 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Adaptation for End-to-End CTC Models
Paper and Code
Jan 04, 2019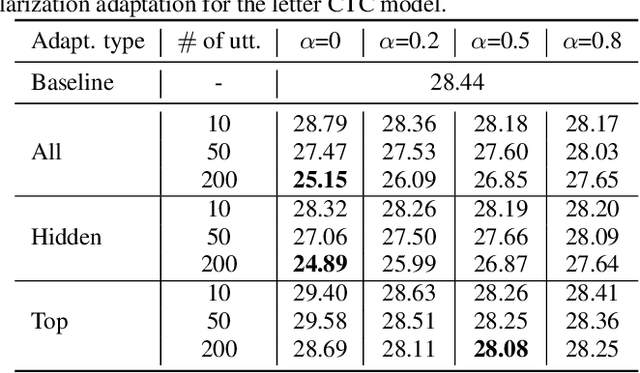
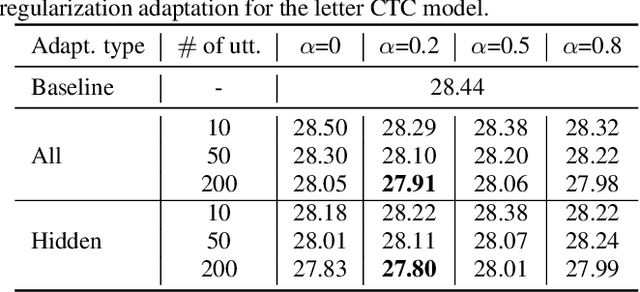
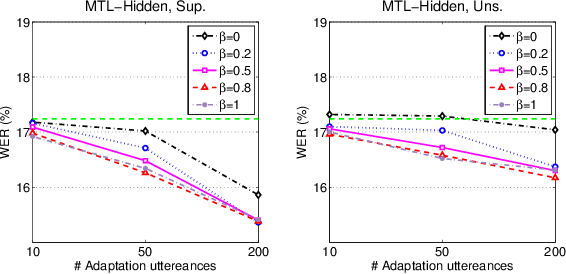
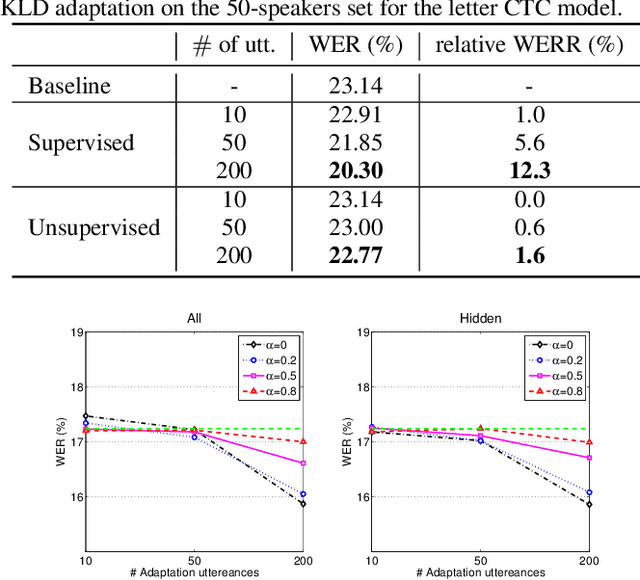
We propose two approaches for speaker adaptation in end-to-end (E2E) automatic speech recognition systems. One is Kullback-Leibler divergence (KLD) regularization and the other is multi-task learning (MTL). Both approaches aim to address the data sparsity especially output target sparsity issue of speaker adaptation in E2E systems. The KLD regularization adapts a model by forcing the output distribution from the adapted model to be close to the unadapted one. The MTL utilizes a jointly trained auxiliary task to improve the performance of the main task. We investigated our approaches on E2E connectionist temporal classification (CTC) models with three different types of output units. Experiments on the Microsoft short message dictation task demonstrated that MTL outperforms KLD regularization. In particular, the MTL adaptation obtained 8.8\% and 4.0\% relative word error rate reductions (WERRs) for supervised and unsupervised adaptations for the word CTC model, and 9.6% and 3.8% relative WERRs for the mix-unit CTC model, respectively.