 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilingual Streaming ASR with Grapheme units and Auxiliary Monolingual Loss
Aug 11, 2023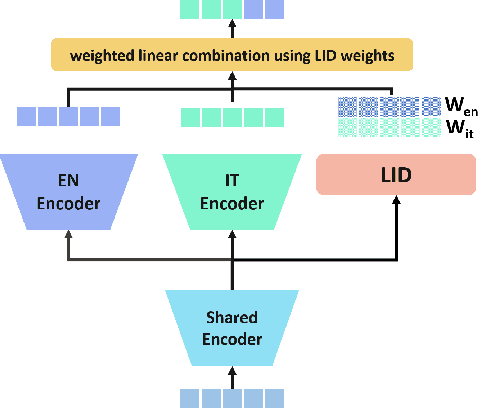


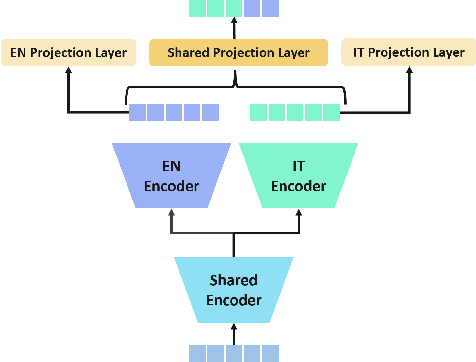
We introduce a bilingual solution to support English as secondary locale for most primary locales in hybrid automatic speech recognition (ASR) settings. Our key developments constitute: (a) pronunciation lexicon with grapheme units instead of phone units, (b) a fully bilingual alignment model and subsequently bilingual streaming transformer model, (c) a parallel encoder structure with language identification (LID) loss, (d) parallel encoder with an auxiliary loss for monolingual projections. We conclude that in comparison to LID loss, our proposed auxiliary loss is superior in specializing the parallel encoders to respective monolingual locales, and that contributes to stronger bilingual learning. We evaluate our work on large-scale training and test tasks for bilingual Spanish (ES) and bilingual Italian (IT) applications. Our bilingual models demonstrate strong English code-mixing capability. In particular, the bilingual IT model improves the word error rate (WER) for a code-mix IT task from 46.5% to 13.8%, while also achieving a close parity (9.6%) with the monolingual IT model (9.5%) over IT tests.
Maximizing Audio Event Detection Model Performance on Small Datasets Through Knowledge Transfer, Data Augmentation, And Pretraining: An Ablation Study
Feb 07, 2022
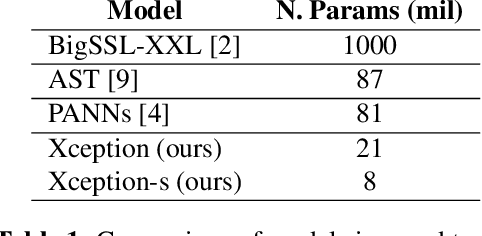
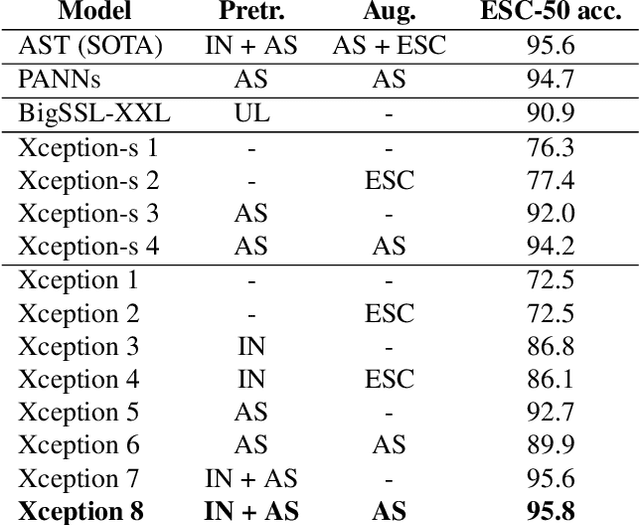

An Xception model reaches state-of-the-art (SOTA) accuracy on the ESC-50 dataset for audio event detection through knowledge transfer from ImageNet weights, pretraining on AudioSet, and an on-the-fly data augmentation pipeline. This paper presents an ablation study that analyzes which components contribute to the boost in performance and training time. A smaller Xception model is also presented which nears SOTA performance with almost a third of the parameters.
Sequence-level Confidence Classifier for ASR Utterance Accuracy and Application to Acoustic Models
Jun 30, 2021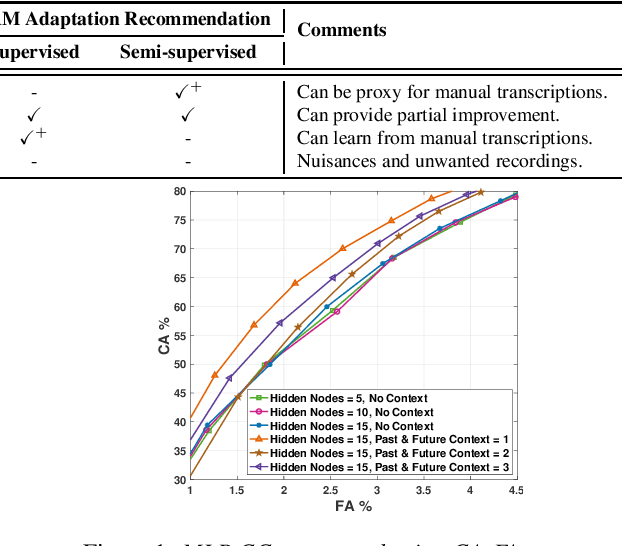
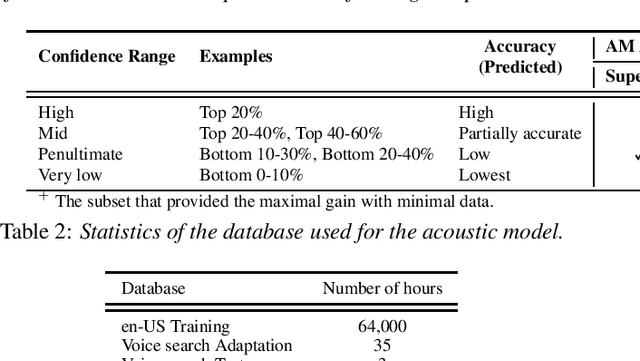
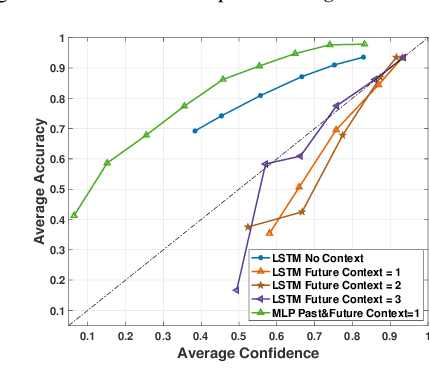

Scores from traditional confidence classifiers (CCs) in automatic speech recognition (ASR) systems lack universal interpretation and vary with updates to the underlying confidence or acoustic models (AMs). In this work, we build interpretable confidence scores with an objective to closely align with ASR accuracy. We propose a new sequence-level CC with a richer context providing CC scores highly correlated with ASR accuracy and scores stable across CC updates. Hence, expanding CC applications. Recently, AM customization has gained traction with the widespread use of unified models. Conventional adaptation strategies that customize AM expect well-matched data for the target domain with gold-standard transcriptions. We propose a cost-effective method of using CC scores to select an optimal adaptation data set, where we maximize ASR gains from minimal data. We study data in various confidence ranges and optimally choose data for AM adaptation with KL-Divergence regularization. On the Microsoft voice search task, data selection for supervised adaptation using the sequence-level confidence scores achieves word error rate reduction (WERR) of 8.5% for row-convolution LSTM (RC-LSTM) and 5.2% for latency-controlled bidirectional LSTM (LC-BLSTM). In the semi-supervised case, with ASR hypotheses as labels, our method provides WERR of 5.9% and 2.8% for RC-LSTM and LC-BLSTM, respectively.
Transfer Learning Approaches for Streaming End-to-End Speech Recognition System
Aug 17, 2020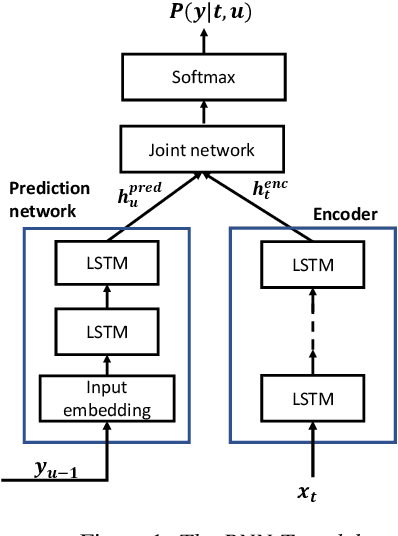
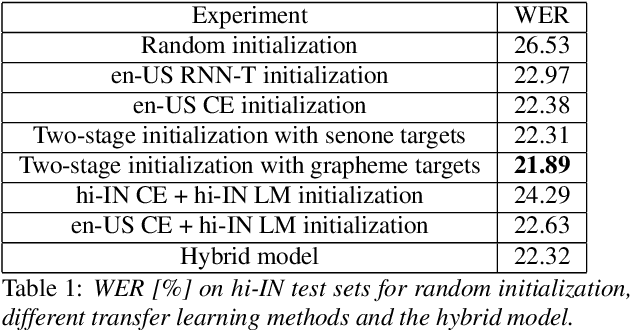
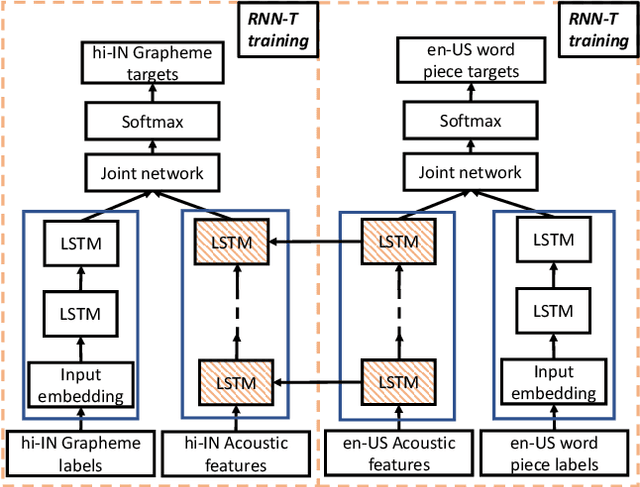
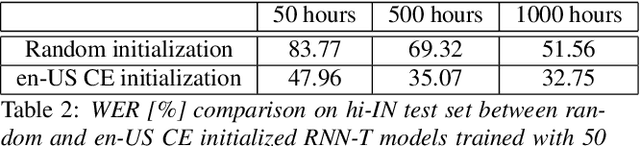
Transfer learning (TL) is widely used in conventional hybrid automatic speech recognition (ASR) system, to transfer the knowledge from source to target language. TL can be applied to end-to-end (E2E) ASR system such as recurrent neural network transducer (RNN-T) models, by initializing the encoder and/or prediction network of the target language with the pre-trained models from source language. In the hybrid ASR system, transfer learning is typically done by initializing the target language acoustic model (AM) with source language AM. Several transfer learning strategies exist in the case of the RNN-T framework, depending upon the choice of the initialization model for encoder and prediction networks. This paper presents a comparative study of four different TL methods for RNN-T framework. We show 17% relative word error rate reduction with different TL methods over randomly initialized RNN-T model. We also study the impact of TL with varying amount of training data ranging from 50 hours to 1000 hours and show the efficacy of TL for languages with small amount of training data.
Speaker Adaptation for End-to-End CTC Models
Jan 04, 2019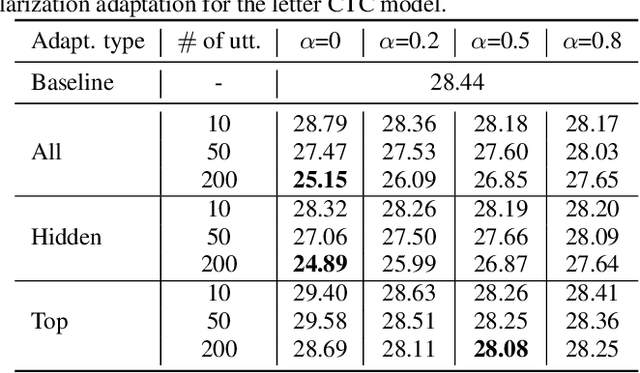
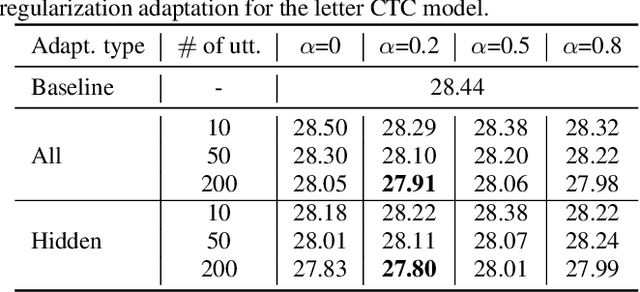
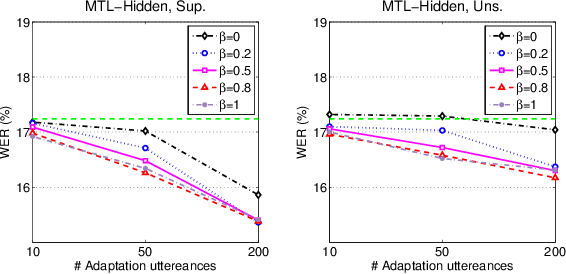
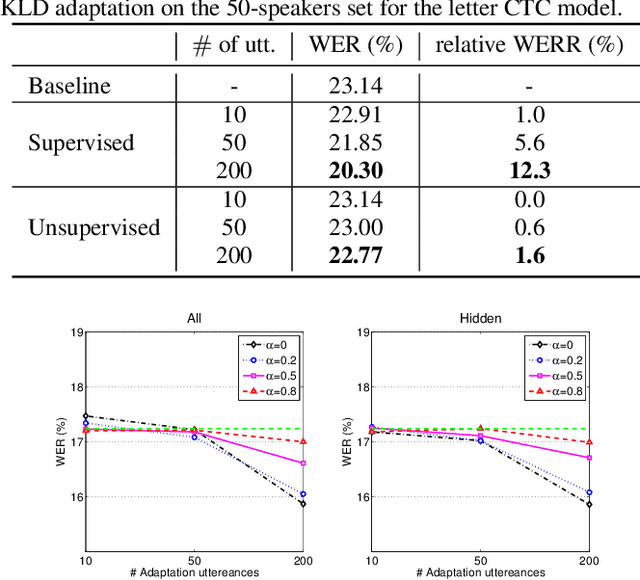
We propose two approaches for speaker adaptation in end-to-end (E2E) automatic speech recognition systems. One is Kullback-Leibler divergence (KLD) regularization and the other is multi-task learning (MTL). Both approaches aim to address the data sparsity especially output target sparsity issue of speaker adaptation in E2E systems. The KLD regularization adapts a model by forcing the output distribution from the adapted model to be close to the unadapted one. The MTL utilizes a jointly trained auxiliary task to improve the performance of the main task. We investigated our approaches on E2E connectionist temporal classification (CTC) models with three different types of output units. Experiments on the Microsoft short message dictation task demonstrated that MTL outperforms KLD regularization. In particular, the MTL adaptation obtained 8.8\% and 4.0\% relative word error rate reductions (WERRs) for supervised and unsupervised adaptations for the word CTC model, and 9.6% and 3.8% relative WERRs for the mix-unit CTC model, respectively.