 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Neural Audio Codecs for Speech Language Model-Based Speech Generation
Paper and Code
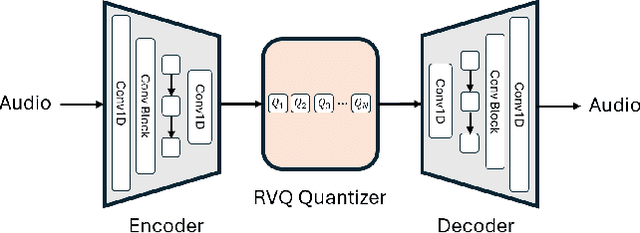

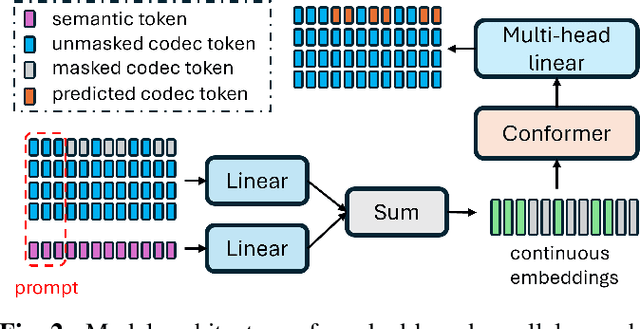
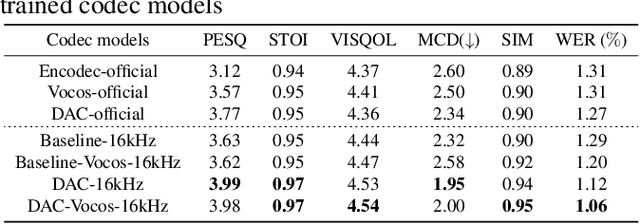
Neural audio codec tokens serve as the fundamental building blocks for speech language model (SLM)-based speech generation. However, there is no systematic understanding on how the codec system affects the speech generation performance of the SLM. In this work, we examine codec tokens within SLM framework for speech generation to provide insights for effective codec design. We retrain existing high-performing neural codec models on the same data set and loss functions to compare their performance in a uniform setting. We integrate codec tokens into two SLM systems: masked-based parallel speech generation system and an auto-regressive (AR) plus non-auto-regressive (NAR) model-based system. Our findings indicate that better speech reconstruction in codec systems does not guarantee improved speech generation in SLM. A high-quality codec decoder is crucial for natural speech production in SLM, while speech intelligibility depends more on quantization mechanism.