 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Confidence Estimation Measures for Speaker Diarization
Jun 24, 2024Speaker diarization systems segment a conversation recording based on the speakers' identity. Such systems can misclassify the speaker of a portion of audio due to a variety of factors, such as speech pattern variation, background noise, and overlapping speech. These errors propagate to, and can adversely affect, downstream systems that rely on the speaker's identity, such as speaker-adapted speech recognition. One of the ways to mitigate these errors is to provide segment-level diarization confidence scores to downstream systems. In this work, we investigate multiple methods for generating diarization confidence scores, including those derived from the original diarization system and those derived from an external model. Our experiments across multiple datasets and diarization systems demonstrate that the most competitive confidence score methods can isolate ~30% of the diarization errors within segments with the lowest ~10% of confidence scores.
Transcription-Free Fine-Tuning of Speech Separation Models for Noisy and Reverberant Multi-Speaker Automatic Speech Recognition
Jun 13, 2024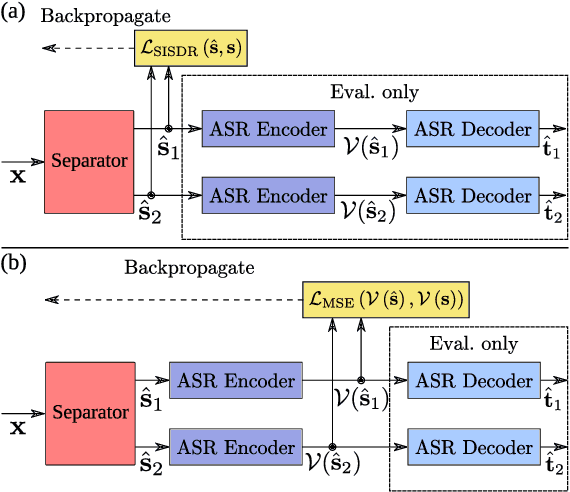

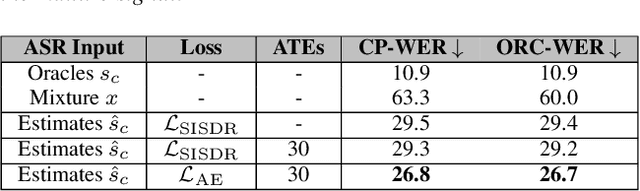
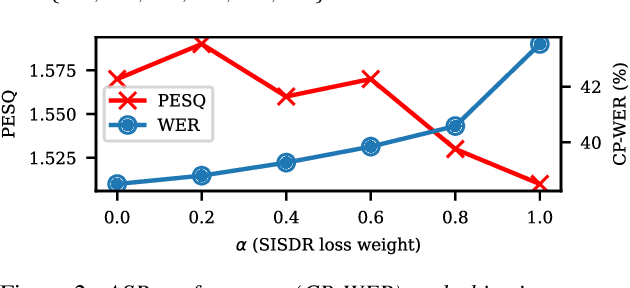
One solution to automatic speech recognition (ASR) of overlapping speakers is to separate speech and then perform ASR on the separated signals. Commonly, the separator produces artefacts which often degrade ASR performance. Addressing this issue typically requires reference transcriptions to jointly train the separation and ASR networks. This is often not viable for training on real-world in-domain audio where reference transcript information is not always available. This paper proposes a transcription-free method for joint training using only audio signals. The proposed method uses embedding differences of pre-trained ASR encoders as a loss with a proposed modification to permutation invariant training (PIT) called guided PIT (GPIT). The method achieves a 6.4% improvement in word error rate (WER) measures over a signal-level loss and also shows enhancement improvements in perceptual measures such as short-time objective intelligibility (STOI).