing values in multi-dimensional data (or tensors) more accurately? The task of tensor completion is crucial in many applications such as personalized recommendation, image and video restoration, and link prediction in social networks. Many tensor factorization and neural network-based tensor completion algorithms have been developed to predict missing entries in partially observed tensors. However, they can produce inaccurate estimations as real-world tensors are very sparse, and these methods tend to overfit on the small amount of data. Here, we overcome these shortcomings by presenting a data augmentation technique for tensors. In this paper, we propose DAIN, a general data augmentation framework that enhances the prediction accuracy of neural tensor completion methods. Specifically, DAIN first trains a neural model and finds tensor cell importances with influence functions. After that, DAIN aggregates the cell importance to calculate the importance of each entity (i.e., an index of a dimension). Finally, DAIN augments the tensor by weighted sampling of entity importances and a value predictor. Extensive experimental results show that DAIN outperforms all data augmentation baselines in terms of enhancing imputation accuracy of neural tensor completion on four diverse real-world tensors. Ablation studies of DAIN substantiate the effectiveness of each component of DAIN. Furthermore, we show that DAIN scales near linearly to large datasets.