 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Deep-Learning-Based Early Warning System for Deadly Heatwave Prediction
Dec 09, 2025Severe heatwaves in urban areas significantly threaten public health, calling for establishing early warning strategies. Despite predicting occurrence of heatwaves and attributing historical mortality, predicting an incoming deadly heatwave remains a challenge due to the difficulty in defining and estimating heat-related mortality. Furthermore, establishing an early warning system imposes additional requirements, including data availability, spatial and temporal robustness, and decision costs. To address these challenges, we propose DeepTherm, a modular early warning system for deadly heatwave prediction without requiring heat-related mortality history. By highlighting the flexibility of deep learning, DeepTherm employs a dual-prediction pipeline, disentangling baseline mortality in the absence of heatwaves and other irregular events from all-cause mortality. We evaluated DeepTherm on real-world data across Spain. Results demonstrate consistent, robust, and accurate performance across diverse regions, time periods, and population groups while allowing trade-off between missed alarms and false alarms.
Who Gets Heard? Rethinking Fairness in AI for Music Systems
Nov 08, 2025In recent years, the music research community has examined risks of AI models for music, with generative AI models in particular, raised concerns about copyright, deepfakes, and transparency. In our work, we raise concerns about cultural and genre biases in AI for music systems (music-AI systems) which affect stakeholders including creators, distributors, and listeners shaping representation in AI for music. These biases can misrepresent marginalized traditions, especially from the Global South, producing inauthentic outputs (e.g., distorted ragas) that reduces creators' trust on these systems. Such harms risk reinforcing biases, limiting creativity, and contributing to cultural erasure. To address this, we offer recommendations at dataset, model and interface level in music-AI systems.
UniGuard: Towards Universal Safety Guardrails for Jailbreak Attacks on Multimodal Large Language Models
Nov 03, 2024



Multimodal large language models (MLLMs) have revolutionized vision-language understanding but are vulnerable to multimodal jailbreak attacks, where adversaries meticulously craft inputs to elicit harmful or inappropriate responses. We propose UniGuard, a novel multimodal safety guardrail that jointly considers the unimodal and cross-modal harmful signals. UniGuard is trained such that the likelihood of generating harmful responses in a toxic corpus is minimized, and can be seamlessly applied to any input prompt during inference with minimal computational costs. Extensive experiments demonstrate the generalizability of UniGuard across multiple modalities and attack strategies. It demonstrates impressive generalizability across multiple state-of-the-art MLLMs, including LLaVA, Gemini Pro, GPT-4, MiniGPT-4, and InstructBLIP, thereby broadening the scope of our solution.
M2M-Gen: A Multimodal Framework for Automated Background Music Generation in Japanese Manga Using Large Language Models
Oct 13, 2024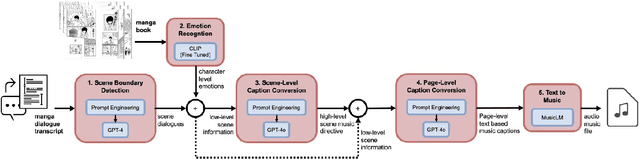

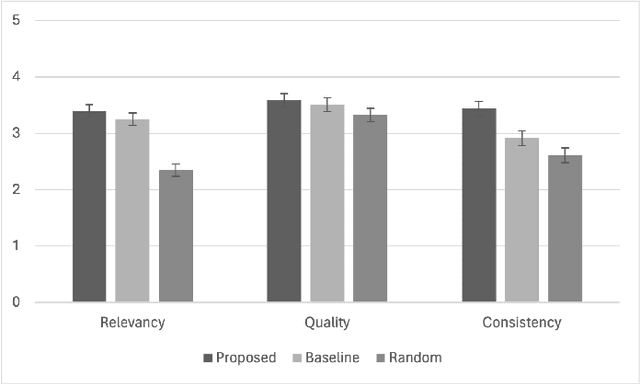
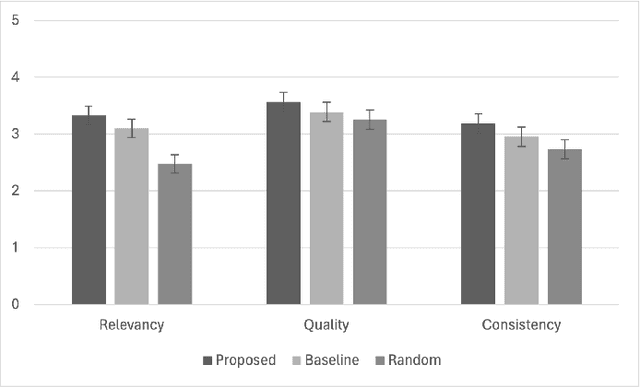
This paper introduces M2M Gen, a multi modal framework for generating background music tailored to Japanese manga. The key challenges in this task are the lack of an available dataset or a baseline. To address these challenges, we propose an automated music generation pipeline that produces background music for an input manga book. Initially, we use the dialogues in a manga to detect scene boundaries and perform emotion classification using the characters faces within a scene. Then, we use GPT4o to translate this low level scene information into a high level music directive. Conditioned on the scene information and the music directive, another instance of GPT 4o generates page level music captions to guide a text to music model. This produces music that is aligned with the mangas evolving narrative. The effectiveness of M2M Gen is confirmed through extensive subjective evaluations, showcasing its capability to generate higher quality, more relevant and consistent music that complements specific scenes when compared to our baselines.
Foundation Models for Music: A Survey
Aug 27, 2024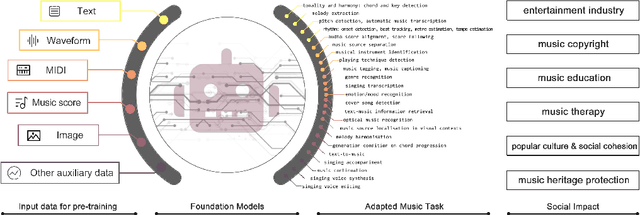

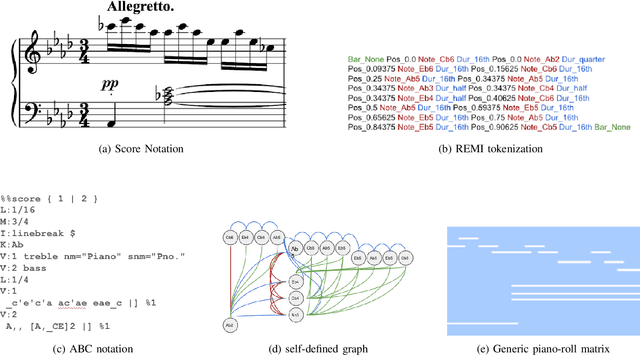
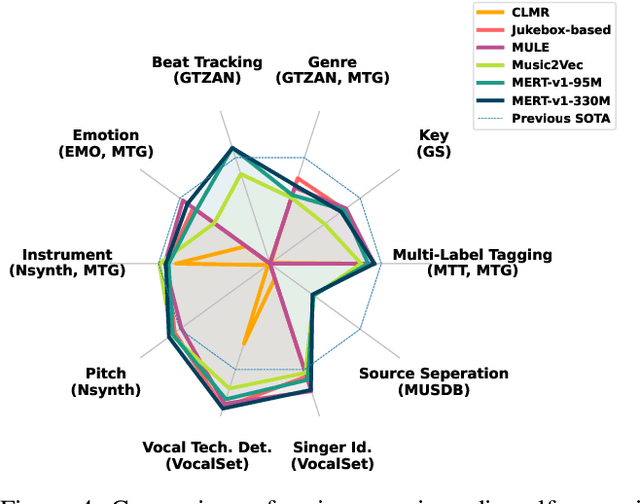
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Time-MMD: A New Multi-Domain Multimodal Dataset for Time Series Analysis
Jun 12, 2024



Time series data are ubiquitous across a wide range of real-world domains. While real-world time series analysis (TSA) requires human experts to integrate numerical series data with multimodal domain-specific knowledge, most existing TSA models rely solely on numerical data, overlooking the significance of information beyond numerical series. This oversight is due to the untapped potential of textual series data and the absence of a comprehensive, high-quality multimodal dataset. To overcome this obstacle, we introduce Time-MMD, the first multi-domain, multimodal time series dataset covering 9 primary data domains. Time-MMD ensures fine-grained modality alignment, eliminates data contamination, and provides high usability. Additionally, we develop MM-TSFlib, the first multimodal time-series forecasting (TSF) library, seamlessly pipelining multimodal TSF evaluations based on Time-MMD for in-depth analyses. Extensive experiments conducted on Time-MMD through MM-TSFlib demonstrate significant performance enhancements by extending unimodal TSF to multimodality, evidenced by over 15% mean squared error reduction in general, and up to 40% in domains with rich textual data. More importantly, our datasets and library revolutionize broader applications, impacts, research topics to advance TSA. The dataset and library are available at https://github.com/AdityaLab/Time-MMD and https://github.com/AdityaLab/MM-TSFlib.