 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscription-Free Fine-Tuning of Speech Separation Models for Noisy and Reverberant Multi-Speaker Automatic Speech Recognition
Jun 13, 2024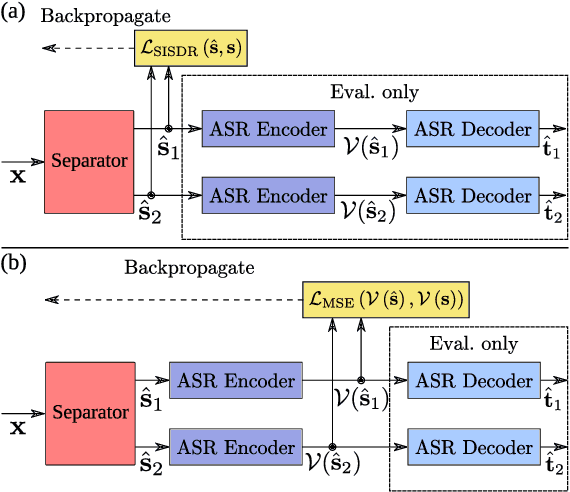

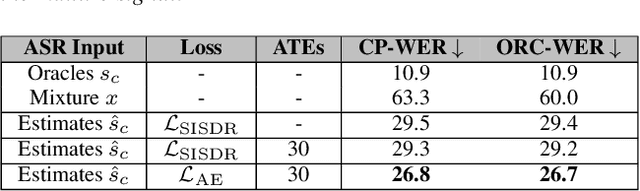
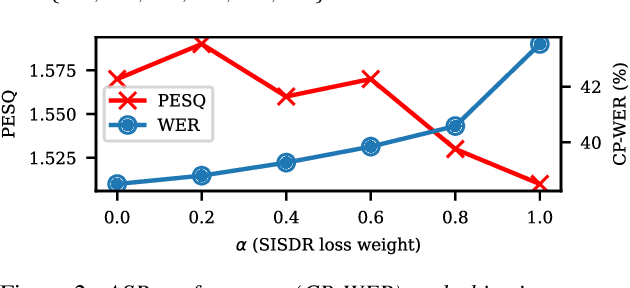
One solution to automatic speech recognition (ASR) of overlapping speakers is to separate speech and then perform ASR on the separated signals. Commonly, the separator produces artefacts which often degrade ASR performance. Addressing this issue typically requires reference transcriptions to jointly train the separation and ASR networks. This is often not viable for training on real-world in-domain audio where reference transcript information is not always available. This paper proposes a transcription-free method for joint training using only audio signals. The proposed method uses embedding differences of pre-trained ASR encoders as a loss with a proposed modification to permutation invariant training (PIT) called guided PIT (GPIT). The method achieves a 6.4% improvement in word error rate (WER) measures over a signal-level loss and also shows enhancement improvements in perceptual measures such as short-time objective intelligibility (STOI).
Accurate synthesis of Dysarthric Speech for ASR data augmentation
Aug 16, 2023Dysarthria is a motor speech disorder often characterized by reduced speech intelligibility through slow, uncoordinated control of speech production muscles. Automatic Speech recognition (ASR) systems can help dysarthric talkers communicate more effectively. However, robust dysarthria-specific ASR requires a significant amount of training speech, which is not readily available for dysarthric talkers. This paper presents a new dysarthric speech synthesis method for the purpose of ASR training data augmentation. Differences in prosodic and acoustic characteristics of dysarthric spontaneous speech at varying severity levels are important components for dysarthric speech modeling, synthesis, and augmentation. For dysarthric speech synthesis, a modified neural multi-talker TTS is implemented by adding a dysarthria severity level coefficient and a pause insertion model to synthesize dysarthric speech for varying severity levels. To evaluate the effectiveness for synthesis of training data for ASR, dysarthria-specific speech recognition was used. Results show that a DNN-HMM model trained on additional synthetic dysarthric speech achieves WER improvement of 12.2% compared to the baseline, and that the addition of the severity level and pause insertion controls decrease WER by 6.5%, showing the effectiveness of adding these parameters. Overall results on the TORGO database demonstrate that using dysarthric synthetic speech to increase the amount of dysarthric-patterned speech for training has significant impact on the dysarthric ASR systems. In addition, we have conducted a subjective evaluation to evaluate the dysarthric-ness and similarity of synthesized speech. Our subjective evaluation shows that the perceived dysartrhic-ness of synthesized speech is similar to that of true dysarthric speech, especially for higher levels of dysarthria
Bilingual Streaming ASR with Grapheme units and Auxiliary Monolingual Loss
Aug 11, 2023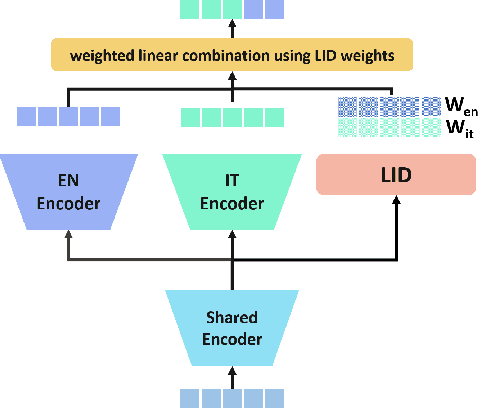


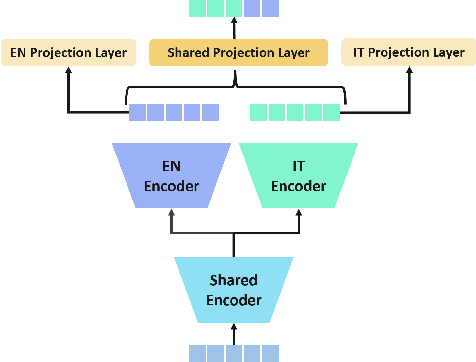
We introduce a bilingual solution to support English as secondary locale for most primary locales in hybrid automatic speech recognition (ASR) settings. Our key developments constitute: (a) pronunciation lexicon with grapheme units instead of phone units, (b) a fully bilingual alignment model and subsequently bilingual streaming transformer model, (c) a parallel encoder structure with language identification (LID) loss, (d) parallel encoder with an auxiliary loss for monolingual projections. We conclude that in comparison to LID loss, our proposed auxiliary loss is superior in specializing the parallel encoders to respective monolingual locales, and that contributes to stronger bilingual learning. We evaluate our work on large-scale training and test tasks for bilingual Spanish (ES) and bilingual Italian (IT) applications. Our bilingual models demonstrate strong English code-mixing capability. In particular, the bilingual IT model improves the word error rate (WER) for a code-mix IT task from 46.5% to 13.8%, while also achieving a close parity (9.6%) with the monolingual IT model (9.5%) over IT tests.
Synthesizing Dysarthric Speech Using Multi-talker TTS for Dysarthric Speech Recognition
Jan 27, 2022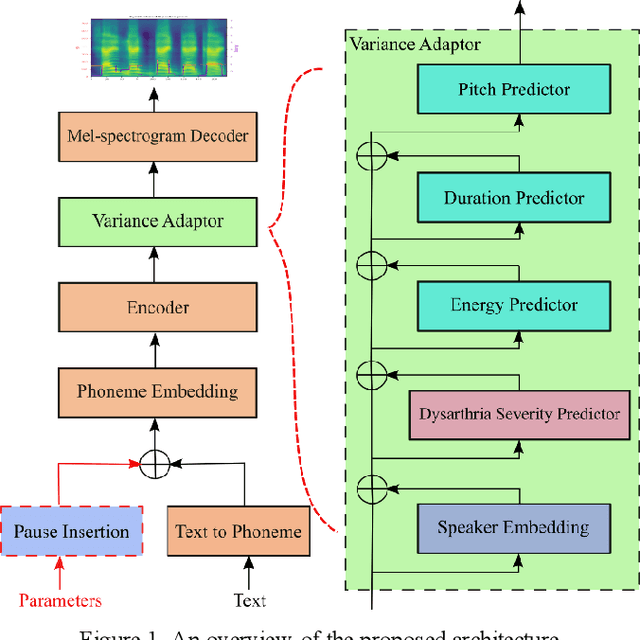
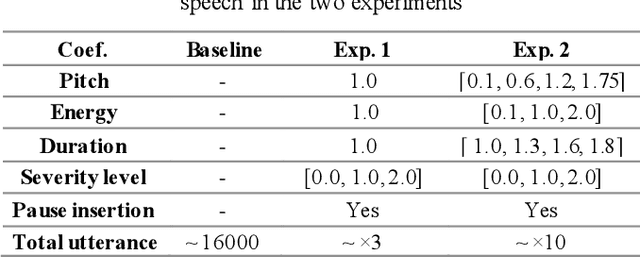
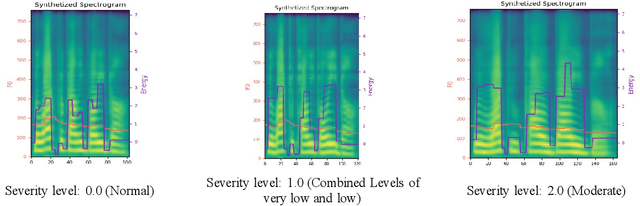
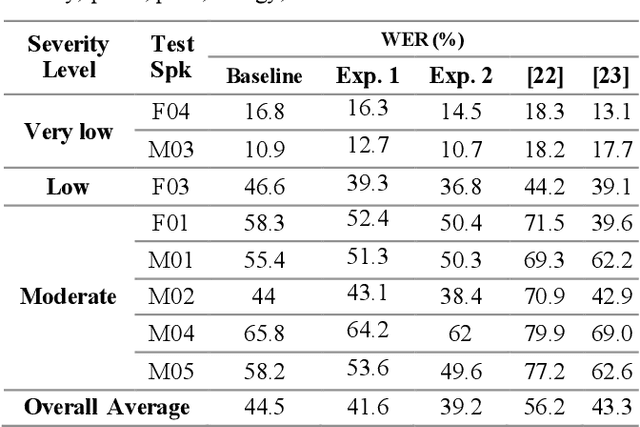
Dysarthria is a motor speech disorder often characterized by reduced speech intelligibility through slow, uncoordinated control of speech production muscles. Automatic Speech recognition (ASR) systems may help dysarthric talkers communicate more effectively. To have robust dysarthria-specific ASR, sufficient training speech is required, which is not readily available. Recent advances in Text-To-Speech (TTS) synthesis multi-speaker end-to-end TTS systems suggest the possibility of using synthesis for data augmentation. In this paper, we aim to improve multi-speaker end-to-end TTS systems to synthesize dysarthric speech for improved training of a dysarthria-specific DNN-HMM ASR. In the synthesized speech, we add dysarthria severity level and pause insertion mechanisms to other control parameters such as pitch, energy, and duration. Results show that a DNN-HMM model trained on additional synthetic dysarthric speech achieves WER improvement of 12.2% compared to the baseline, the addition of the severity level and pause insertion controls decrease WER by 6.5%, showing the effectiveness of adding these parameters. Audio samples are available at