 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Two-stage Diffusion TTS: Joint Structure and Content Refinement via Jump Diffusion
Mar 14, 2026Diffusion and flow matching TTS faces a tension between discrete temporal structure and continuous spectral modeling. Two-stage models diffuse on fixed alignments, often collapsing to mean prosody; single-stage models avoid explicit durations but suffer alignment instability. We propose a jump-diffusion framework where discrete jumps model temporal structure and continuous diffusion refines spectral content within one process. Even in its one-shot degenerate form, our framework achieves 3.37% WER vs. 4.38% for Grad-TTS with improved UTMOSv2 on LJSpeech. The full iterative UDD variant further enables adaptive prosody, autonomously inserting natural pauses in out-of-distribution slow speech rather than stretching uniformly. Audio samples are available at https://anonymousinterpseech.github.io/TTS_Demo/.
Beyond the Utterance: An Empirical Study of Very Long Context Speech Recognition
Feb 04, 2026Automatic speech recognition (ASR) models are normally trained to operate over single utterances, with a short duration of less than 30 seconds. This choice has been made in part due to computational constraints, but also reflects a common, but often inaccurate, modelling assumption that treats utterances as independent and identically distributed samples. When long-format audio recordings are available, to work with such systems, these recordings must first be segmented into short utterances and processed independently. In this work, we show that due to recent algorithmic and hardware advances, this is no longer necessary, and current attention-based approaches can be used to train ASR systems that operate on sequences of over an hour in length. Therefore, to gain a better understanding of the relationship between the training/evaluation sequence length and performance, we train ASR models on large-scale data using 10 different sequence lengths from 10 seconds up to 1 hour. The results show a benefit from using up to 21.8 minutes of context, with up to a 14.2% relative improvement from a short context baseline in our primary experiments. Through modifying various architectural components, we find that the method of encoding positional information and the model's width/depth are important factors when working with long sequences. Finally, a series of evaluations using synthetic data are constructed to help analyse the model's use of context. From these results, it is clear that both linguistic and acoustic aspects of the distant context are being used by the model.
Decoding Order Matters in Autoregressive Speech Synthesis
Jan 13, 2026Autoregressive speech synthesis often adopts a left-to-right order, yet generation order is a modelling choice. We investigate decoding order through masked diffusion framework, which progressively unmasks positions and allows arbitrary decoding orders during training and inference. By interpolating between identity and random permutations, we show that randomness in decoding order affects speech quality. We further compare fixed strategies, such as \texttt{l2r} and \texttt{r2l} with adaptive ones, such as Top-$K$, finding that fixed-order decoding, including the dominating left-to-right approach, is suboptimal, while adaptive decoding yields better performance. Finally, since masked diffusion requires discrete inputs, we quantise acoustic representations and find that even 1-bit quantisation can support reasonably high-quality speech.
How I Built ASR for Endangered Languages with a Spoken Dictionary
Oct 06, 2025


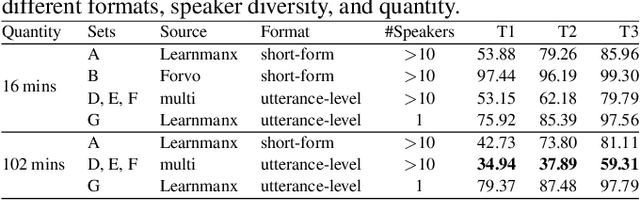
Nearly half of the world's languages are endangered. Speech technologies such as Automatic Speech Recognition (ASR) are central to revival efforts, yet most languages remain unsupported because standard pipelines expect utterance-level supervised data. Speech data often exist for endangered languages but rarely match these formats. Manx Gaelic ($\sim$2,200 speakers), for example, has had transcribed speech since 1948, yet remains unsupported by modern systems. In this paper, we explore how little data, and in what form, is needed to build ASR for critically endangered languages. We show that a short-form pronunciation resource is a viable alternative, and that 40 minutes of such data produces usable ASR for Manx ($<$50\% WER). We replicate our approach, applying it to Cornish ($\sim$600 speakers), another critically endangered language. Results show that the barrier to entry, in quantity and form, is far lower than previously thought, giving hope to endangered language communities that cannot afford to meet the requirements arbitrarily imposed upon them.
Score-Based Training for Energy-Based TTS Models
May 19, 2025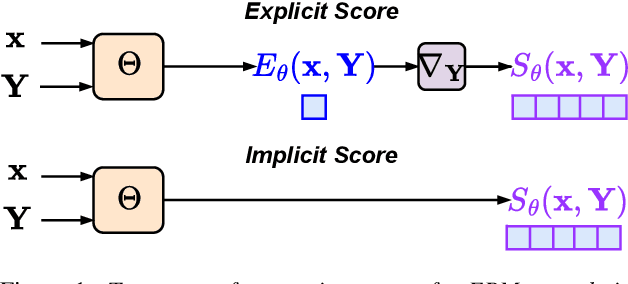



Noise contrastive estimation (NCE) is a popular method for training energy-based models (EBM) with intractable normalisation terms. The key idea of NCE is to learn by comparing unnormalised log-likelihoods of the reference and noisy samples, thus avoiding explicitly computing normalisation terms. However, NCE critically relies on the quality of noisy samples. Recently, sliced score matching (SSM) has been popularised by closely related diffusion models (DM). Unlike NCE, SSM learns a gradient of log-likelihood, or score, by learning distribution of its projections on randomly chosen directions. However, both NCE and SSM disregard the form of log-likelihood function, which is problematic given that EBMs and DMs make use of first-order optimisation during inference. This paper proposes a new criterion that learns scores more suitable for first-order schemes. Experiments contrasts these approaches for training EBMs.
VisualSpeech: Enhance Prosody with Visual Context in TTS
Jan 31, 2025



Text-to-Speech (TTS) synthesis faces the inherent challenge of producing multiple speech outputs with varying prosody from a single text input. While previous research has addressed this by predicting prosodic information from both text and speech, additional contextual information, such as visual features, remains underutilized. This paper investigates the potential of integrating visual context to enhance prosody prediction. We propose a novel model, VisualSpeech, which incorporates both visual and textual information for improved prosody generation. Empirical results demonstrate that visual features provide valuable prosodic cues beyond the textual input, significantly enhancing the naturalness and accuracy of the synthesized speech. Audio samples are available at https://ariameetgit.github.io/VISUALSPEECH-SAMPLES/.
What happens to diffusion model likelihood when your model is conditional?
Sep 10, 2024



Diffusion Models (DMs) iteratively denoise random samples to produce high-quality data. The iterative sampling process is derived from Stochastic Differential Equations (SDEs), allowing a speed-quality trade-off chosen at inference. Another advantage of sampling with differential equations is exact likelihood computation. These likelihoods have been used to rank unconditional DMs and for out-of-domain classification. Despite the many existing and possible uses of DM likelihoods, the distinct properties captured are unknown, especially in conditional contexts such as Text-To-Image (TTI) or Text-To-Speech synthesis (TTS). Surprisingly, we find that TTS DM likelihoods are agnostic to the text input. TTI likelihood is more expressive but cannot discern confounding prompts. Our results show that applying DMs to conditional tasks reveals inconsistencies and strengthens claims that the properties of DM likelihood are unknown. This impact sheds light on the previously unknown nature of DM likelihoods. Although conditional DMs maximise likelihood, the likelihood in question is not as sensitive to the conditioning input as one expects. This investigation provides a new point-of-view on diffusion likelihoods.
Foundation Models for Music: A Survey
Aug 27, 2024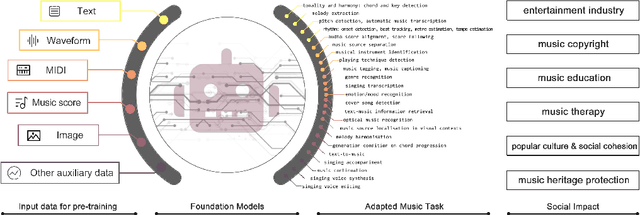

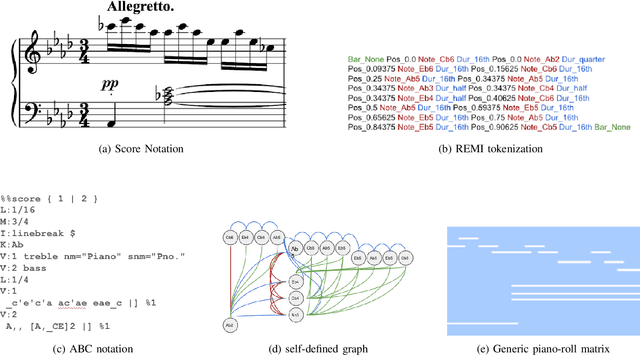
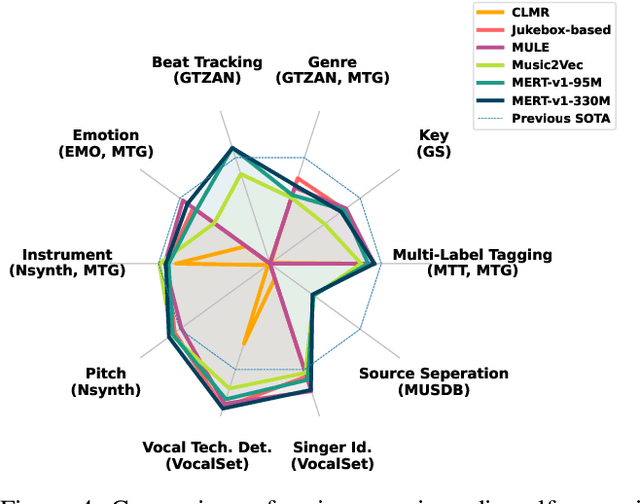
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Self-Train Before You Transcribe
Jun 17, 2024



When there is a mismatch between the training and test domains, current speech recognition systems show significant performance degradation. Self-training methods, such as noisy student teacher training, can help address this and enable the adaptation of models under such domain shifts. However, self-training typically requires a collection of unlabelled target domain data. For settings where this is not practical, we investigate the benefit of performing noisy student teacher training on recordings in the test set as a test-time adaptation approach. Similarly to the dynamic evaluation approach in language modelling, this enables the transfer of information across utterance boundaries and functions as a method of domain adaptation. A range of in-domain and out-of-domain datasets are used for experiments demonstrating large relative gains of up to 32.2%. Interestingly, our method showed larger gains than the typical self-training setup that utilises separate adaptation data.
Training Data Augmentation for Dysarthric Automatic Speech Recognition by Text-to-Dysarthric-Speech Synthesis
Jun 12, 2024
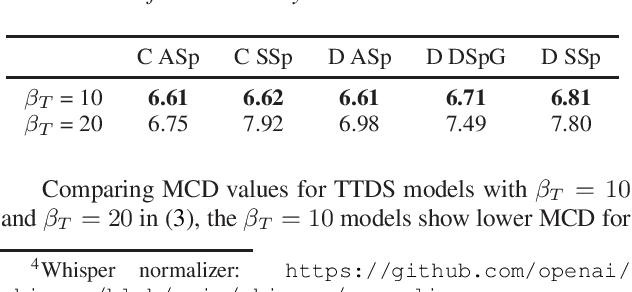
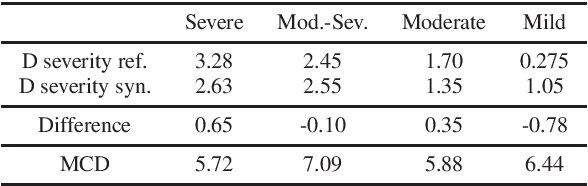
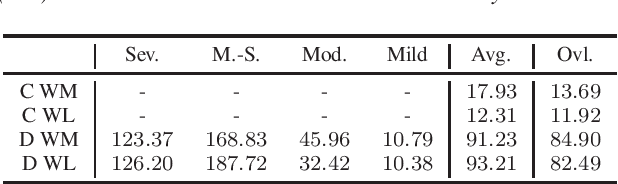
Automatic speech recognition (ASR) research has achieved impressive performance in recent years and has significant potential for enabling access for people with dysarthria (PwD) in augmentative and alternative communication (AAC) and home environment systems. However, progress in dysarthric ASR (DASR) has been limited by high variability in dysarthric speech and limited public availability of dysarthric training data. This paper demonstrates that data augmentation using text-to-dysarthic-speech (TTDS) synthesis for finetuning large ASR models is effective for DASR. Specifically, diffusion-based text-to-speech (TTS) models can produce speech samples similar to dysarthric speech that can be used as additional training data for fine-tuning ASR foundation models, in this case Whisper. Results show improved synthesis metrics and ASR performance for the proposed multi-speaker diffusion-based TTDS data augmentation for ASR fine-tuning compared to current DASR baselines.