 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscription-Free Fine-Tuning of Speech Separation Models for Noisy and Reverberant Multi-Speaker Automatic Speech Recognition
Jun 13, 2024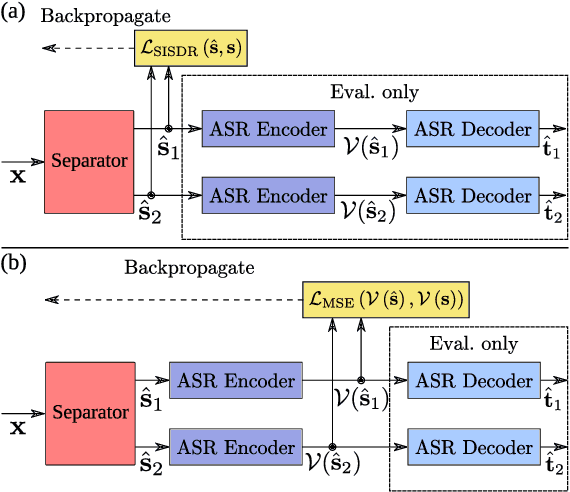

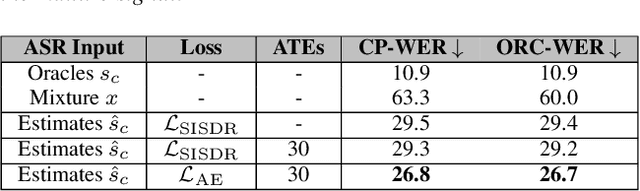
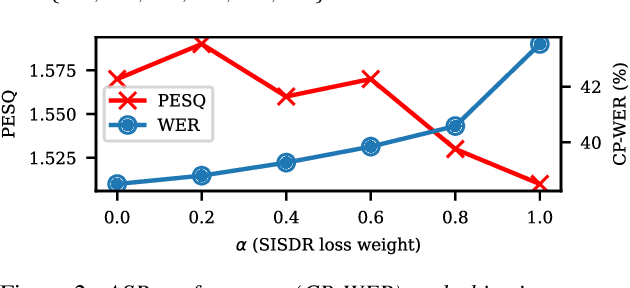
One solution to automatic speech recognition (ASR) of overlapping speakers is to separate speech and then perform ASR on the separated signals. Commonly, the separator produces artefacts which often degrade ASR performance. Addressing this issue typically requires reference transcriptions to jointly train the separation and ASR networks. This is often not viable for training on real-world in-domain audio where reference transcript information is not always available. This paper proposes a transcription-free method for joint training using only audio signals. The proposed method uses embedding differences of pre-trained ASR encoders as a loss with a proposed modification to permutation invariant training (PIT) called guided PIT (GPIT). The method achieves a 6.4% improvement in word error rate (WER) measures over a signal-level loss and also shows enhancement improvements in perceptual measures such as short-time objective intelligibility (STOI).
Multi-CMGAN+/+: Leveraging Multi-Objective Speech Quality Metric Prediction for Speech Enhancement
Dec 14, 2023

Neural network based approaches to speech enhancement have shown to be particularly powerful, being able to leverage a data-driven approach to result in a significant performance gain versus other approaches. Such approaches are reliant on artificially created labelled training data such that the neural model can be trained using intrusive loss functions which compare the output of the model with clean reference speech. Performance of such systems when enhancing real-world audio often suffers relative to their performance on simulated test data. In this work, a non-intrusive multi-metric prediction approach is introduced, wherein a model trained on artificial labelled data using inference of an adversarially trained metric prediction neural network. The proposed approach shows improved performance versus state-of-the-art systems on the recent CHiME-7 challenge \ac{UDASE} task evaluation sets.
On Time Domain Conformer Models for Monaural Speech Separation in Noisy Reverberant Acoustic Environments
Oct 09, 2023



Speech separation remains an important topic for multi-speaker technology researchers. Convolution augmented transformers (conformers) have performed well for many speech processing tasks but have been under-researched for speech separation. Most recent state-of-the-art (SOTA) separation models have been time-domain audio separation networks (TasNets). A number of successful models have made use of dual-path (DP) networks which sequentially process local and global information. Time domain conformers (TD-Conformers) are an analogue of the DP approach in that they also process local and global context sequentially but have a different time complexity function. It is shown that for realistic shorter signal lengths, conformers are more efficient when controlling for feature dimension. Subsampling layers are proposed to further improve computational efficiency. The best TD-Conformer achieves 14.6 dB and 21.2 dB SISDR improvement on the WHAMR and WSJ0-2Mix benchmarks, respectively.
On Data Sampling Strategies for Training Neural Network Speech Separation Models
Apr 14, 2023



Speech separation remains an important area of multi-speaker signal processing. Deep neural network (DNN) models have attained the best performance on many speech separation benchmarks. Some of these models can take significant time to train and have high memory requirements. Previous work has proposed shortening training examples to address these issues but the impact of this on model performance is not yet well understood. In this work, the impact of applying these training signal length (TSL) limits is analysed for two speech separation models: SepFormer, a transformer model, and Conv-TasNet, a convolutional model. The WJS0-2Mix, WHAMR and Libri2Mix datasets are analysed in terms of signal length distribution and its impact on training efficiency. It is demonstrated that, for specific distributions, applying specific TSL limits results in better performance. This is shown to be mainly due to randomly sampling the start index of the waveforms resulting in more unique examples for training. A SepFormer model trained using a TSL limit of 4.42s and dynamic mixing (DM) is shown to match the best-performing SepFormer model trained with DM and unlimited signal lengths. Furthermore, the 4.42s TSL limit results in a 44% reduction in training time with WHAMR.
Perceive and predict: self-supervised speech representation based loss functions for speech enhancement
Jan 11, 2023



Recent work in the domain of speech enhancement has explored the use of self-supervised speech representations to aid in the training of neural speech enhancement models. However, much of this work focuses on using the deepest or final outputs of self supervised speech representation models, rather than the earlier feature encodings. The use of self supervised representations in such a way is often not fully motivated. In this work it is shown that the distance between the feature encodings of clean and noisy speech correlate strongly with psychoacoustically motivated measures of speech quality and intelligibility, as well as with human Mean Opinion Score (MOS) ratings. Experiments using this distance as a loss function are performed and improved performance over the use of STFT spectrogram distance based loss as well as other common loss functions from speech enhancement literature is demonstrated using objective measures such as perceptual evaluation of speech quality (PESQ) and short-time objective intelligibility (STOI).
Deformable Temporal Convolutional Networks for Monaural Noisy Reverberant Speech Separation
Oct 28, 2022
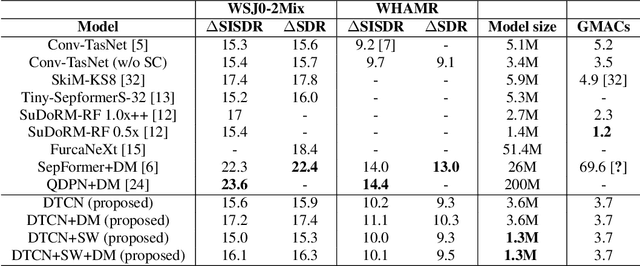
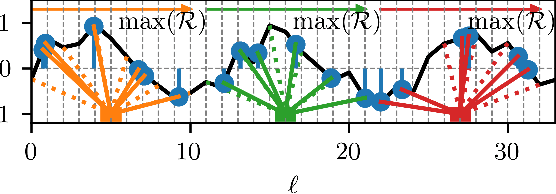

Speech separation models are used for isolating individual speakers in many speech processing applications. Deep learning models have been shown to lead to state-of-the-art (SOTA) results on a number of speech separation benchmarks. One such class of models known as temporal convolutional networks (TCNs) has shown promising results for speech separation tasks. A limitation of these models is that they have a fixed receptive field (RF). Recent research in speech dereverberation has shown that the optimal RF of a TCN varies with the reverberation characteristics of the speech signal. In this work deformable convolution is proposed as a solution to allow TCN models to have dynamic RFs that can adapt to various reverberation times for reverberant speech separation. The proposed models are capable of achieving an 11.1 dB average scale-invariant signal-to-distortion ratio (SISDR) improvement over the input signal on the WHAMR benchmark. A relatively small deformable TCN model of 1.3M parameters is proposed which gives comparable separation performance to larger and more computationally complex models.
Utterance Weighted Multi-Dilation Temporal Convolutional Networks for Monaural Speech Dereverberation
May 17, 2022



Speech dereverberation is an important stage in many speech technology applications. Recent work in this area has been dominated by deep neural network models. Temporal convolutional networks (TCNs) are deep learning models that have been proposed for sequence modelling in the task of dereverberating speech. In this work a weighted multi-dilation depthwise-separable convolution is proposed to replace standard depthwise-separable convolutions in TCN models. This proposed convolution enables the TCN to dynamically focus on more or less local information in its receptive field at each convolutional block in the network. It is shown that this weighted multi-dilation temporal convolutional network (WD-TCN) consistently outperforms the TCN across various model configurations and using the WD-TCN model is a more parameter efficient method to improve the performance of the model than increasing the number of convolutional blocks. The best performance improvement over the baseline TCN is 0.55 dB scale-invariant signal-to-distortion ratio (SISDR) and the best performing WD-TCN model attains 12.26 dB SISDR on the WHAMR dataset.
Receptive Field Analysis of Temporal Convolutional Networks for Monaural Speech Dereverberation
Apr 14, 2022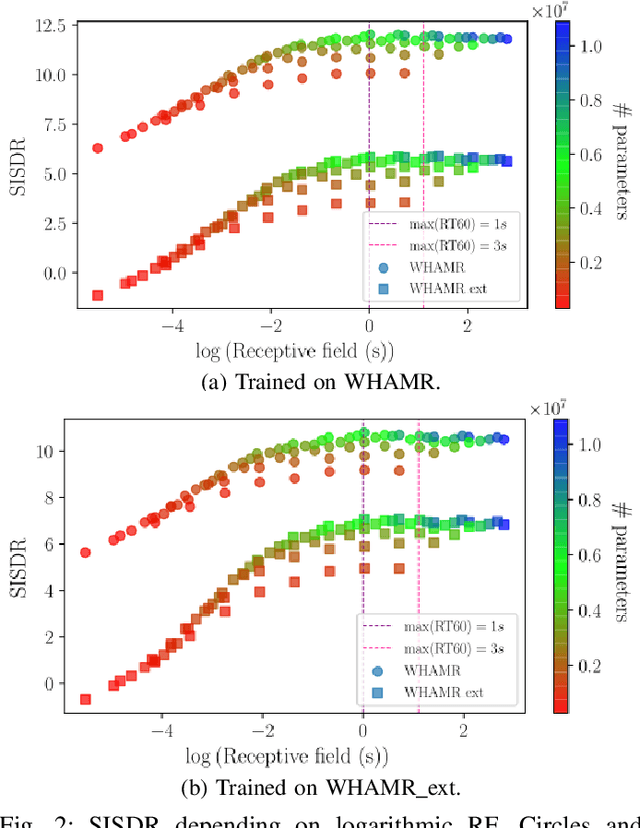



Speech dereverberation is often an important requirement in robust speech processing tasks. Supervised deep learning (DL) models give state-of-the-art performance for single-channel speech dereverberation. Temporal convolutional networks (TCNs) are commonly used for sequence modelling in speech enhancement tasks. A feature of TCNs is that they have a receptive field (RF) dependant on the specific model configuration which determines the number of input frames that can be observed to produce an individual output frame. It has been shown that TCNs are capable of performing dereverberation of simulated speech data, however a thorough analysis, especially with focus on the RF is yet lacking in the literature. This paper analyses dereverberation performance depending on the model size and the RF of TCNs. Experiments using the WHAMR corpus which is extended to include room impulse responses (RIRs) with larger T60 values demonstrate that a larger RF can have significant improvement in performance when training smaller TCN models. It is also demonstrated that TCNs benefit from a wider RF when dereverberating RIRs with larger RT60 values.