 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Speech Foundational Models in Loss Functions for Hearing Aid Speech Enhancement
Jul 18, 2024Machine learning techniques are an active area of research for speech enhancement for hearing aids, with one particular focus on improving the intelligibility of a noisy speech signal. Recent work has shown that feature encodings from self-supervised speech representation models can effectively capture speech intelligibility. In this work, it is shown that the distance between self-supervised speech representations of clean and noisy speech correlates more strongly with human intelligibility ratings than other signal-based metrics. Experiments show that training a speech enhancement model using this distance as part of a loss function improves the performance over using an SNR-based loss function, demonstrated by an increase in HASPI, STOI, PESQ and SI-SNR scores. This method takes inference of a high parameter count model only at training time, meaning the speech enhancement model can remain smaller, as is required for hearing aids.
Transcription-Free Fine-Tuning of Speech Separation Models for Noisy and Reverberant Multi-Speaker Automatic Speech Recognition
Jun 13, 2024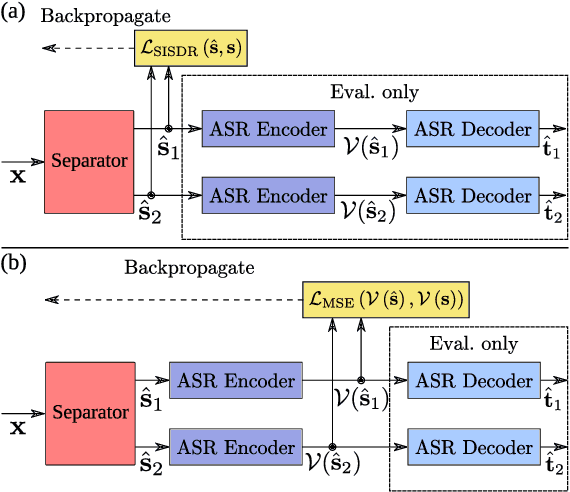

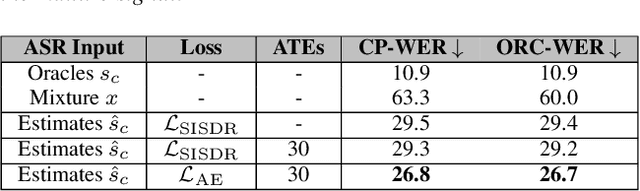
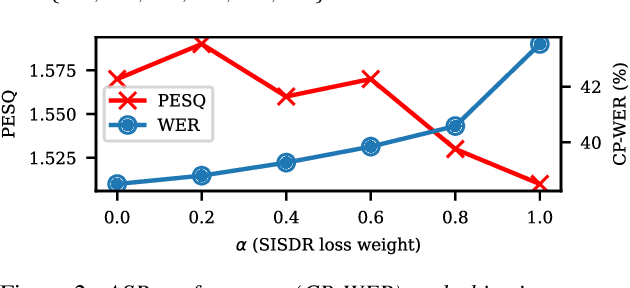
One solution to automatic speech recognition (ASR) of overlapping speakers is to separate speech and then perform ASR on the separated signals. Commonly, the separator produces artefacts which often degrade ASR performance. Addressing this issue typically requires reference transcriptions to jointly train the separation and ASR networks. This is often not viable for training on real-world in-domain audio where reference transcript information is not always available. This paper proposes a transcription-free method for joint training using only audio signals. The proposed method uses embedding differences of pre-trained ASR encoders as a loss with a proposed modification to permutation invariant training (PIT) called guided PIT (GPIT). The method achieves a 6.4% improvement in word error rate (WER) measures over a signal-level loss and also shows enhancement improvements in perceptual measures such as short-time objective intelligibility (STOI).
Hallucination in Perceptual Metric-Driven Speech Enhancement Networks
Mar 18, 2024



Within the area of speech enhancement, there is an ongoing interest in the creation of neural systems which explicitly aim to improve the perceptual quality of the processed audio. In concert with this is the topic of non-intrusive (i.e. without clean reference) speech quality prediction, for which neural networks are trained to predict human-assigned quality labels directly from distorted audio. When combined, these areas allow for the creation of powerful new speech enhancement systems which can leverage large real-world datasets of distorted audio, by taking inference of a pre-trained speech quality predictor as the sole loss function of the speech enhancement system. This paper aims to identify a potential pitfall with this approach, namely hallucinations which are introduced by the enhancement system `tricking' the speech quality predictor.
Non-Intrusive Speech Intelligibility Prediction for Hearing-Impaired Users using Intermediate ASR Features and Human Memory Models
Jan 24, 2024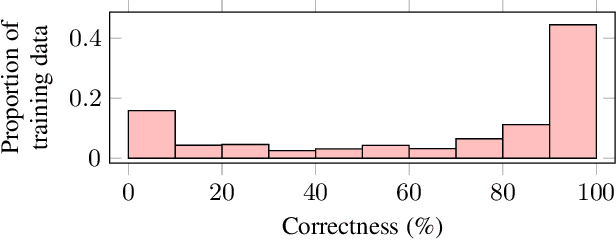
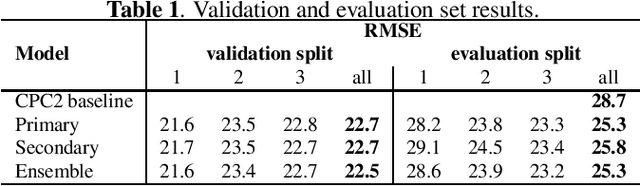
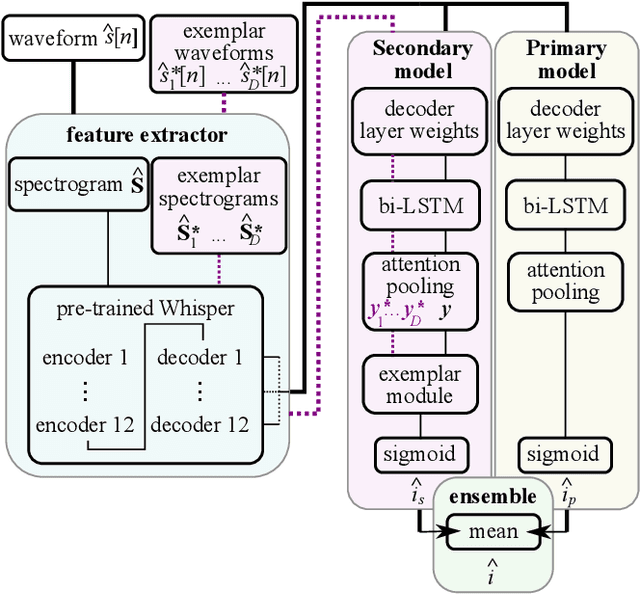
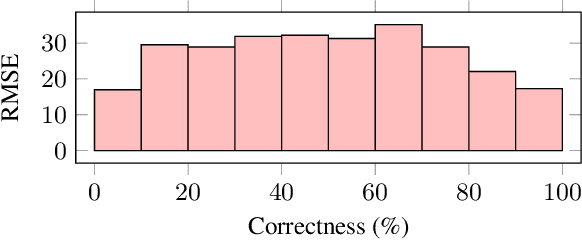
Neural networks have been successfully used for non-intrusive speech intelligibility prediction. Recently, the use of feature representations sourced from intermediate layers of pre-trained self-supervised and weakly-supervised models has been found to be particularly useful for this task. This work combines the use of Whisper ASR decoder layer representations as neural network input features with an exemplar-based, psychologically motivated model of human memory to predict human intelligibility ratings for hearing-aid users. Substantial performance improvement over an established intrusive HASPI baseline system is found, including on enhancement systems and listeners unseen in the training data, with a root mean squared error of 25.3 compared with the baseline of 28.7.
Multi-CMGAN+/+: Leveraging Multi-Objective Speech Quality Metric Prediction for Speech Enhancement
Dec 14, 2023

Neural network based approaches to speech enhancement have shown to be particularly powerful, being able to leverage a data-driven approach to result in a significant performance gain versus other approaches. Such approaches are reliant on artificially created labelled training data such that the neural model can be trained using intrusive loss functions which compare the output of the model with clean reference speech. Performance of such systems when enhancing real-world audio often suffers relative to their performance on simulated test data. In this work, a non-intrusive multi-metric prediction approach is introduced, wherein a model trained on artificial labelled data using inference of an adversarially trained metric prediction neural network. The proposed approach shows improved performance versus state-of-the-art systems on the recent CHiME-7 challenge \ac{UDASE} task evaluation sets.
Non Intrusive Intelligibility Predictor for Hearing Impaired Individuals using Self Supervised Speech Representations
Jul 27, 2023



Self-supervised speech representations (SSSRs) have been successfully applied to a number of speech-processing tasks, e.g. as feature extractor for speech quality (SQ) prediction, which is, in turn, relevant for assessment and training speech enhancement systems for users with normal or impaired hearing. However, exact knowledge of why and how quality-related information is encoded well in such representations remains poorly understood. In this work, techniques for non-intrusive prediction of SQ ratings are extended to the prediction of intelligibility for hearing-impaired users. It is found that self-supervised representations are useful as input features to non-intrusive prediction models, achieving competitive performance to more complex systems. A detailed analysis of the performance depending on Clarity Prediction Challenge 1 listeners and enhancement systems indicates that more data might be needed to allow generalisation to unknown systems and (hearing-impaired) individuals
The Effect of Spoken Language on Speech Enhancement using Self-Supervised Speech Representation Loss Functions
Jul 27, 2023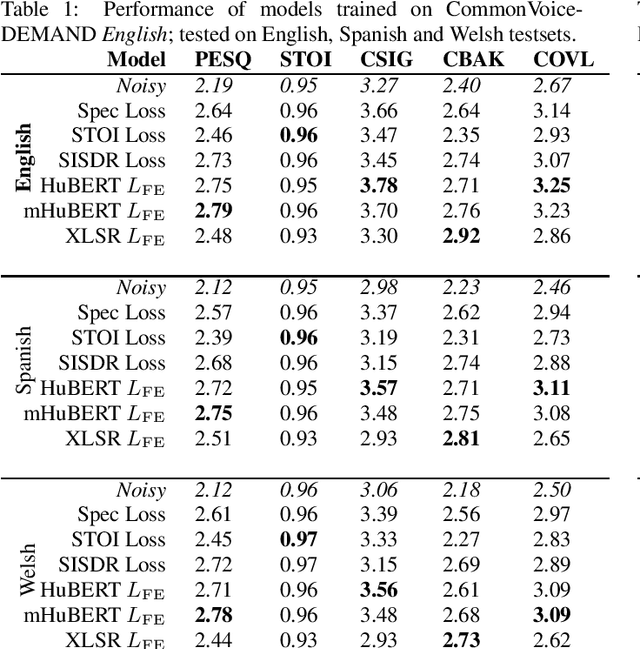
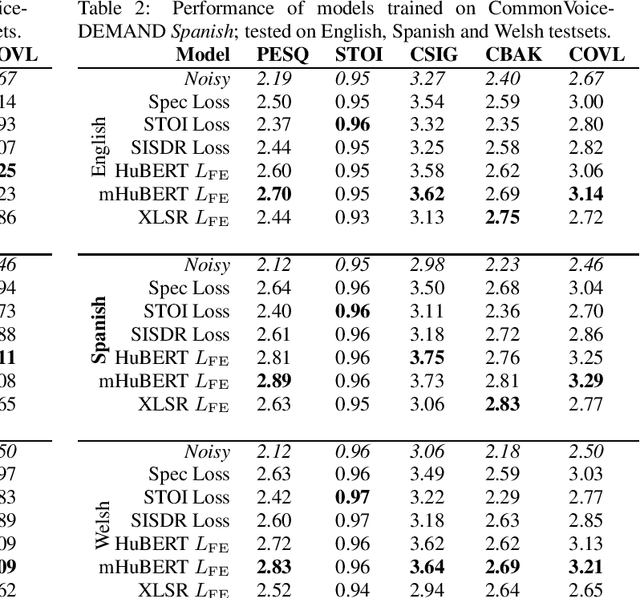
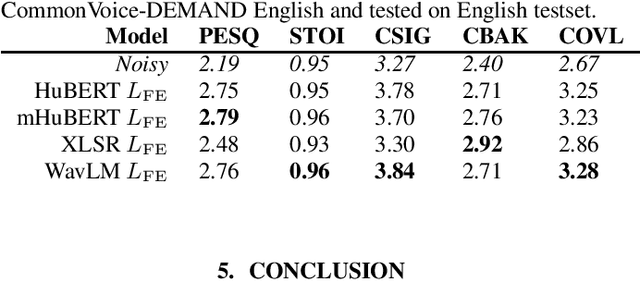
Recent work in the field of speech enhancement (SE) has involved the use of self-supervised speech representations (SSSRs) as feature transformations in loss functions. However, in prior work, very little attention has been paid to the relationship between the language of the audio used to train the self-supervised representation and that used to train the SE system. Enhancement models trained using a loss function which incorporates a self-supervised representation that shares exactly the language of the noisy data used to train the SE system show better performance than those which do not match exactly. This may lead to enhancement systems which are language specific and as such do not generalise well to unseen languages, unlike models trained using traditional spectrogram or time domain loss functions. In this work, SE models are trained and tested on a number of different languages, with self-supervised representations which themselves are trained using different language combinations and with differing network structures as loss function representations. These models are then tested across unseen languages and their performances are analysed. It is found that the training language of the self-supervised representation appears to have a minor effect on enhancement performance, the amount of training data of a particular language, however, greatly affects performance.
Perceive and predict: self-supervised speech representation based loss functions for speech enhancement
Jan 11, 2023



Recent work in the domain of speech enhancement has explored the use of self-supervised speech representations to aid in the training of neural speech enhancement models. However, much of this work focuses on using the deepest or final outputs of self supervised speech representation models, rather than the earlier feature encodings. The use of self supervised representations in such a way is often not fully motivated. In this work it is shown that the distance between the feature encodings of clean and noisy speech correlate strongly with psychoacoustically motivated measures of speech quality and intelligibility, as well as with human Mean Opinion Score (MOS) ratings. Experiments using this distance as a loss function are performed and improved performance over the use of STFT spectrogram distance based loss as well as other common loss functions from speech enhancement literature is demonstrated using objective measures such as perceptual evaluation of speech quality (PESQ) and short-time objective intelligibility (STOI).
MetricGAN+/-: Increasing Robustness of Noise Reduction on Unseen Data
Mar 29, 2022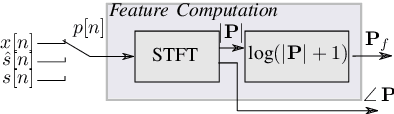

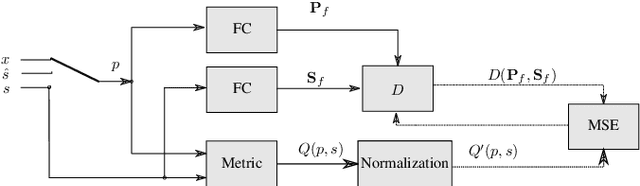

Training of speech enhancement systems often does not incorporate knowledge of human perception and thus can lead to unnatural sounding results. Incorporating psychoacoustically motivated speech perception metrics as part of model training via a predictor network has recently gained interest. However, the performance of such predictors is limited by the distribution of metric scores that appear in the training data. In this work, we propose MetricGAN+/- (an extension of MetricGAN+, one such metric-motivated system) which introduces an additional network - a "de-generator" which attempts to improve the robustness of the prediction network (and by extension of the generator) by ensuring observation of a wider range of metric scores in training. Experimental results on the VoiceBank-DEMAND dataset show relative improvement in PESQ score of 3.8% (3.05 vs 3.22 PESQ score), as well as better generalisation to unseen noise and speech.