 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaugh Now Cry Later: Controlling Time-Varying Emotional States of Flow-Matching-Based Zero-Shot Text-to-Speech
Jul 17, 2024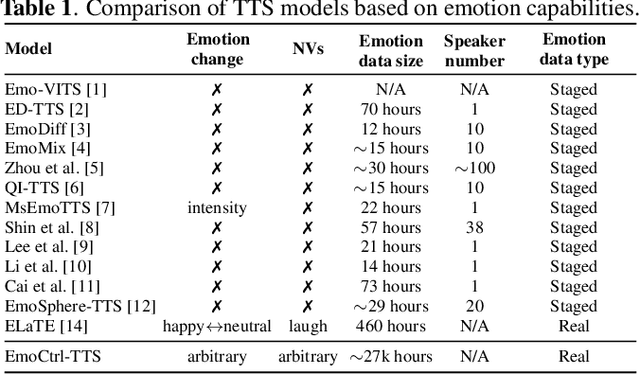
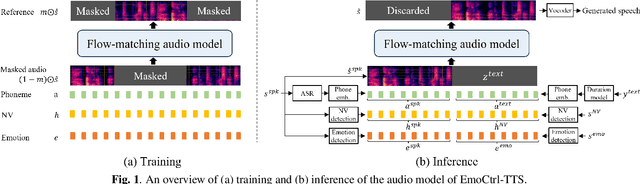
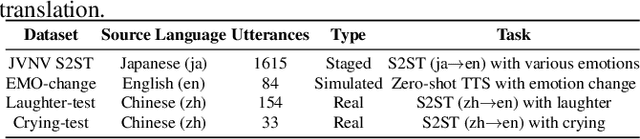
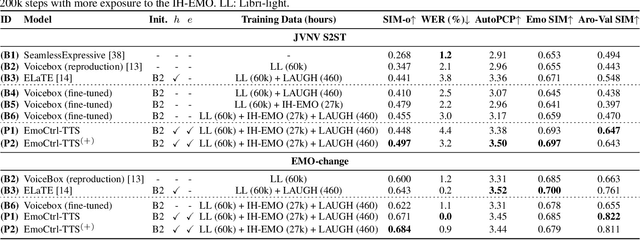
People change their tones of voice, often accompanied by nonverbal vocalizations (NVs) such as laughter and cries, to convey rich emotions. However, most text-to-speech (TTS) systems lack the capability to generate speech with rich emotions, including NVs. This paper introduces EmoCtrl-TTS, an emotion-controllable zero-shot TTS that can generate highly emotional speech with NVs for any speaker. EmoCtrl-TTS leverages arousal and valence values, as well as laughter embeddings, to condition the flow-matching-based zero-shot TTS. To achieve high-quality emotional speech generation, EmoCtrl-TTS is trained using more than 27,000 hours of expressive data curated based on pseudo-labeling. Comprehensive evaluations demonstrate that EmoCtrl-TTS excels in mimicking the emotions of audio prompts in speech-to-speech translation scenarios. We also show that EmoCtrl-TTS can capture emotion changes, express strong emotions, and generate various NVs in zero-shot TTS. See https://aka.ms/emoctrl-tts for demo samples.
BEATs: Audio Pre-Training with Acoustic Tokenizers
Dec 18, 2022The massive growth of self-supervised learning (SSL) has been witnessed in language, vision, speech, and audio domains over the past few years. While discrete label prediction is widely adopted for other modalities, the state-of-the-art audio SSL models still employ reconstruction loss for pre-training. Compared with reconstruction loss, semantic-rich discrete label prediction encourages the SSL model to abstract the high-level audio semantics and discard the redundant details as in human perception. However, a semantic-rich acoustic tokenizer for general audio pre-training is usually not straightforward to obtain, due to the continuous property of audio and unavailable phoneme sequences like speech. To tackle this challenge, we propose BEATs, an iterative audio pre-training framework to learn Bidirectional Encoder representation from Audio Transformers, where an acoustic tokenizer and an audio SSL model are optimized by iterations. In the first iteration, we use random projection as the acoustic tokenizer to train an audio SSL model in a mask and label prediction manner. Then, we train an acoustic tokenizer for the next iteration by distilling the semantic knowledge from the pre-trained or fine-tuned audio SSL model. The iteration is repeated with the hope of mutual promotion of the acoustic tokenizer and audio SSL model. The experimental results demonstrate our acoustic tokenizers can generate discrete labels with rich audio semantics and our audio SSL models achieve state-of-the-art results across various audio classification benchmarks, even outperforming previous models that use more training data and model parameters significantly. Specifically, we set a new state-of-the-art mAP 50.6% on AudioSet-2M for audio-only models without using any external data, and 98.1% accuracy on ESC-50. The code and pre-trained models are available at https://aka.ms/beats.
Maximizing Audio Event Detection Model Performance on Small Datasets Through Knowledge Transfer, Data Augmentation, And Pretraining: An Ablation Study
Feb 07, 2022
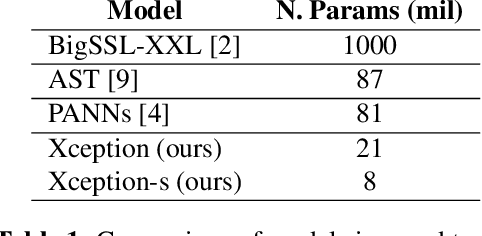
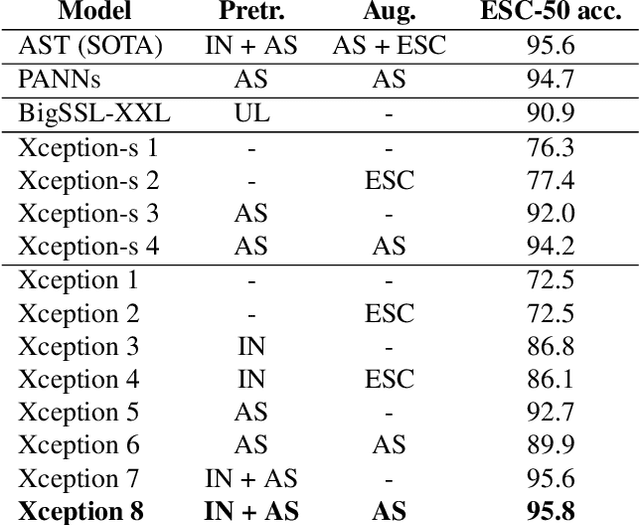

An Xception model reaches state-of-the-art (SOTA) accuracy on the ESC-50 dataset for audio event detection through knowledge transfer from ImageNet weights, pretraining on AudioSet, and an on-the-fly data augmentation pipeline. This paper presents an ablation study that analyzes which components contribute to the boost in performance and training time. A smaller Xception model is also presented which nears SOTA performance with almost a third of the parameters.
COVID-19 Detection Using Recorded Coughs in the 2021 DiCOVA Challenge
May 22, 2021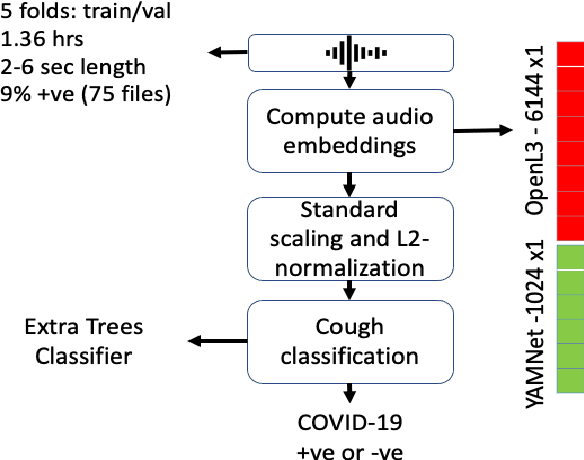
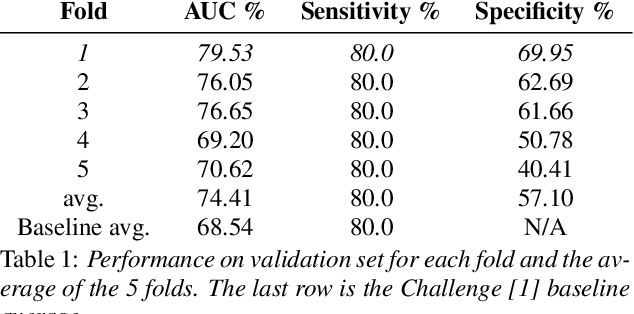

COVID-19 has resulted in over 100 million infections and caused worldwide lock downs due to its high transmission rate and limited testing options. Current diagnostic tests can be expensive, limited in availability, time-intensive and require risky in-person appointments. It has been established that symptomatic COVID-19 seriously impairs normal functioning of the respiratory system, thus affecting the coughing acoustics. The 2021 DiCOVA Challenge @ INTERSPEECH was designed to find scientific and engineering insights to the question by enabling participants to analyze an acoustic dataset gathered from COVID-19 positive and non-COVID-19 individuals. In this report we describe our participation in the Challenge (Track 1). We achieved 82.37% AUC ROC on the blind test outperforming the Challenge's baseline of 69.85%.
Multi-label Sound Event Retrieval Using a Deep Learning-based Siamese Structure with a Pairwise Presence Matrix
Feb 20, 2020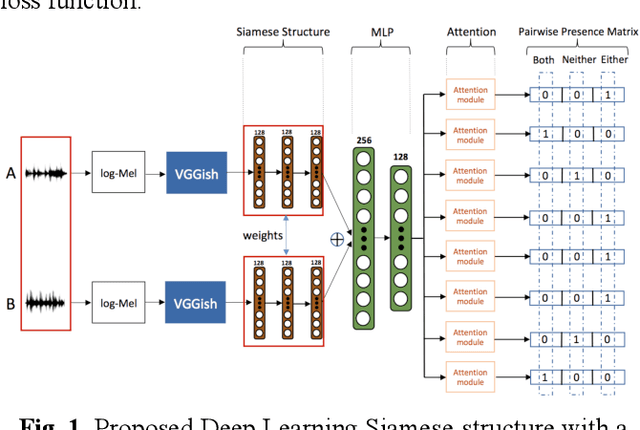
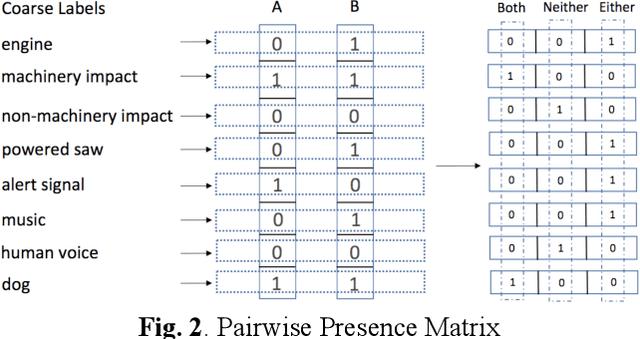
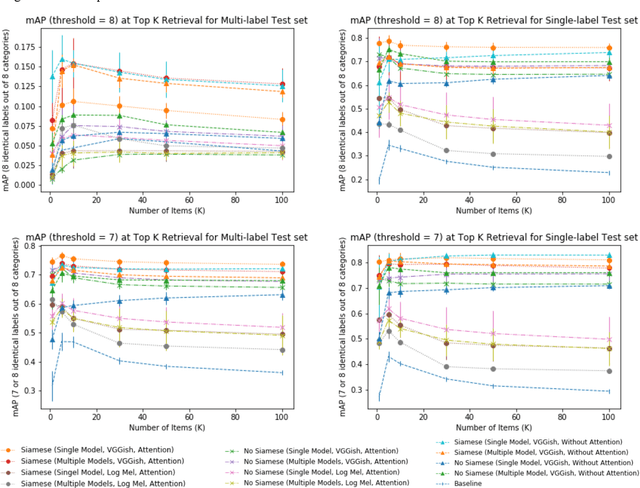
Realistic recordings of soundscapes often have multiple sound events co-occurring, such as car horns, engine and human voices. Sound event retrieval is a type of content-based search aiming at finding audio samples, similar to an audio query based on their acoustic or semantic content. State of the art sound event retrieval models have focused on single-label audio recordings, with only one sound event occurring, rather than on multi-label audio recordings (i.e., multiple sound events occur in one recording). To address this latter problem, we propose different Deep Learning architectures with a Siamese-structure and a Pairwise Presence Matrix. The networks are trained and evaluated using the SONYC-UST dataset containing both single- and multi-label soundscape recordings. The performance results show the effectiveness of our proposed model.