 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Confidence Estimation Measures for Speaker Diarization
Jun 24, 2024Speaker diarization systems segment a conversation recording based on the speakers' identity. Such systems can misclassify the speaker of a portion of audio due to a variety of factors, such as speech pattern variation, background noise, and overlapping speech. These errors propagate to, and can adversely affect, downstream systems that rely on the speaker's identity, such as speaker-adapted speech recognition. One of the ways to mitigate these errors is to provide segment-level diarization confidence scores to downstream systems. In this work, we investigate multiple methods for generating diarization confidence scores, including those derived from the original diarization system and those derived from an external model. Our experiments across multiple datasets and diarization systems demonstrate that the most competitive confidence score methods can isolate ~30% of the diarization errors within segments with the lowest ~10% of confidence scores.
Transcription-Free Fine-Tuning of Speech Separation Models for Noisy and Reverberant Multi-Speaker Automatic Speech Recognition
Jun 13, 2024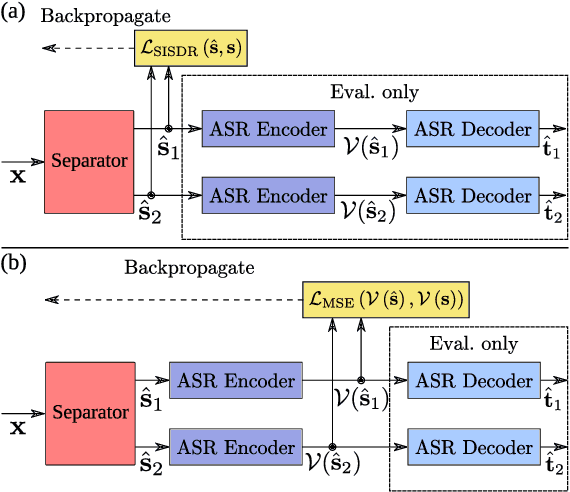

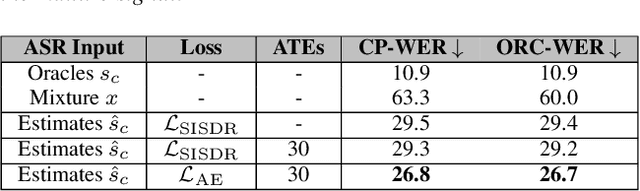
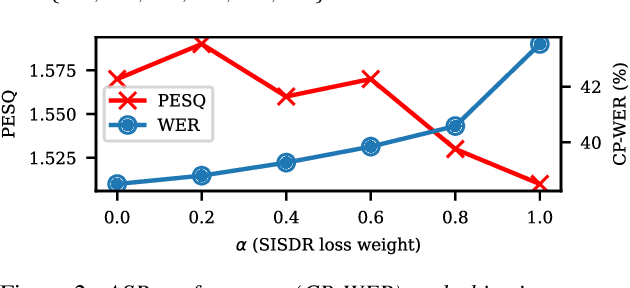
One solution to automatic speech recognition (ASR) of overlapping speakers is to separate speech and then perform ASR on the separated signals. Commonly, the separator produces artefacts which often degrade ASR performance. Addressing this issue typically requires reference transcriptions to jointly train the separation and ASR networks. This is often not viable for training on real-world in-domain audio where reference transcript information is not always available. This paper proposes a transcription-free method for joint training using only audio signals. The proposed method uses embedding differences of pre-trained ASR encoders as a loss with a proposed modification to permutation invariant training (PIT) called guided PIT (GPIT). The method achieves a 6.4% improvement in word error rate (WER) measures over a signal-level loss and also shows enhancement improvements in perceptual measures such as short-time objective intelligibility (STOI).
Voice Morphing: Two Identities in One Voice
Sep 05, 2023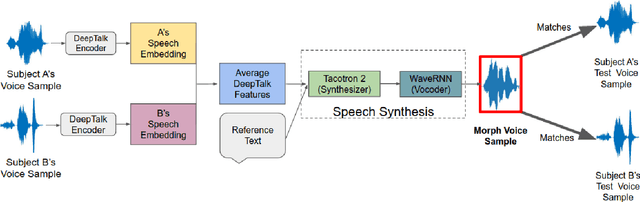
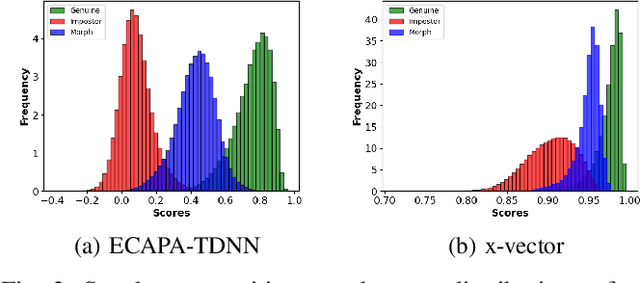
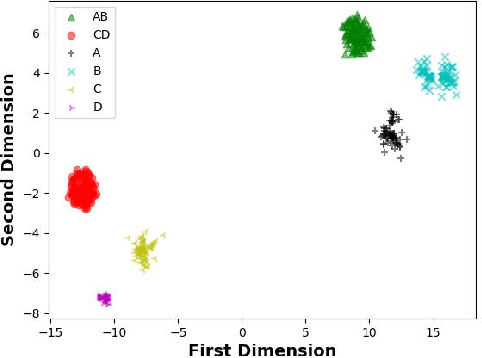
In a biometric system, each biometric sample or template is typically associated with a single identity. However, recent research has demonstrated the possibility of generating "morph" biometric samples that can successfully match more than a single identity. Morph attacks are now recognized as a potential security threat to biometric systems. However, most morph attacks have been studied on biometric modalities operating in the image domain, such as face, fingerprint, and iris. In this preliminary work, we introduce Voice Identity Morphing (VIM) - a voice-based morph attack that can synthesize speech samples that impersonate the voice characteristics of a pair of individuals. Our experiments evaluate the vulnerabilities of two popular speaker recognition systems, ECAPA-TDNN and x-vector, to VIM, with a success rate (MMPMR) of over 80% at a false match rate of 1% on the Librispeech dataset.
DeepTalk: Vocal Style Encoding for Speaker Recognition and Speech Synthesis
Dec 09, 2020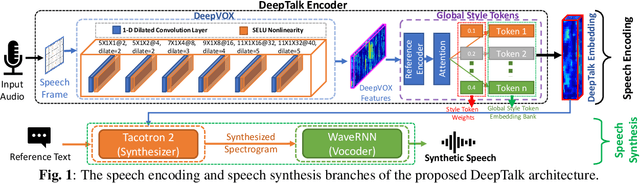
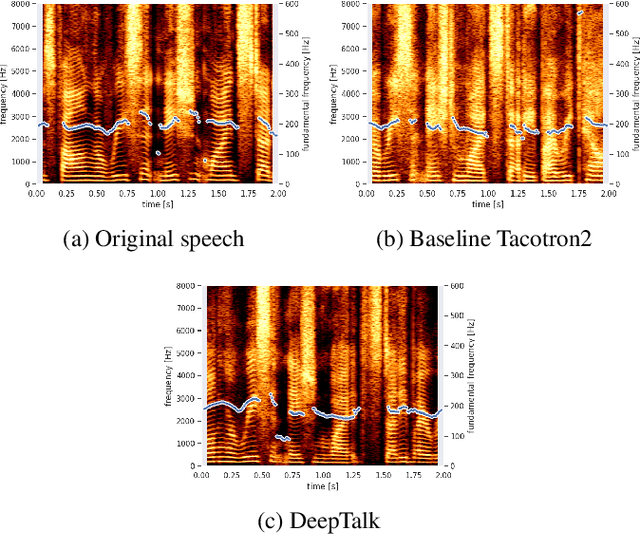
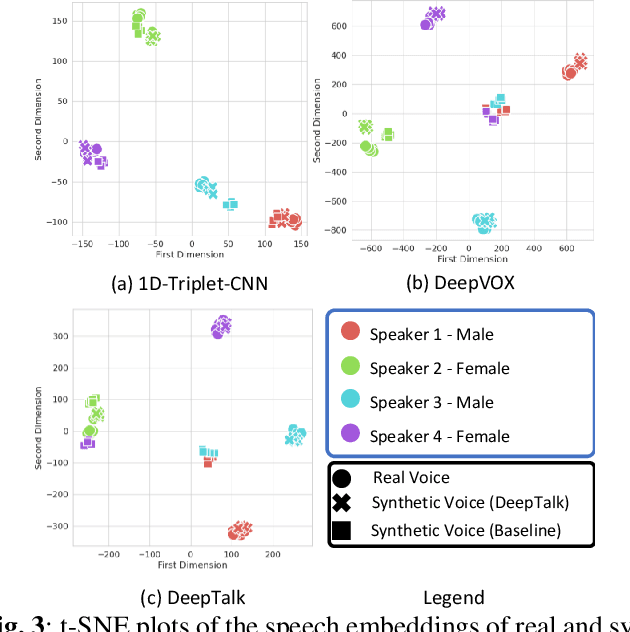
Automatic speaker recognition algorithms typically use physiological speech characteristics encoded in the short term spectral features for characterizing speech audio. Such algorithms do not capitalize on the complementary and discriminative speaker-dependent characteristics present in the behavioral speech features. In this work, we propose a prosody encoding network called DeepTalk for extracting vocal style features directly from raw audio data. The DeepTalk method outperforms several state-of-the-art physiological speech characteristics-based speaker recognition systems across multiple challenging datasets. The speaker recognition performance is further improved by combining DeepTalk with a state-of-the-art physiological speech feature-based speaker recognition system. We also integrate the DeepTalk method into a current state-of-the-art speech synthesizer to generate synthetic speech. A detailed analysis of the synthetic speech shows that the DeepTalk captures F0 contours essential for vocal style modeling. Furthermore, DeepTalk-based synthetic speech is shown to be almost indistinguishable from real speech in the context of speaker recognition.
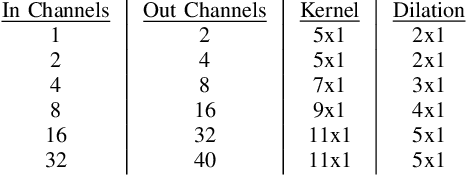
DeepVOX: Discovering Features from Raw Audio for Speaker Recognition in Degraded Audio Signals
Aug 26, 2020
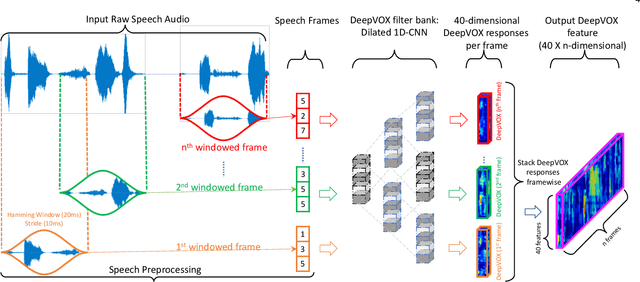
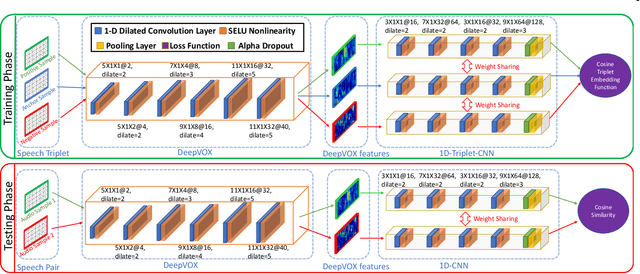

Automatic speaker recognition algorithms typically use pre-defined filterbanks, such as Mel-Frequency and Gammatone filterbanks, for characterizing speech audio. The design of these filterbanks is based on domain-knowledge and limited empirical observations. The resultant features, therefore, may not generalize well to different types of audio degradation. In this work, we propose a deep learning-based technique to induce the filterbank design from vast amounts of speech audio. The purpose of such a filterbank is to extract features robust to degradations in the input audio. To this effect, a 1D convolutional neural network is designed to learn a time-domain filterbank called DeepVOX directly from raw speech audio. Secondly, an adaptive triplet mining technique is developed to efficiently mine the data samples best suited to train the filterbank. Thirdly, a detailed ablation study of the DeepVOX filterbanks reveals the presence of both vocal source and vocal tract characteristics in the extracted features. Experimental results on VOXCeleb2, NIST SRE 2008 and 2010, and Fisher speech datasets demonstrate the efficacy of the DeepVOX features across a variety of audio degradations, multi-lingual speech data, and varying-duration speech audio. The DeepVOX features also improve the performance of existing speaker recognition algorithms, such as the xVector-PLDA and the iVector-PLDA.
JukeBox: A Multilingual Singer Recognition Dataset
Aug 08, 2020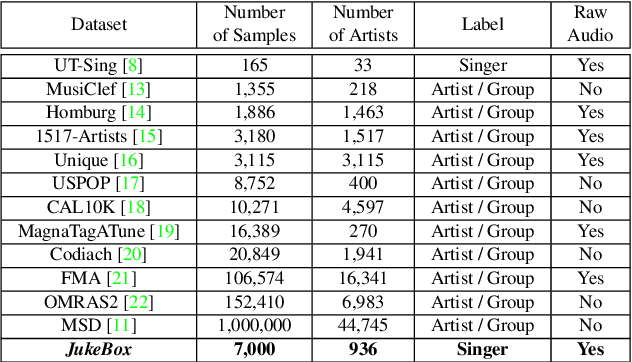
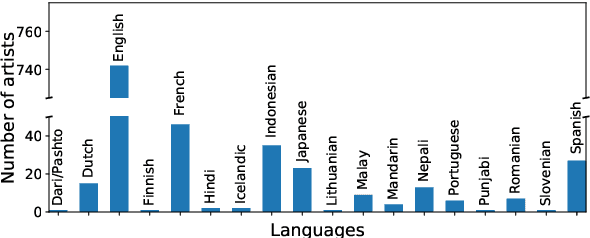
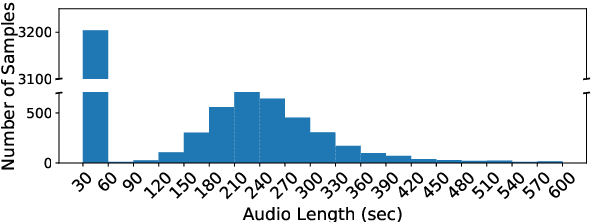
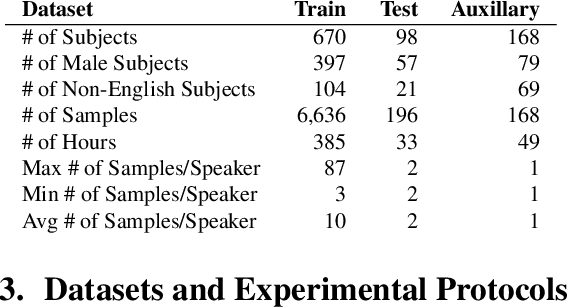
A text-independent speaker recognition system relies on successfully encoding speech factors such as vocal pitch, intensity, and timbre to achieve good performance. A majority of such systems are trained and evaluated using spoken voice or everyday conversational voice data. Spoken voice, however, exhibits a limited range of possible speaker dynamics, thus constraining the utility of the derived speaker recognition models. Singing voice, on the other hand, covers a broader range of vocal and ambient factors and can, therefore, be used to evaluate the robustness of a speaker recognition system. However, a majority of existing speaker recognition datasets only focus on the spoken voice. In comparison, there is a significant shortage of labeled singing voice data suitable for speaker recognition research. To address this issue, we assemble \textit{JukeBox} - a speaker recognition dataset with multilingual singing voice audio annotated with singer identity, gender, and language labels. We use the current state-of-the-art methods to demonstrate the difficulty of performing speaker recognition on singing voice using models trained on spoken voice alone. We also evaluate the effect of gender and language on speaker recognition performance, both in spoken and singing voice data. The complete \textit{JukeBox} dataset can be accessed at http://iprobe.cse.msu.edu/datasets/jukebox.html.
Some Research Problems in Biometrics: The Future Beckons
May 12, 2019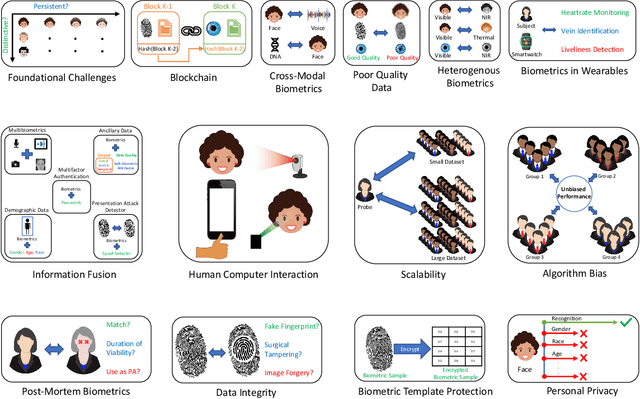

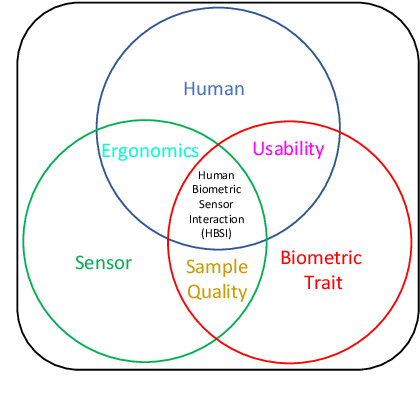
The need for reliably determining the identity of a person is critical in a number of different domains ranging from personal smartphones to border security; from autonomous vehicles to e-voting; from tracking child vaccinations to preventing human trafficking; from crime scene investigation to personalization of customer service. Biometrics, which entails the use of biological attributes such as face, fingerprints and voice for recognizing a person, is being increasingly used in several such applications. While biometric technology has made rapid strides over the past decade, there are several fundamental issues that are yet to be satisfactorily resolved. In this article, we will discuss some of these issues and enumerate some of the exciting challenges in this field.