 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDTalk: Structured Facial Priors and Dual-Branch Motion Fields for Generalizable Gaussian Talking Head Synthesis
May 11, 2026High-quality, real-time talking head synthesis remains a fundamental challenge in computer vision. Existing reconstruction- and rendering-based methods typically rely on identity-specific models, limiting cross-identity generalization. To address this issue, we propose SDTalk, a one-shot 3D Gaussian Splatting (3DGS)-based framework that generalizes to unseen identities without personalized training or fine-tuning. Our framework comprises two modules with a two-stage training strategy. In the first stage, we incorporate structured facial priors into the reconstruction module and separately predict 3DGS parameters for visible and occluded regions, enabling complete head reconstruction from a single image. In the second stage, we introduce a dual-branch motion field to model coarse and fine facial dynamics, improving detail fidelity and lip synchronization. Experiments demonstrate that SDTalk surpasses existing methods in both visual quality and inference efficiency.
Sub-Footprint Effect Correction in FW-LiDAR Point Clouds via Intra-Footprint Target Unmixing
May 11, 2026Sub-footprint target mixing within a laser footprint significantly increases LiDAR intensity uncertainty, especially in complex environments where heterogeneous materials inside one footprint cause nonlinear distortions that impair intensity-based applications. However, the forward mixing inherent to the single-pixel detection mode of LiDAR systems blurs sub-footprint contributions, making sub-footprint effects difficult to address effectively in existing studies. To address this issue, we introduce a novel, physics-based framework that explicitly resolves sub-footprint intensity correction in full-waveform LiDAR (FW-LiDAR) point clouds. The key innovation is to make the otherwise implicit intra-footprint mixing process explicit: we first develop a spatiotemporal laser-beam distribution model to physically characterize within-footprint forward mixing of multi-target returns. Building on this formulation, we incorporate ancillary information including waveform parameters and surface geometry as constraints to pose a well-defined inverse unmixing problem and decompose each footprint into fractional contributions from multiple sub-targets. We then recover sub-footprint-corrected intensities by inverting the observed mixtures through a unified combination of parametric and model-driven approaches. To the best of our knowledge, few prior studies explicitly establish sub-footprint inversion and correction within a single laser footprint, and our framework offers a principled, physics-grounded solution. Experiments on both controlled and real-world LiDAR datasets demonstrate that the proposed method significantly enhances semantic separability across heterogeneous targets and intensity consistency across homogeneous targets.
FlowScene: Style-Consistent Indoor Scene Generation with Multimodal Graph Rectified Flow
Mar 20, 2026Scene generation has extensive industrial applications, demanding both high realism and precise control over geometry and appearance. Language-driven retrieval methods compose plausible scenes from a large object database, but overlook object-level control and often fail to enforce scene-level style coherence. Graph-based formulations offer higher controllability over objects and inform holistic consistency by explicitly modeling relations, yet existing methods struggle to produce high-fidelity textured results, thereby limiting their practical utility. We present FlowScene, a tri-branch scene generative model conditioned on multimodal graphs that collaboratively generates scene layouts, object shapes, and object textures. At its core lies a tight-coupled rectified flow model that exchanges object information during generation, enabling collaborative reasoning across the graph. This enables fine-grained control of objects' shapes, textures, and relations while enforcing scene-level style coherence across structure and appearance. Extensive experiments show that FlowScene outperforms both language-conditioned and graph-conditioned baselines in terms of generation realism, style consistency, and alignment with human preferences.
DARA: Few-shot Budget Allocation in Online Advertising via In-Context Decision Making with RL-Finetuned LLMs
Jan 21, 2026Optimizing the advertiser's cumulative value of winning impressions under budget constraints poses a complex challenge in online advertising, under the paradigm of AI-Generated Bidding (AIGB). Advertisers often have personalized objectives but limited historical interaction data, resulting in few-shot scenarios where traditional reinforcement learning (RL) methods struggle to perform effectively. Large Language Models (LLMs) offer a promising alternative for AIGB by leveraging their in-context learning capabilities to generalize from limited data. However, they lack the numerical precision required for fine-grained optimization. To address this limitation, we introduce GRPO-Adaptive, an efficient LLM post-training strategy that enhances both reasoning and numerical precision by dynamically updating the reference policy during training. Built upon this foundation, we further propose DARA, a novel dual-phase framework that decomposes the decision-making process into two stages: a few-shot reasoner that generates initial plans via in-context prompting, and a fine-grained optimizer that refines these plans using feedback-driven reasoning. This separation allows DARA to combine LLMs' in-context learning strengths with precise adaptability required by AIGB tasks. Extensive experiments on both real-world and synthetic data environments demonstrate that our approach consistently outperforms existing baselines in terms of cumulative advertiser value under budget constraints.
Genie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Jan 05, 2026The development of robust and generalizable robot learning models is critically contingent upon the availability of large-scale, diverse training data and reliable evaluation benchmarks. Collecting data in the physical world poses prohibitive costs and scalability challenges, and prevailing simulation benchmarks frequently suffer from fragmentation, narrow scope, or insufficient fidelity to enable effective sim-to-real transfer. To address these challenges, we introduce Genie Sim 3.0, a unified simulation platform for robotic manipulation. We present Genie Sim Generator, a large language model (LLM)-powered tool that constructs high-fidelity scenes from natural language instructions. Its principal strength resides in rapid and multi-dimensional generalization, facilitating the synthesis of diverse environments to support scalable data collection and robust policy evaluation. We introduce the first benchmark that pioneers the application of LLM for automated evaluation. It leverages LLM to mass-generate evaluation scenarios and employs Vision-Language Model (VLM) to establish an automated assessment pipeline. We also release an open-source dataset comprising more than 10,000 hours of synthetic data across over 200 tasks. Through systematic experimentation, we validate the robust zero-shot sim-to-real transfer capability of our open-source dataset, demonstrating that synthetic data can server as an effective substitute for real-world data under controlled conditions for scalable policy training. For code and dataset details, please refer to: https://github.com/AgibotTech/genie_sim.
MMGDreamer: Mixed-Modality Graph for Geometry-Controllable 3D Indoor Scene Generation
Feb 09, 2025Controllable 3D scene generation has extensive applications in virtual reality and interior design, where the generated scenes should exhibit high levels of realism and controllability in terms of geometry. Scene graphs provide a suitable data representation that facilitates these applications. However, current graph-based methods for scene generation are constrained to text-based inputs and exhibit insufficient adaptability to flexible user inputs, hindering the ability to precisely control object geometry. To address this issue, we propose MMGDreamer, a dual-branch diffusion model for scene generation that incorporates a novel Mixed-Modality Graph, visual enhancement module, and relation predictor. The mixed-modality graph allows object nodes to integrate textual and visual modalities, with optional relationships between nodes. It enhances adaptability to flexible user inputs and enables meticulous control over the geometry of objects in the generated scenes. The visual enhancement module enriches the visual fidelity of text-only nodes by constructing visual representations using text embeddings. Furthermore, our relation predictor leverages node representations to infer absent relationships between nodes, resulting in more coherent scene layouts. Extensive experimental results demonstrate that MMGDreamer exhibits superior control of object geometry, achieving state-of-the-art scene generation performance. Project page: https://yangzhifeio.github.io/project/MMGDreamer.
Investigating Neural Audio Codecs for Speech Language Model-Based Speech Generation
Sep 06, 2024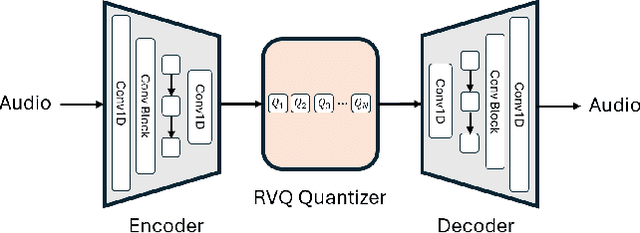

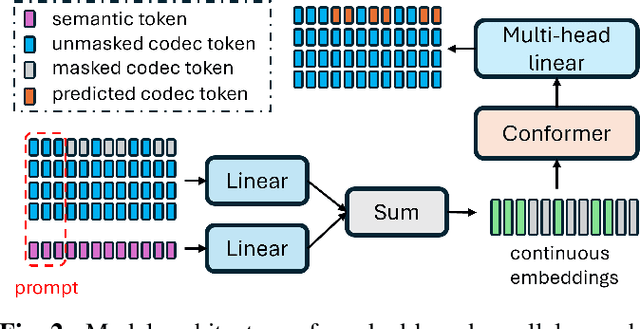
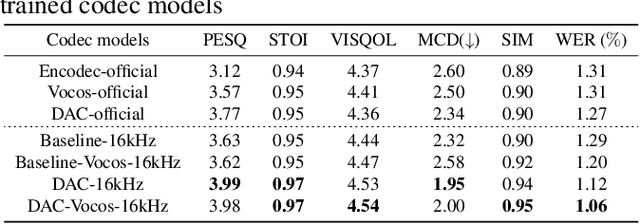
Neural audio codec tokens serve as the fundamental building blocks for speech language model (SLM)-based speech generation. However, there is no systematic understanding on how the codec system affects the speech generation performance of the SLM. In this work, we examine codec tokens within SLM framework for speech generation to provide insights for effective codec design. We retrain existing high-performing neural codec models on the same data set and loss functions to compare their performance in a uniform setting. We integrate codec tokens into two SLM systems: masked-based parallel speech generation system and an auto-regressive (AR) plus non-auto-regressive (NAR) model-based system. Our findings indicate that better speech reconstruction in codec systems does not guarantee improved speech generation in SLM. A high-quality codec decoder is crucial for natural speech production in SLM, while speech intelligibility depends more on quantization mechanism.
Exploring Robust Face-Voice Matching in Multilingual Environments
Jul 29, 2024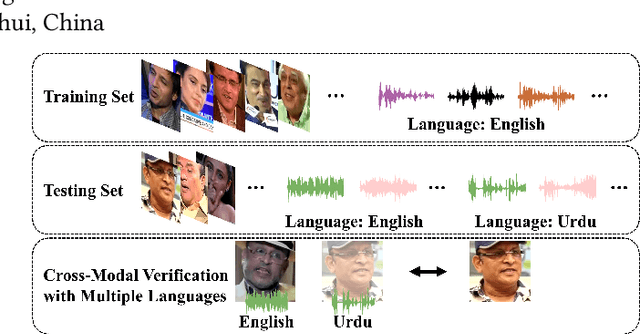



This paper presents Team Xaiofei's innovative approach to exploring Face-Voice Association in Multilingual Environments (FAME) at ACM Multimedia 2024. We focus on the impact of different languages in face-voice matching by building upon Fusion and Orthogonal Projection (FOP), introducing four key components: a dual-branch structure, dynamic sample pair weighting, robust data augmentation, and score polarization strategy. Our dual-branch structure serves as an auxiliary mechanism to better integrate and provide more comprehensive information. We also introduce a dynamic weighting mechanism for various sample pairs to optimize learning. Data augmentation techniques are employed to enhance the model's generalization across diverse conditions. Additionally, score polarization strategy based on age and gender matching confidence clarifies and accentuates the final results. Our methods demonstrate significant effectiveness, achieving an equal error rate (EER) of 20.07 on the V2-EH dataset and 21.76 on the V1-EU dataset.
Laugh Now Cry Later: Controlling Time-Varying Emotional States of Flow-Matching-Based Zero-Shot Text-to-Speech
Jul 17, 2024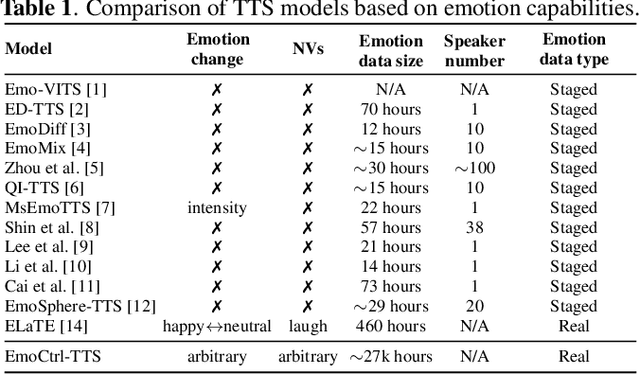
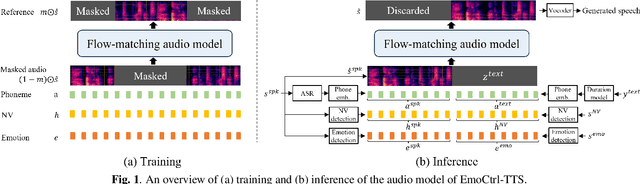
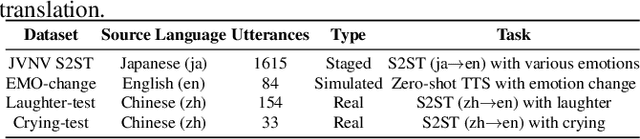
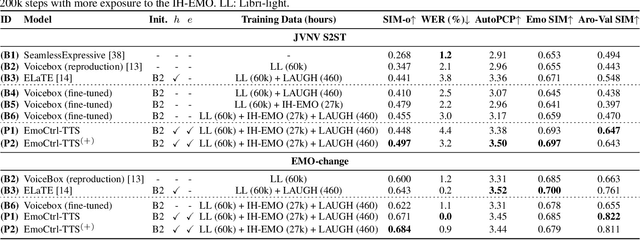
People change their tones of voice, often accompanied by nonverbal vocalizations (NVs) such as laughter and cries, to convey rich emotions. However, most text-to-speech (TTS) systems lack the capability to generate speech with rich emotions, including NVs. This paper introduces EmoCtrl-TTS, an emotion-controllable zero-shot TTS that can generate highly emotional speech with NVs for any speaker. EmoCtrl-TTS leverages arousal and valence values, as well as laughter embeddings, to condition the flow-matching-based zero-shot TTS. To achieve high-quality emotional speech generation, EmoCtrl-TTS is trained using more than 27,000 hours of expressive data curated based on pseudo-labeling. Comprehensive evaluations demonstrate that EmoCtrl-TTS excels in mimicking the emotions of audio prompts in speech-to-speech translation scenarios. We also show that EmoCtrl-TTS can capture emotion changes, express strong emotions, and generate various NVs in zero-shot TTS. See https://aka.ms/emoctrl-tts for demo samples.
E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS
Jun 26, 2024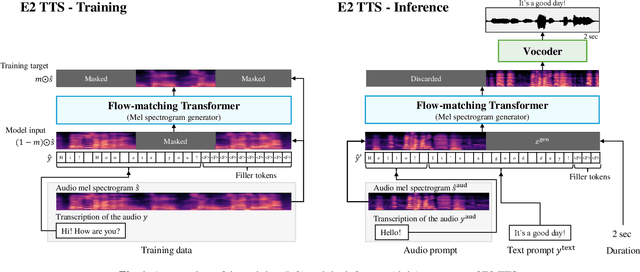
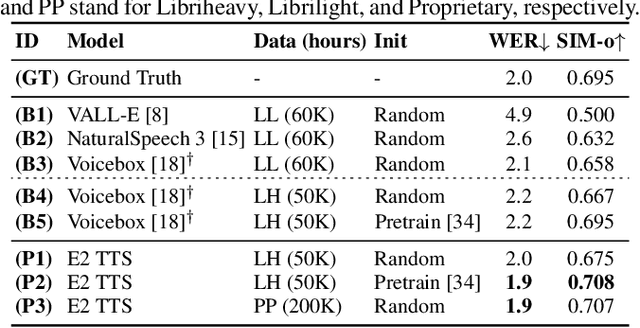
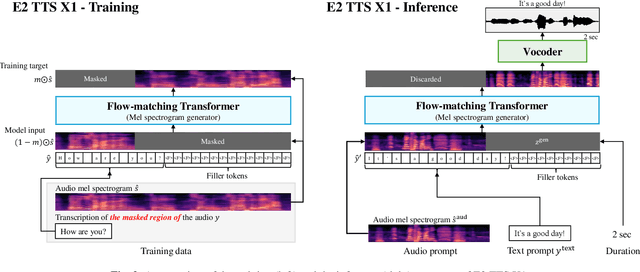
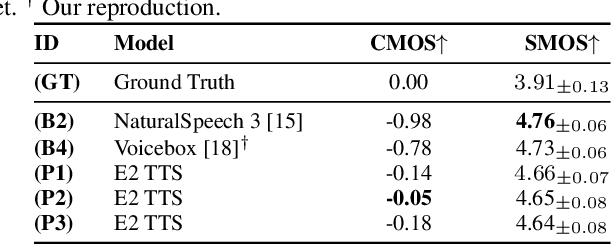
This paper introduces Embarrassingly Easy Text-to-Speech (E2 TTS), a fully non-autoregressive zero-shot text-to-speech system that offers human-level naturalness and state-of-the-art speaker similarity and intelligibility. In the E2 TTS framework, the text input is converted into a character sequence with filler tokens. The flow-matching-based mel spectrogram generator is then trained based on the audio infilling task. Unlike many previous works, it does not require additional components (e.g., duration model, grapheme-to-phoneme) or complex techniques (e.g., monotonic alignment search). Despite its simplicity, E2 TTS achieves state-of-the-art zero-shot TTS capabilities that are comparable to or surpass previous works, including Voicebox and NaturalSpeech 3. The simplicity of E2 TTS also allows for flexibility in the input representation. We propose several variants of E2 TTS to improve usability during inference. See https://aka.ms/e2tts/ for demo samples.