 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilingual Streaming ASR with Grapheme units and Auxiliary Monolingual Loss
Aug 11, 2023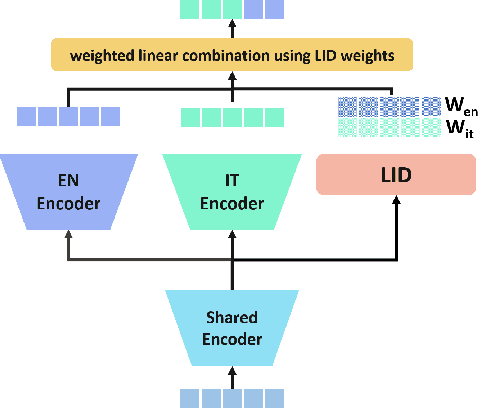


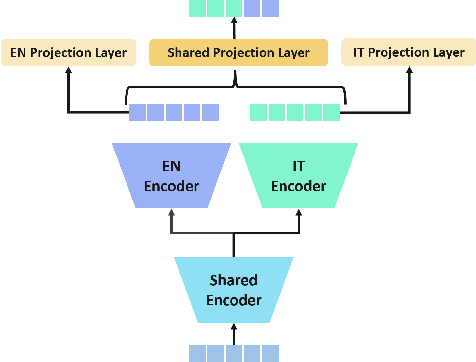
We introduce a bilingual solution to support English as secondary locale for most primary locales in hybrid automatic speech recognition (ASR) settings. Our key developments constitute: (a) pronunciation lexicon with grapheme units instead of phone units, (b) a fully bilingual alignment model and subsequently bilingual streaming transformer model, (c) a parallel encoder structure with language identification (LID) loss, (d) parallel encoder with an auxiliary loss for monolingual projections. We conclude that in comparison to LID loss, our proposed auxiliary loss is superior in specializing the parallel encoders to respective monolingual locales, and that contributes to stronger bilingual learning. We evaluate our work on large-scale training and test tasks for bilingual Spanish (ES) and bilingual Italian (IT) applications. Our bilingual models demonstrate strong English code-mixing capability. In particular, the bilingual IT model improves the word error rate (WER) for a code-mix IT task from 46.5% to 13.8%, while also achieving a close parity (9.6%) with the monolingual IT model (9.5%) over IT tests.
A Unified Framework for Speech Separation
Dec 17, 2019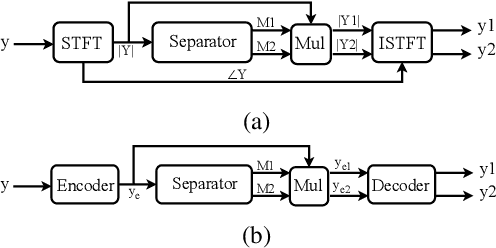
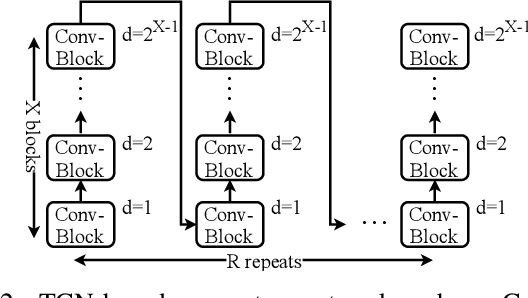
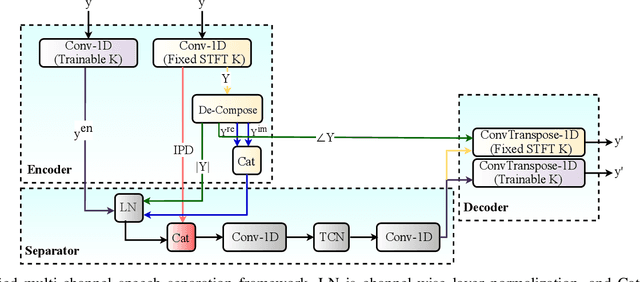
Speech separation refers to extracting each individual speech source in a given mixed signal. Recent advancements in speech separation and ongoing research in this area, have made these approaches as promising techniques for pre-processing of naturalistic audio streams. After incorporating deep learning techniques into speech separation, performance on these systems is improving faster. The initial solutions introduced for deep learning based speech separation analyzed the speech signals into time-frequency domain with STFT; and then encoded mixed signals were fed into a deep neural network based separator. Most recently, new methods are introduced to separate waveform of the mixed signal directly without analyzing them using STFT. Here, we introduce a unified framework to include both spectrogram and waveform separations into a single structure, while being only different in the kernel function used to encode and decode the data; where, both can achieve competitive performance. This new framework provides flexibility; in addition, depending on the characteristics of the data, or limitations of the memory and latency can set the hyper-parameters to flow in a pipeline of the framework which fits the task properly. We extend single-channel speech separation into multi-channel framework with end-to-end training of the network while optimizing the speech separation criterion (i.e., Si-SNR) directly. We emphasize on how tied kernel functions for calculating spatial features, encoder, and decoder in multi-channel framework can be effective. We simulate spatialized reverberate data for both WSJ0 and LibriSpeech corpora here, and while these two sets of data are different in the matter of size and duration, the effect of capturing shorter and longer dependencies of previous/+future samples are studied in detail. We report SDR, Si-SNR and PESQ to evaluate the performance of developed solutions.
A comprehensive study of speech separation: spectrogram vs waveform separation
May 17, 2019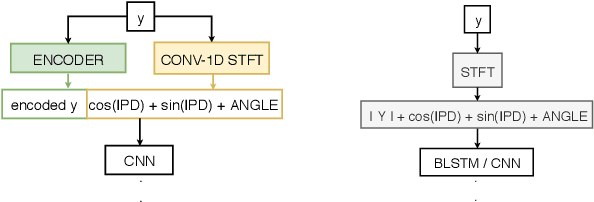

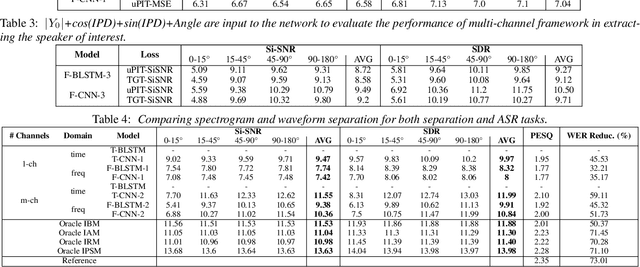
Speech separation has been studied widely for single-channel close-talk recordings over the past few years; developed solutions are mostly in frequency-domain. Recently, a raw audio waveform separation network (TasNet) introduced for single-channel data, with achieving high Si-SNR (scale-invariant source-to-noise ratio) and SDR (source-to-distortion ratio) comparing against the state-of-the-art solution in frequency-domain. In this study, we incorporate effective components of TasNet into a frequency-domain separation method. We compare both for alternative scenarios. We introduce a solution for directly optimizing the separation criterion in frequency-domain networks. In addition to speech separation objective and subjective measurements, we evaluate the separation performance on a speech recognition task as well. We study the speech separation problem for far-filed data (more similar to naturalistic audio streams) and develop multi-channel solutions for both frequency and time-domain separators with utilizing spectral, spatial and speaker location information. For our experiments, we simulated multi-channel spatialized reverberate WSJ0-2mix dataset. Our experimental results show that spectrogram separation can achieve competitive performance with better network design. With multi-channel framework as well, we can obtain relatively up to +35.5% and +46% improvement in terms of WER and SDR, respectively.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019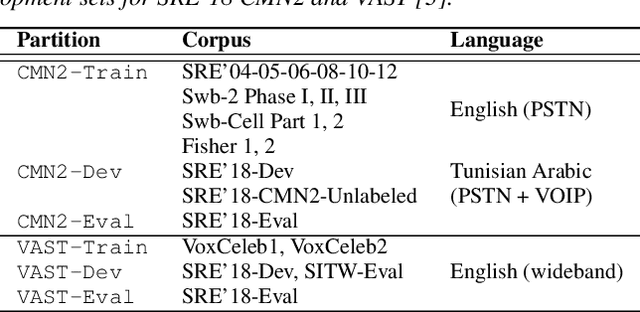
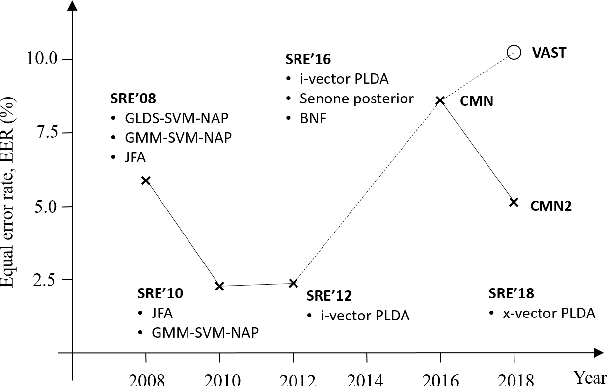
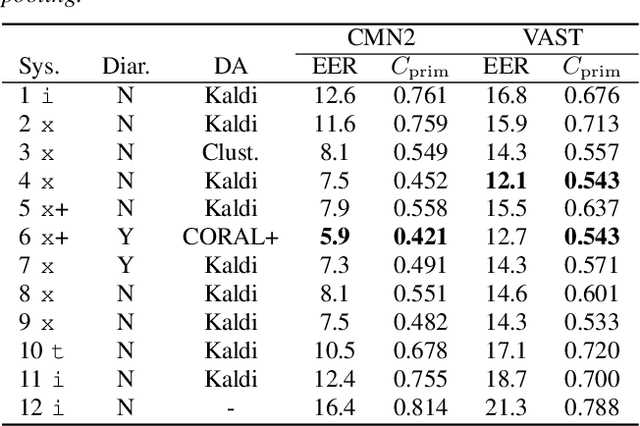
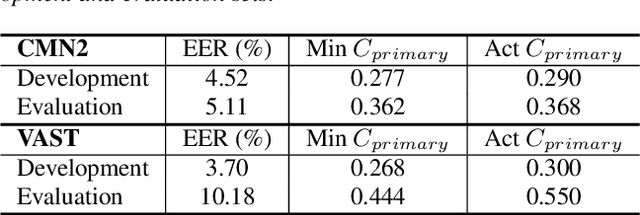
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
UTD-CRSS Systems for 2016 NIST Speaker Recognition Evaluation
Oct 24, 2016
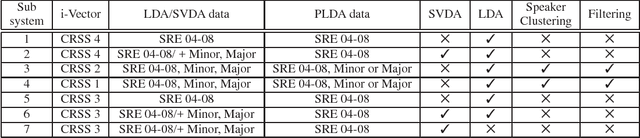
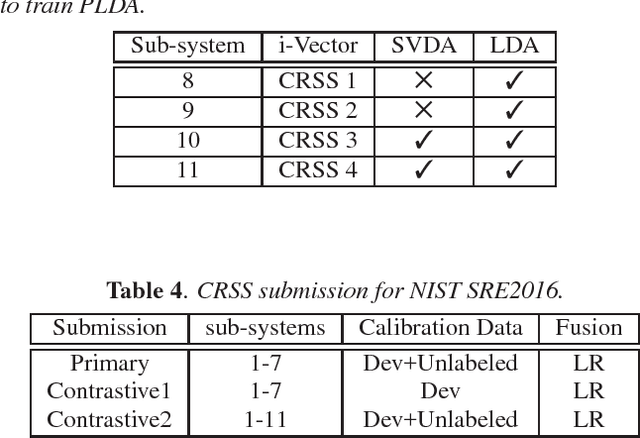
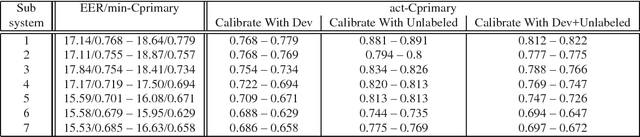
This document briefly describes the systems submitted by the Center for Robust Speech Systems (CRSS) from The University of Texas at Dallas (UTD) to the 2016 National Institute of Standards and Technology (NIST) Speaker Recognition Evaluation (SRE). We developed several UBM and DNN i-Vector based speaker recognition systems with different data sets and feature representations. Given that the emphasis of the NIST SRE 2016 is on language mismatch between training and enrollment/test data, so-called domain mismatch, in our system development we focused on: (1) using unlabeled in-domain data for centralizing data to alleviate the domain mismatch problem, (2) finding the best data set for training LDA/PLDA, (3) using newly proposed dimension reduction technique incorporating unlabeled in-domain data before PLDA training, (4) unsupervised speaker clustering of unlabeled data and using them alone or with previous SREs for PLDA training, (5) score calibration using only unlabeled data and combination of unlabeled and development (Dev) data as separate experiments.